 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAudio-Visual Feature Synchronization for Robust Speech Enhancement in Hearing Aids
Aug 26, 2025Audio-visual feature synchronization for real-time speech enhancement in hearing aids represents a progressive approach to improving speech intelligibility and user experience, particularly in strong noisy backgrounds. This approach integrates auditory signals with visual cues, utilizing the complementary description of these modalities to improve speech intelligibility. Audio-visual feature synchronization for real-time SE in hearing aids can be further optimized using an efficient feature alignment module. In this study, a lightweight cross-attentional model learns robust audio-visual representations by exploiting large-scale data and simple architecture. By incorporating the lightweight cross-attentional model in an AVSE framework, the neural system dynamically emphasizes critical features across audio and visual modalities, enabling defined synchronization and improved speech intelligibility. The proposed AVSE model not only ensures high performance in noise suppression and feature alignment but also achieves real-time processing with minimal latency (36ms) and energy consumption. Evaluations on the AVSEC3 dataset show the efficiency of the model, achieving significant gains over baselines in perceptual quality (PESQ:0.52), intelligibility (STOI:19\%), and fidelity (SI-SDR:10.10dB).
Saying goodbyes to rotating your phone: Magnetometer calibration during SLAM
Sep 02, 2024



While Wi-Fi positioning is still more common indoors, using magnetic field features has become widely known and utilized as an alternative or supporting source of information. Magnetometer bias presents significant challenge in magnetic field navigation and SLAM. Traditionally, magnetometers have been calibrated using standard sphere or ellipsoid fitting methods and by requiring manual user procedures, such as rotating a smartphone in a figure-eight shape. This is not always feasible, particularly when the magnetometer is attached to heavy or fast-moving platforms, or when user behavior cannot be reliably controlled. Recent research has proposed using map data for calibration during positioning. This paper takes a step further and verifies that a pre-collected map is not needed; instead, calibration can be done as part of a SLAM process. The presented solution uses a factorized particle filter that factors out calibration in addition to the magnetic field map. The method is validated using smartphone data from a shopping mall and mobile robotics data from an office environment. Results support the claim that magnetometer calibration can be achieved during SLAM with comparable accuracy to manual calibration. Furthermore, the method seems to slightly improve manual calibration when used on top of it, suggesting potential for integrating various calibration approaches.
Unlocking the potential of two-point cells for energy-efficient training of deep nets
Oct 24, 2022Context-sensitive two-point layer 5 pyramidal cells (L5PC) were discovered as long ago as 1999. However, the potential of this discovery to provide useful neural computation has yet to be demonstrated. Here we show for the first time how a transformative L5PC-driven deep neural network (DNN), termed the multisensory cooperative computing (MCC) architecture, can effectively process large amounts of heterogeneous real-world audio-visual (AV) data, using far less energy compared to best available `point' neuron-driven DNNs. A novel highly-distributed parallel implementation on a Xilinx UltraScale+ MPSoC device estimates energy savings up to $245759 \times 50000$ $\mu$J (i.e., $62\%$ less than the baseline model in a semi-supervised learning setup) where a single synapse consumes $8e^{-5}\mu$J. In a supervised learning setup, the energy-saving can potentially reach up to 1250x less (per feedforward transmission) than the baseline model. This remarkable performance in pilot experiments demonstrates the embodied neuromorphic intelligence of our proposed L5PC based MCC architecture that contextually selects the most salient and relevant information for onward transmission, from overwhelmingly large multimodal information utilised at the early stages of on-chip training. Our proposed approach opens new cross-disciplinary avenues for future on-chip DNN training implementations and posits a radical shift in current neuromorphic computing paradigms.
Design of Flexible Meander Line Antenna for Healthcare for Wireless Medical Body Area Networks
Feb 08, 2022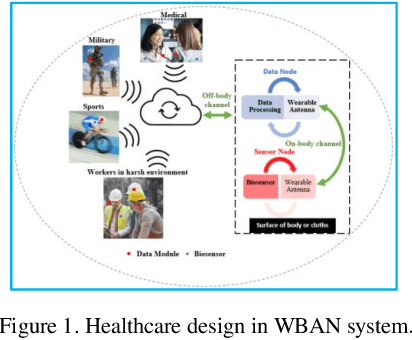
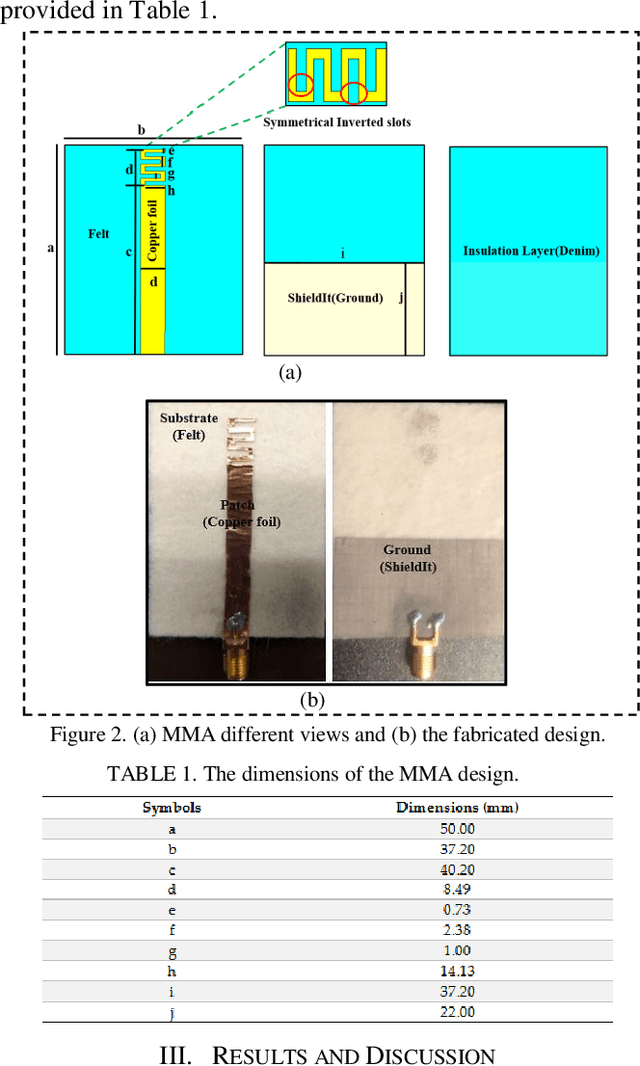
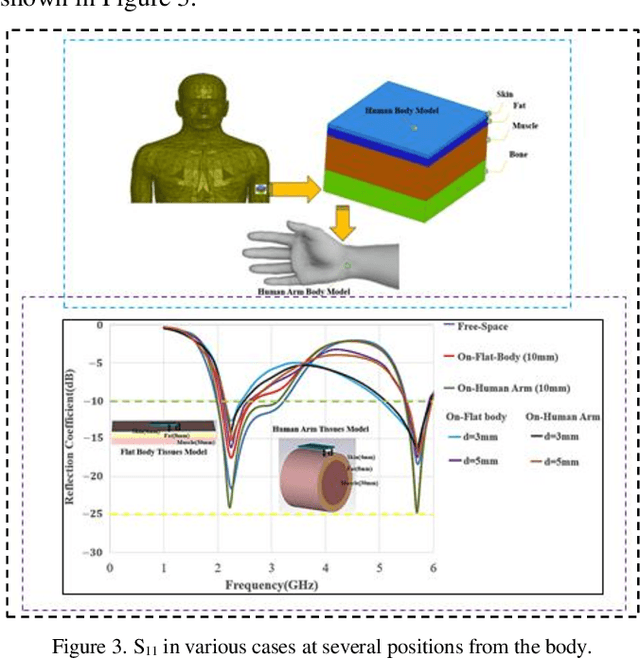
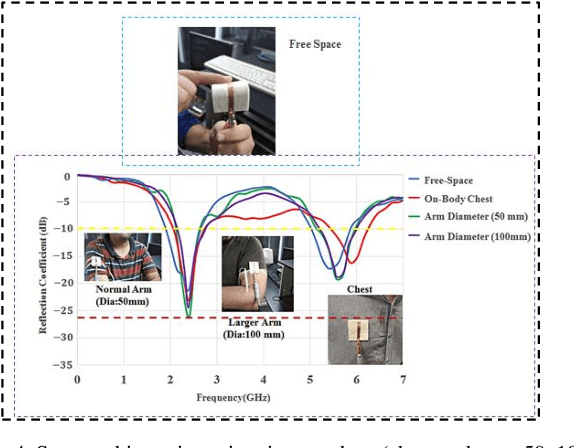
A flexible meander line monopole antenna (MMA) is presented in this paper. The antenna can be worn for on-and off-body applications. The overall dimension of the MMA is 37 mm x 50 mm x2.37 mm3. The MMA was manufactured and measured, and the results matched with simulation results. The MMA design shows a bandwidth of up to 1282.4 (450.5) MHz and provides gains of 3.03 (4.85) dBi in the lower and upper operating bands, respectively, showing omnidirectional radiation patterns in free space. While worn on the chest or arm, bandwidths as high as 688.9 (500.9) MHz and 1261.7 (524.2) MHz, and the gains of 3.80 (4.67) dBi and 3.00 (4.55) dBi were observed. The experimental measurements of the read range confirmed the results of the coverage range of up to 11 meters.
A Column Streaming-Based Convolution Engine and Mapping Algorithm for CNN-based Edge AI accelerators
Sep 15, 2021
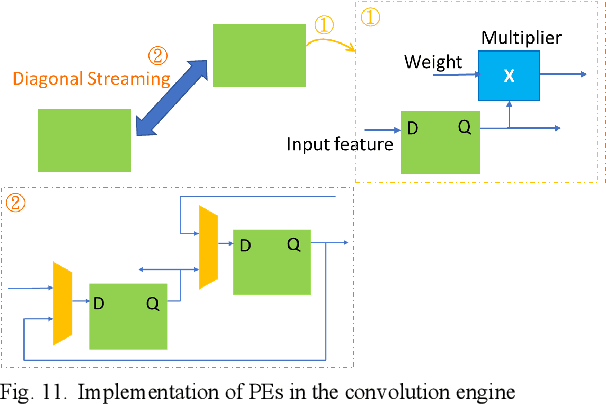
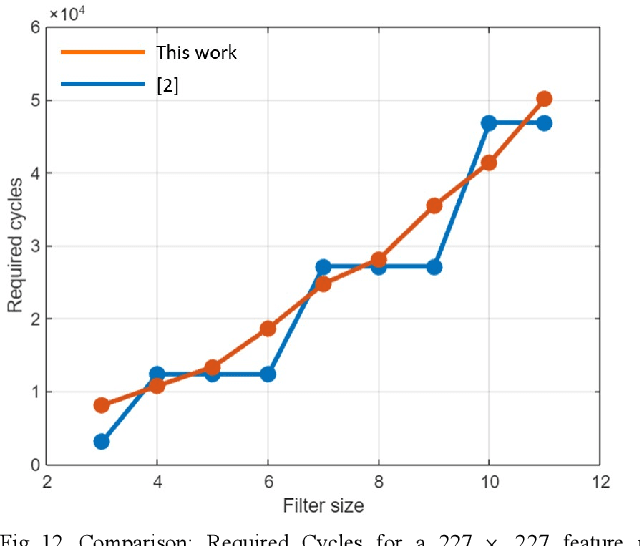
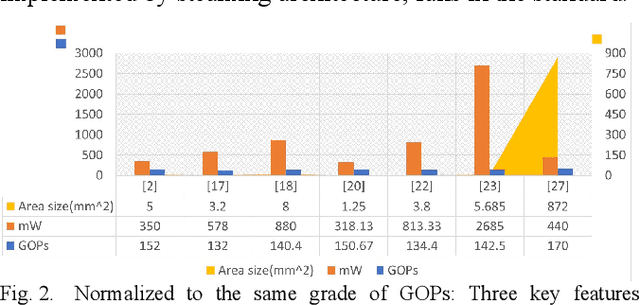
Edge AI accelerators have been emerging as a solution for near customers' applications in areas such as unmanned aerial vehicles (UAVs), image recognition sensors, wearable devices, robotics, and remote sensing satellites. These applications not only require meeting performance targets but also meeting strict area and power constraints due to their portable mobility feature and limited power sources. As a result, a column streaming-based convolution engine has been proposed in this paper that includes column sets of processing elements design for flexibility in terms of the applicability for different CNN algorithms in edge AI accelerators. Comparing to a commercialized CNN accelerator, the key results reveal that the column streaming-based convolution engine requires similar execution cycles for processing a 227 x 227 feature map with avoiding zero-padding penalties.