 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Build the Virtual Cell with Artificial Intelligence: Priorities and Opportunities
Sep 18, 2024

The cell is arguably the smallest unit of life and is central to understanding biology. Accurate modeling of cells is important for this understanding as well as for determining the root causes of disease. Recent advances in artificial intelligence (AI), combined with the ability to generate large-scale experimental data, present novel opportunities to model cells. Here we propose a vision of AI-powered Virtual Cells, where robust representations of cells and cellular systems under different conditions are directly learned from growing biological data across measurements and scales. We discuss desired capabilities of AI Virtual Cells, including generating universal representations of biological entities across scales, and facilitating interpretable in silico experiments to predict and understand their behavior using Virtual Instruments. We further address the challenges, opportunities and requirements to realize this vision including data needs, evaluation strategies, and community standards and engagement to ensure biological accuracy and broad utility. We envision a future where AI Virtual Cells help identify new drug targets, predict cellular responses to perturbations, as well as scale hypothesis exploration. With open science collaborations across the biomedical ecosystem that includes academia, philanthropy, and the biopharma and AI industries, a comprehensive predictive understanding of cell mechanisms and interactions is within reach.
The generator gradient estimator is an adjoint state method for stochastic differential equations
Jul 29, 2024Motivated by the increasing popularity of overparameterized Stochastic Differential Equations (SDEs) like Neural SDEs, Wang, Blanchet and Glynn recently introduced the generator gradient estimator, a novel unbiased stochastic gradient estimator for SDEs whose computation time remains stable in the number of parameters. In this note, we demonstrate that this estimator is in fact an adjoint state method, an approach which is known to scale with the number of states and not the number of parameters in the case of Ordinary Differential Equations (ODEs). In addition, we show that the generator gradient estimator is a close analogue to the exact Integral Path Algorithm (eIPA) estimator which was introduced by Gupta, Rathinam and Khammash for a class of Continuous-Time Markov Chains (CTMCs) known as stochastic chemical reactions networks (CRNs).
Exploring the limits of decoder-only models trained on public speech recognition corpora
Jan 31, 2024



The emergence of industrial-scale speech recognition (ASR) models such as Whisper and USM, trained on 1M hours of weakly labelled and 12M hours of audio only proprietary data respectively, has led to a stronger need for large scale public ASR corpora and competitive open source pipelines. Unlike the said models, large language models are typically based on Transformer decoders, and it remains unclear if decoder-only models trained on public data alone can deliver competitive performance. In this work, we investigate factors such as choice of training datasets and modeling components necessary for obtaining the best performance using public English ASR corpora alone. Our Decoder-Only Transformer for ASR (DOTA) model comprehensively outperforms the encoder-decoder open source replication of Whisper (OWSM) on nearly all English ASR benchmarks and outperforms Whisper large-v3 on 7 out of 15 test sets. We release our codebase and model checkpoints under permissive license.
Effective filtering approach for joint parameter-state estimation in SDEs via Rao-Blackwellization and modularization
Nov 01, 2023Stochastic filtering is a vibrant area of research in both control theory and statistics, with broad applications in many scientific fields. Despite its extensive historical development, there still lacks an effective method for joint parameter-state estimation in SDEs. The state-of-the-art particle filtering methods suffer from either sample degeneracy or information loss, with both issues stemming from the dynamics of the particles generated to represent system parameters. This paper provides a novel and effective approach for joint parameter-state estimation in SDEs via Rao-Blackwellization and modularization. Our method operates in two layers: the first layer estimates the system states using a bootstrap particle filter, and the second layer marginalizes out system parameters explicitly. This strategy circumvents the need to generate particles representing system parameters, thereby mitigating their associated problems of sample degeneracy and information loss. Moreover, our method employs a modularization approach when integrating out the parameters, which significantly reduces the computational complexity. All these designs ensure the superior performance of our method. Finally, a numerical example is presented to illustrate that our method outperforms existing approaches by a large margin.
Never Train from Scratch: Fair Comparison of Long-Sequence Models Requires Data-Driven Priors
Oct 04, 2023



Modeling long-range dependencies across sequences is a longstanding goal in machine learning and has led to architectures, such as state space models, that dramatically outperform Transformers on long sequences. However, these impressive empirical gains have been by and large demonstrated on benchmarks (e.g. Long Range Arena), where models are randomly initialized and trained to predict a target label from an input sequence. In this work, we show that random initialization leads to gross overestimation of the differences between architectures and that pretraining with standard denoising objectives, using $\textit{only the downstream task data}$, leads to dramatic gains across multiple architectures and to very small gaps between Transformers and state space models (SSMs). In stark contrast to prior works, we find vanilla Transformers to match the performance of S4 on Long Range Arena when properly pretrained, and we improve the best reported results of SSMs on the PathX-256 task by 20 absolute points. Subsequently, we analyze the utility of previously-proposed structured parameterizations for SSMs and show they become mostly redundant in the presence of data-driven initialization obtained through pretraining. Our work shows that, when evaluating different architectures on supervised tasks, incorporation of data-driven priors via pretraining is essential for reliable performance estimation, and can be done efficiently.
Efficient High-Resolution Template Matching with Vector Quantized Nearest Neighbour Fields
Jun 26, 2023Template matching is a fundamental problem in computer vision and has applications in various fields, such as object detection, image registration, and object tracking. The current state-of-the-art methods rely on nearest-neighbour (NN) matching in which the query feature space is converted to NN space by representing each query pixel with its NN in the template pixels. The NN-based methods have been shown to perform better in occlusions, changes in appearance, illumination variations, and non-rigid transformations. However, NN matching scales poorly with high-resolution data and high feature dimensions. In this work, we present an NN-based template-matching method which efficiently reduces the NN computations and introduces filtering in the NN fields to consider deformations. A vector quantization step first represents the template with $k$ features, then filtering compares the template and query distributions over the $k$ features. We show that state-of-the-art performance was achieved in low-resolution data, and our method outperforms previous methods at higher resolution showing the robustness and scalability of the approach.
Experimental Validation of Safe MPC for Autonomous Driving in Uncertain Environments
May 05, 2023The full deployment of autonomous driving systems on a worldwide scale requires that the self-driving vehicle be operated in a provably safe manner, i.e., the vehicle must be able to avoid collisions in any possible traffic situation. In this paper, we propose a framework based on Model Predictive Control (MPC) that endows the self-driving vehicle with the necessary safety guarantees. In particular, our framework ensures constraint satisfaction at all times, while tracking the reference trajectory as close as obstacles allow, resulting in a safe and comfortable driving behavior. To discuss the performance and real-time capability of our framework, we provide first an illustrative simulation example, and then we demonstrate the effectiveness of our framework in experiments with a real test vehicle.
Diagonal State Space Augmented Transformers for Speech Recognition
Feb 27, 2023We improve on the popular conformer architecture by replacing the depthwise temporal convolutions with diagonal state space (DSS) models. DSS is a recently introduced variant of linear RNNs obtained by discretizing a linear dynamical system with a diagonal state transition matrix. DSS layers project the input sequence onto a space of orthogonal polynomials where the choice of basis functions, metric and support is controlled by the eigenvalues of the transition matrix. We compare neural transducers with either conformer or our proposed DSS-augmented transformer (DSSformer) encoders on three public corpora: Switchboard English conversational telephone speech 300 hours, Switchboard+Fisher 2000 hours, and a spoken archive of holocaust survivor testimonials called MALACH 176 hours. On Switchboard 300/2000 hours, we reach a single model performance of 8.9%/6.7% WER on the combined test set of the Hub5 2000 evaluation, respectively, and on MALACH we improve the WER by 7% relative over the previous best published result. In addition, we present empirical evidence suggesting that DSS layers learn damped Fourier basis functions where the attenuation coefficients are layer specific whereas the frequency coefficients converge to almost identical linearly-spaced values across all layers.
Simplifying and Understanding State Space Models with Diagonal Linear RNNs
Dec 07, 2022



Sequence models based on linear state spaces (SSMs) have recently emerged as a promising choice of architecture for modeling long range dependencies across various modalities. However, they invariably rely on discretization of a continuous state space, which complicates their presentation and understanding. In this work, we dispose of the discretization step, and propose a model based on vanilla Diagonal Linear RNNs ($\mathrm{DLR}$). We empirically show that $\mathrm{DLR}$ is as performant as previously-proposed SSMs in the presence of strong supervision, despite being conceptually much simpler. Moreover, we characterize the expressivity of SSMs (including $\mathrm{DLR}$) and attention-based models via a suite of $13$ synthetic sequence-to-sequence tasks involving interactions over tens of thousands of tokens, ranging from simple operations, such as shifting an input sequence, to detecting co-dependent visual features over long spatial ranges in flattened images. We find that while SSMs report near-perfect performance on tasks that can be modeled via $\textit{few}$ convolutional kernels, they struggle on tasks requiring $\textit{many}$ such kernels and especially when the desired sequence manipulation is $\textit{context-dependent}$. For example, $\mathrm{DLR}$ learns to perfectly shift a $0.5M$-long input by an arbitrary number of positions but fails when the shift size depends on context. Despite these limitations, $\mathrm{DLR}$ reaches high performance on two higher-order reasoning tasks $\mathrm{ListOpsSubTrees}$ and $\mathrm{PathfinderSegmentation}\text{-}\mathrm{256}$ with input lengths $8K$ and $65K$ respectively, and gives encouraging performance on $\mathrm{PathfinderSegmentation}\text{-}\mathrm{512}$ with input length $262K$ for which attention is not a viable choice.
A Novel Frame Structure for Cloud-Based Audio-Visual Speech Enhancement in Multimodal Hearing-aids
Oct 24, 2022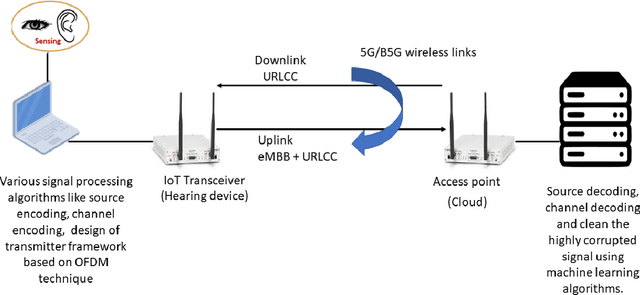
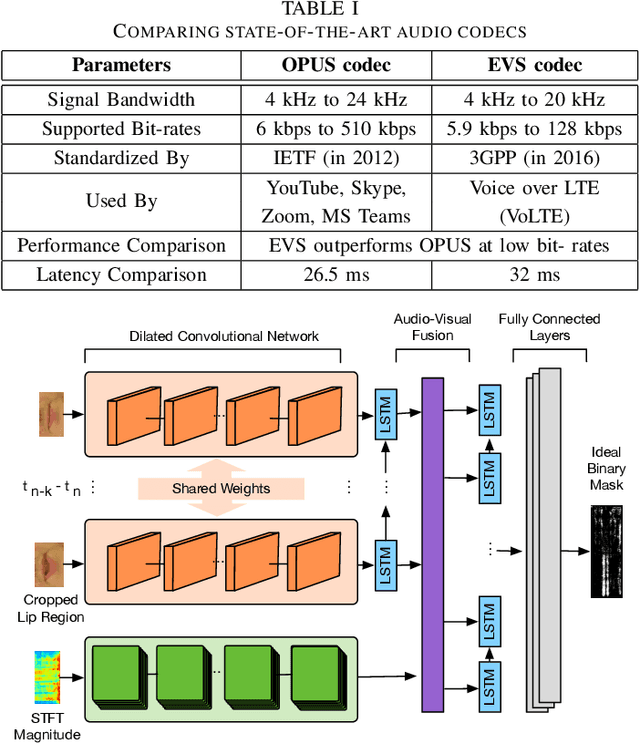
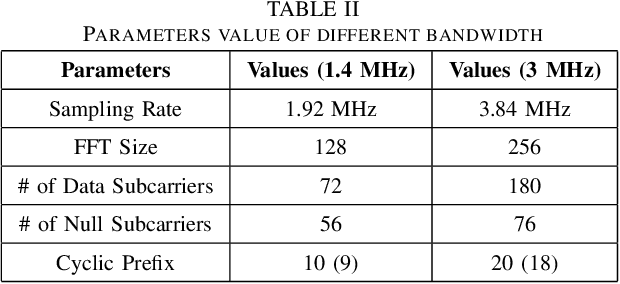
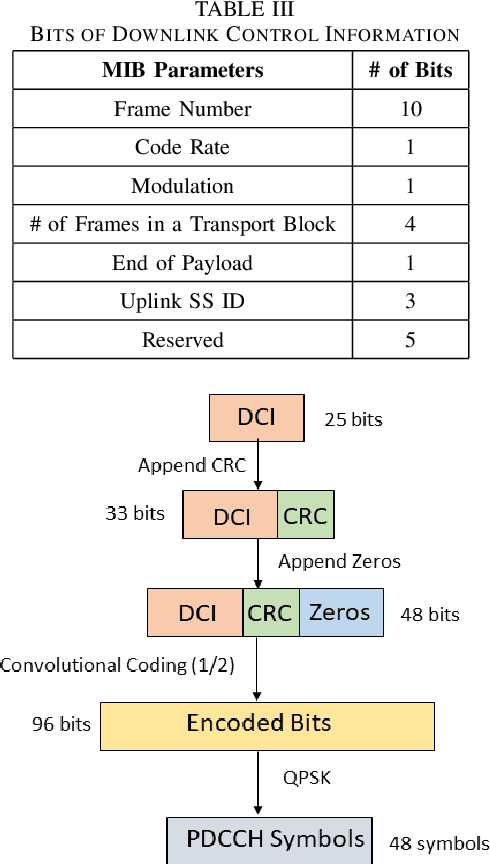
In this paper, we design a first of its kind transceiver (PHY layer) prototype for cloud-based audio-visual (AV) speech enhancement (SE) complying with high data rate and low latency requirements of future multimodal hearing assistive technology. The innovative design needs to meet multiple challenging constraints including up/down link communications, delay of transmission and signal processing, and real-time AV SE models processing. The transceiver includes device detection, frame detection, frequency offset estimation, and channel estimation capabilities. We develop both uplink (hearing aid to the cloud) and downlink (cloud to hearing aid) frame structures based on the data rate and latency requirements. Due to the varying nature of uplink information (audio and lip-reading), the uplink channel supports multiple data rate frame structure, while the downlink channel has a fixed data rate frame structure. In addition, we evaluate the latency of different PHY layer blocks of the transceiver for developed frame structures using LabVIEW NXG. This can be used with software defined radio (such as Universal Software Radio Peripheral) for real-time demonstration scenarios.