 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBiRQ: Bi-Level Self-Labeling Random Quantization for Self-Supervised Speech Recognition
Sep 18, 2025Speech is a rich signal, and labeled audio-text pairs are costly, making self-supervised learning essential for scalable representation learning. A core challenge in speech SSL is generating pseudo-labels that are both informative and efficient: strong labels, such as those used in HuBERT, improve downstream performance but rely on external encoders and multi-stage pipelines, while efficient methods like BEST-RQ achieve simplicity at the cost of weaker labels. We propose BiRQ, a bilevel SSL framework that combines the efficiency of BEST-RQ with the refinement benefits of HuBERT-style label enhancement. The key idea is to reuse part of the model itself as a pseudo-label generator: intermediate representations are discretized by a random-projection quantizer to produce enhanced labels, while anchoring labels derived directly from the raw input stabilize training and prevent collapse. Training is formulated as an efficient first-order bilevel optimization problem, solved end-to-end with differentiable Gumbel-softmax selection. This design eliminates the need for external label encoders, reduces memory cost, and enables iterative label refinement in an end-to-end fashion. BiRQ consistently improves over BEST-RQ while maintaining low complexity and computational efficiency. We validate our method on various datasets, including 960-hour LibriSpeech, 150-hour AMI meetings and 5,000-hour YODAS, demonstrating consistent gains over BEST-RQ.
Self-Supervised Pre-Training with Equilibrium Constraints
Aug 27, 2025Self-supervised pre-training using unlabeled data is widely used in machine learning. In this paper, we propose a new self-supervised pre-training approach to dealing with heterogeneous data. Instead of mixing all the data and minimizing the averaged global loss in the conventional way, we impose additional equilibrium constraints to ensure that the models optimizes each source of heterogeneous data to its local optima after $K$-step gradient descent initialized from the model. We formulate this as a bilevel optimization problem, and use the first-order approximation method to solve the problem. We discuss its connection to model-agnostic meta learning (MAML). Experiments are carried out on self-supervised pre-training using multi-domain and multilingual datasets, demonstrating that the proposed approach can significantly improve the adaptivity of the self-supervised pre-trained model for the downstream supervised fine-tuning tasks.
SEER: Semantic Enhancement and Emotional Reasoning Network for Multimodal Fake News Detection
Jul 17, 2025Previous studies on multimodal fake news detection mainly focus on the alignment and integration of cross-modal features, as well as the application of text-image consistency. However, they overlook the semantic enhancement effects of large multimodal models and pay little attention to the emotional features of news. In addition, people find that fake news is more inclined to contain negative emotions than real ones. Therefore, we propose a novel Semantic Enhancement and Emotional Reasoning (SEER) Network for multimodal fake news detection. We generate summarized captions for image semantic understanding and utilize the products of large multimodal models for semantic enhancement. Inspired by the perceived relationship between news authenticity and emotional tendencies, we propose an expert emotional reasoning module that simulates real-life scenarios to optimize emotional features and infer the authenticity of news. Extensive experiments on two real-world datasets demonstrate the superiority of our SEER over state-of-the-art baselines.
Granite-speech: open-source speech-aware LLMs with strong English ASR capabilities
May 14, 2025Granite-speech LLMs are compact and efficient speech language models specifically designed for English ASR and automatic speech translation (AST). The models were trained by modality aligning the 2B and 8B parameter variants of granite-3.3-instruct to speech on publicly available open-source corpora containing audio inputs and text targets consisting of either human transcripts for ASR or automatically generated translations for AST. Comprehensive benchmarking shows that on English ASR, which was our primary focus, they outperform several competitors' models that were trained on orders of magnitude more proprietary data, and they keep pace on English-to-X AST for major European languages, Japanese, and Chinese. The speech-specific components are: a conformer acoustic encoder using block attention and self-conditioning trained with connectionist temporal classification, a windowed query-transformer speech modality adapter used to do temporal downsampling of the acoustic embeddings and map them to the LLM text embedding space, and LoRA adapters to further fine-tune the text LLM. Granite-speech-3.3 operates in two modes: in speech mode, it performs ASR and AST by activating the encoder, projector, and LoRA adapters; in text mode, it calls the underlying granite-3.3-instruct model directly (without LoRA), essentially preserving all the text LLM capabilities and safety. Both models are freely available on HuggingFace (https://huggingface.co/ibm-granite/granite-speech-3.3-2b and https://huggingface.co/ibm-granite/granite-speech-3.3-8b) and can be used for both research and commercial purposes under a permissive Apache 2.0 license.
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Dec 11, 2024In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
Training Nonlinear Transformers for Chain-of-Thought Inference: A Theoretical Generalization Analysis
Oct 03, 2024
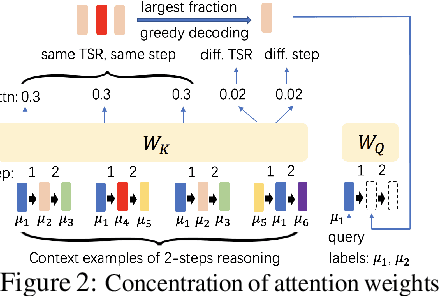
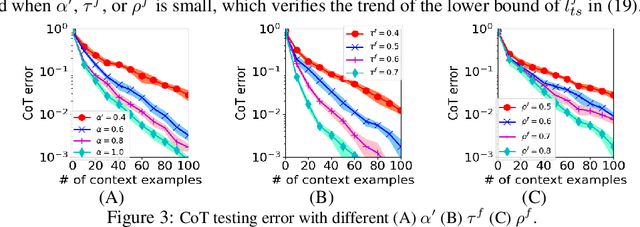
Chain-of-Thought (CoT) is an efficient prompting method that enables the reasoning ability of large language models by augmenting the query using multiple examples with multiple intermediate steps. Despite the empirical success, the theoretical understanding of how to train a Transformer to achieve the CoT ability remains less explored. This is primarily due to the technical challenges involved in analyzing the nonconvex optimization on nonlinear attention models. To the best of our knowledge, this work provides the first theoretical study of training Transformers with nonlinear attention to obtain the CoT generalization capability so that the resulting model can inference on unseen tasks when the input is augmented by examples of the new task. We first quantify the required training samples and iterations to train a Transformer model towards CoT ability. We then prove the success of its CoT generalization on unseen tasks with distribution-shifted testing data. Moreover, we theoretically characterize the conditions for an accurate reasoning output by CoT even when the provided reasoning examples contain noises and are not always accurate. In contrast, in-context learning (ICL), which can be viewed as one-step CoT without intermediate steps, may fail to provide an accurate output when CoT does. These theoretical findings are justified through experiments.
Training Nonlinear Transformers for Efficient In-Context Learning: A Theoretical Learning and Generalization Analysis
Feb 23, 2024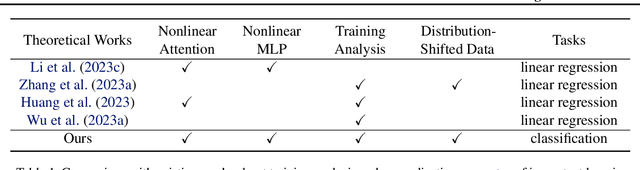
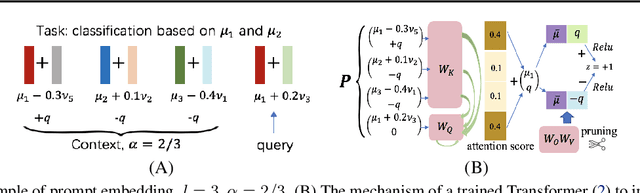
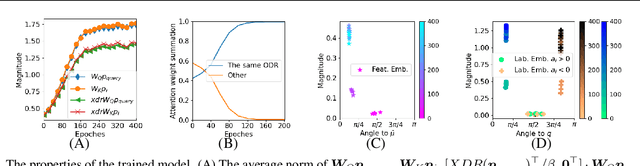
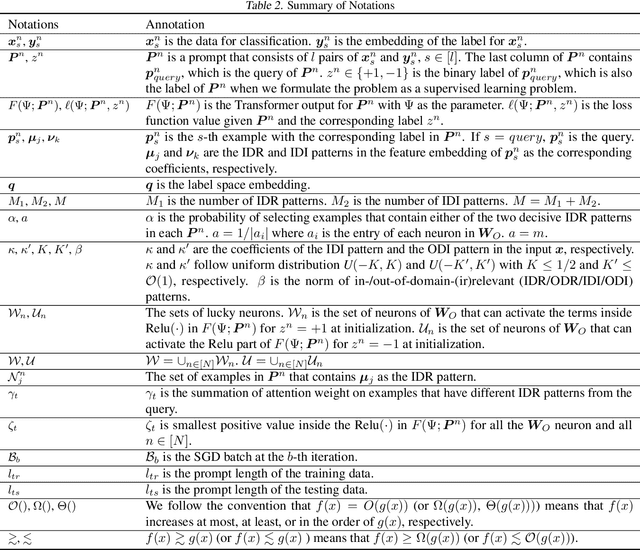
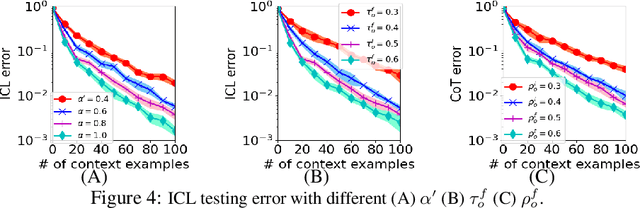
Transformer-based large language models have displayed impressive in-context learning capabilities, where a pre-trained model can handle new tasks without fine-tuning by simply augmenting the query with some input-output examples from that task. Despite the empirical success, the mechanics of how to train a Transformer to achieve ICL and the corresponding ICL capacity is mostly elusive due to the technical challenges of analyzing the nonconvex training problems resulting from the nonlinear self-attention and nonlinear activation in Transformers. To the best of our knowledge, this paper provides the first theoretical analysis of the training dynamics of Transformers with nonlinear self-attention and nonlinear MLP, together with the ICL generalization capability of the resulting model. Focusing on a group of binary classification tasks, we train Transformers using data from a subset of these tasks and quantify the impact of various factors on the ICL generalization performance on the remaining unseen tasks with and without data distribution shifts. We also analyze how different components in the learned Transformers contribute to the ICL performance. Furthermore, we provide the first theoretical analysis of how model pruning affects the ICL performance and prove that proper magnitude-based pruning can have a minimal impact on ICL while reducing inference costs. These theoretical findings are justified through numerical experiments.
Joint Unsupervised and Supervised Training for Automatic Speech Recognition via Bilevel Optimization
Jan 13, 2024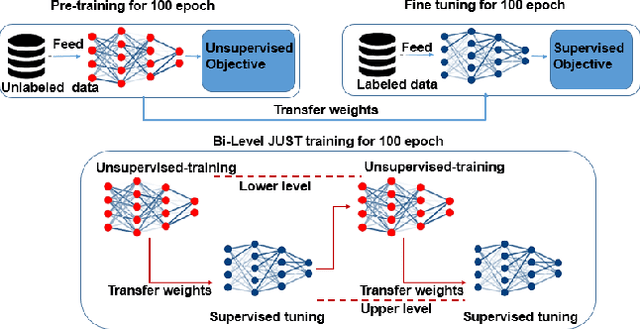

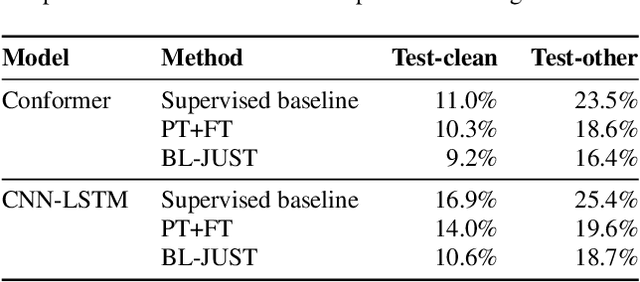
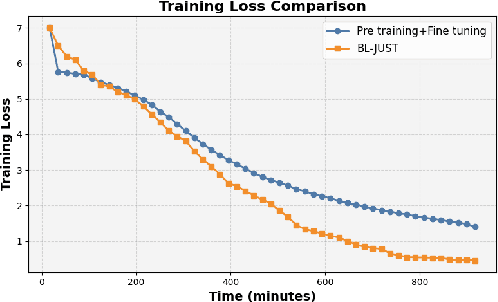
In this paper, we present a novel bilevel optimization-based training approach to training acoustic models for automatic speech recognition (ASR) tasks that we term {bi-level joint unsupervised and supervised training (BL-JUST)}. {BL-JUST employs a lower and upper level optimization with an unsupervised loss and a supervised loss respectively, leveraging recent advances in penalty-based bilevel optimization to solve this challenging ASR problem with affordable complexity and rigorous convergence guarantees.} To evaluate BL-JUST, extensive experiments on the LibriSpeech and TED-LIUM v2 datasets have been conducted. BL-JUST achieves superior performance over the commonly used pre-training followed by fine-tuning strategy.
Soft Random Sampling: A Theoretical and Empirical Analysis
Nov 24, 2023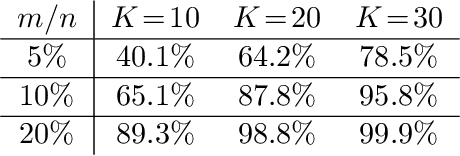
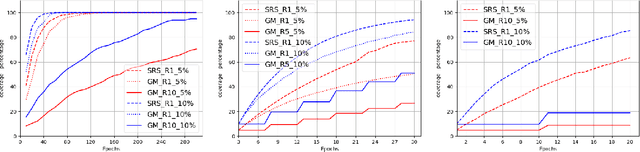
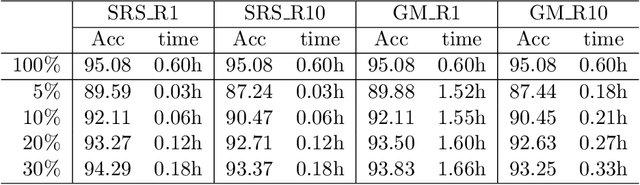
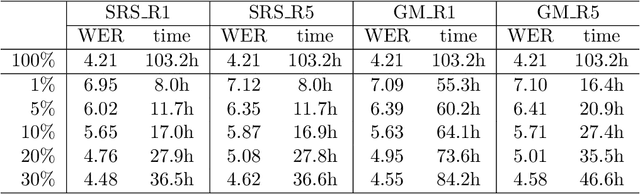
Soft random sampling (SRS) is a simple yet effective approach for efficient training of large-scale deep neural networks when dealing with massive data. SRS selects a subset uniformly at random with replacement from the full data set in each epoch. In this paper, we conduct a theoretical and empirical analysis of SRS. First, we analyze its sampling dynamics including data coverage and occupancy. Next, we investigate its convergence with non-convex objective functions and give the convergence rate. Finally, we provide its generalization performance. We empirically evaluate SRS for image recognition on CIFAR10 and automatic speech recognition on Librispeech and an in-house payload dataset to demonstrate its effectiveness. Compared to existing coreset-based data selection methods, SRS offers a better accuracy-efficiency trade-off. Especially on real-world industrial scale data sets, it is shown to be a powerful training strategy with significant speedup and competitive performance with almost no additional computing cost.
How Can Context Help? Exploring Joint Retrieval of Passage and Personalized Context
Aug 26, 2023



The integration of external personalized context information into document-grounded conversational systems has significant potential business value, but has not been well-studied. Motivated by the concept of personalized context-aware document-grounded conversational systems, we introduce the task of context-aware passage retrieval. We also construct a dataset specifically curated for this purpose. We describe multiple baseline systems to address this task, and propose a novel approach, Personalized Context-Aware Search (PCAS), that effectively harnesses contextual information during passage retrieval. Experimental evaluations conducted on multiple popular dense retrieval systems demonstrate that our proposed approach not only outperforms the baselines in retrieving the most relevant passage but also excels at identifying the pertinent context among all the available contexts. We envision that our contributions will serve as a catalyst for inspiring future research endeavors in this promising direction.