 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Supervised Pre-Training with Equilibrium Constraints
Aug 27, 2025Self-supervised pre-training using unlabeled data is widely used in machine learning. In this paper, we propose a new self-supervised pre-training approach to dealing with heterogeneous data. Instead of mixing all the data and minimizing the averaged global loss in the conventional way, we impose additional equilibrium constraints to ensure that the models optimizes each source of heterogeneous data to its local optima after $K$-step gradient descent initialized from the model. We formulate this as a bilevel optimization problem, and use the first-order approximation method to solve the problem. We discuss its connection to model-agnostic meta learning (MAML). Experiments are carried out on self-supervised pre-training using multi-domain and multilingual datasets, demonstrating that the proposed approach can significantly improve the adaptivity of the self-supervised pre-trained model for the downstream supervised fine-tuning tasks.
A First-order Generative Bilevel Optimization Framework for Diffusion Models
Feb 12, 2025Diffusion models, which iteratively denoise data samples to synthesize high-quality outputs, have achieved empirical success across domains. However, optimizing these models for downstream tasks often involves nested bilevel structures, such as tuning hyperparameters for fine-tuning tasks or noise schedules in training dynamics, where traditional bilevel methods fail due to the infinite-dimensional probability space and prohibitive sampling costs. We formalize this challenge as a generative bilevel optimization problem and address two key scenarios: (1) fine-tuning pre-trained models via an inference-only lower-level solver paired with a sample-efficient gradient estimator for the upper level, and (2) training diffusion models from scratch with noise schedule optimization by reparameterizing the lower-level problem and designing a computationally tractable gradient estimator. Our first-order bilevel framework overcomes the incompatibility of conventional bilevel methods with diffusion processes, offering theoretical grounding and computational practicality. Experiments demonstrate that our method outperforms existing fine-tuning and hyperparameter search baselines.
Bilevel Joint Unsupervised and Supervised Training for Automatic Speech Recognition
Dec 11, 2024In this paper, we propose a bilevel joint unsupervised and supervised training (BL-JUST) framework for automatic speech recognition. Compared to the conventional pre-training and fine-tuning strategy which is a disconnected two-stage process, BL-JUST tries to optimize an acoustic model such that it simultaneously minimizes both the unsupervised and supervised loss functions. Because BL-JUST seeks matched local optima of both loss functions, acoustic representations learned by the acoustic model strike a good balance between being generic and task-specific. We solve the BL-JUST problem using penalty-based bilevel gradient descent and evaluate the trained deep neural network acoustic models on various datasets with a variety of architectures and loss functions. We show that BL-JUST can outperform the widely-used pre-training and fine-tuning strategy and some other popular semi-supervised techniques.
Joint Unsupervised and Supervised Training for Automatic Speech Recognition via Bilevel Optimization
Jan 13, 2024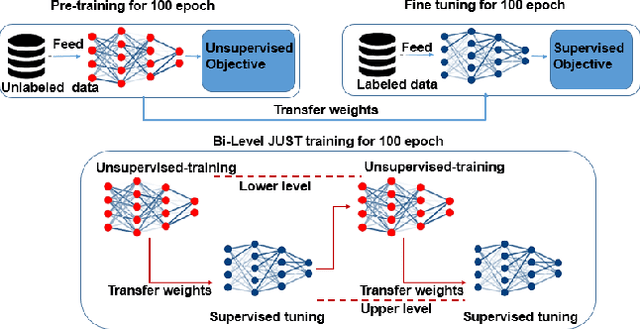

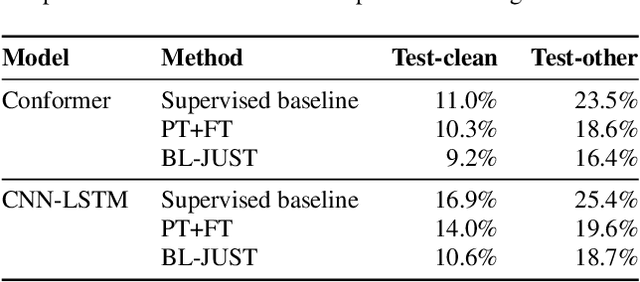
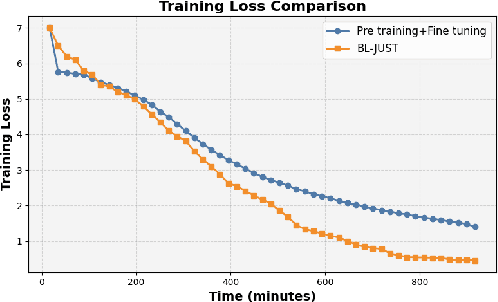
In this paper, we present a novel bilevel optimization-based training approach to training acoustic models for automatic speech recognition (ASR) tasks that we term {bi-level joint unsupervised and supervised training (BL-JUST)}. {BL-JUST employs a lower and upper level optimization with an unsupervised loss and a supervised loss respectively, leveraging recent advances in penalty-based bilevel optimization to solve this challenging ASR problem with affordable complexity and rigorous convergence guarantees.} To evaluate BL-JUST, extensive experiments on the LibriSpeech and TED-LIUM v2 datasets have been conducted. BL-JUST achieves superior performance over the commonly used pre-training followed by fine-tuning strategy.