 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevis: Sparse Latent Steering to Mitigate Object Hallucination in Large Vision-Language Models
Feb 12, 2026Despite the advanced capabilities of Large Vision-Language Models (LVLMs), they frequently suffer from object hallucination. One reason is that visual features and pretrained textual representations often become intertwined in the deeper network layers. To address this, we propose REVIS, a training-free framework designed to explicitly re-activate this suppressed visual information. Rooted in latent space geometry, REVIS extracts the pure visual information vector via orthogonal projection and employs a calibrated strategy to perform sparse intervention only at the precise depth where suppression occurs. This surgical approach effectively restores visual information with minimal computational cost. Empirical evaluations on standard benchmarks demonstrate that REVIS reduces object hallucination rates by approximately 19% compared to state-of-the-art baselines, while preserving general reasoning capabilities.
Light Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
Feb 02, 2026The safety of large language models (LLMs) has increasingly emerged as a fundamental aspect of their development. Existing safety alignment for LLMs is predominantly achieved through post-training methods, which are computationally expensive and often fail to generalize well across different models. A small number of lightweight alignment approaches either rely heavily on prior-computed safety injections or depend excessively on the model's own capabilities, resulting in limited generalization and degraded efficiency and usability during generation. In this work, we propose a safety-aware decoding method that requires only low-cost training of an expert model and employs a single neuron as a gating mechanism. By effectively balancing the model's intrinsic capabilities with external guidance, our approach simultaneously preserves utility and enhances output safety. It demonstrates clear advantages in training overhead and generalization across model scales, offering a new perspective on lightweight alignment for the safe and practical deployment of large language models. Code: https://github.com/Beijing-AISI/NGSD.
On Entropy Control in LLM-RL Algorithms
Sep 03, 2025For RL algorithms, appropriate entropy control is crucial to their effectiveness. To control the policy entropy, a commonly used method is entropy regularization, which is adopted in various popular RL algorithms including PPO, SAC and A3C. Although entropy regularization proves effective in robotic and games RL conventionally, studies found that it gives weak to no gains in LLM-RL training. In this work, we study the issues of entropy bonus in LLM-RL setting. Specifically, we first argue that the conventional entropy regularization suffers from the LLM's extremely large response space and the sparsity of the optimal outputs. As a remedy, we propose AEnt, an entropy control method that utilizes a new clamped entropy bonus with an automatically adjusted coefficient. The clamped entropy is evaluated with the re-normalized policy defined on certain smaller token space, which encourages exploration within a more compact response set. In addition, the algorithm automatically adjusts entropy coefficient according to the clamped entropy value, effectively controlling the entropy-induced bias while leveraging the entropy's benefits. AEnt is tested in math-reasoning tasks under different base models and datasets, and it is observed that AEnt outperforms the baselines consistently across multiple benchmarks.
Fundamental Safety-Capability Trade-offs in Fine-tuning Large Language Models
Mar 24, 2025Fine-tuning Large Language Models (LLMs) on some task-specific datasets has been a primary use of LLMs. However, it has been empirically observed that this approach to enhancing capability inevitably compromises safety, a phenomenon also known as the safety-capability trade-off in LLM fine-tuning. This paper presents a theoretical framework for understanding the interplay between safety and capability in two primary safety-aware LLM fine-tuning strategies, providing new insights into the effects of data similarity, context overlap, and alignment loss landscape. Our theoretical results characterize the fundamental limits of the safety-capability trade-off in LLM fine-tuning, which are also validated by numerical experiments.
Mitigating Forgetting in LLM Supervised Fine-Tuning and Preference Learning
Oct 20, 2024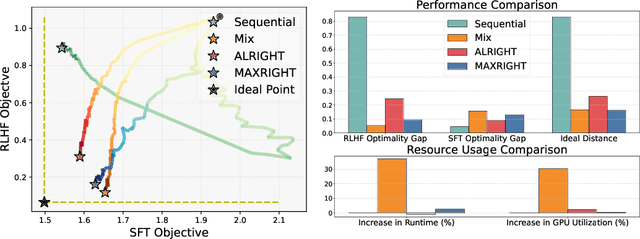
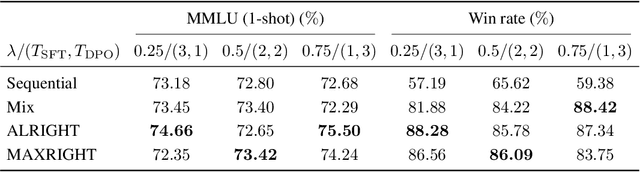
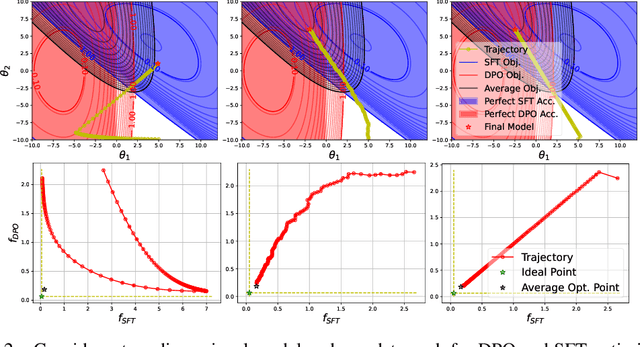
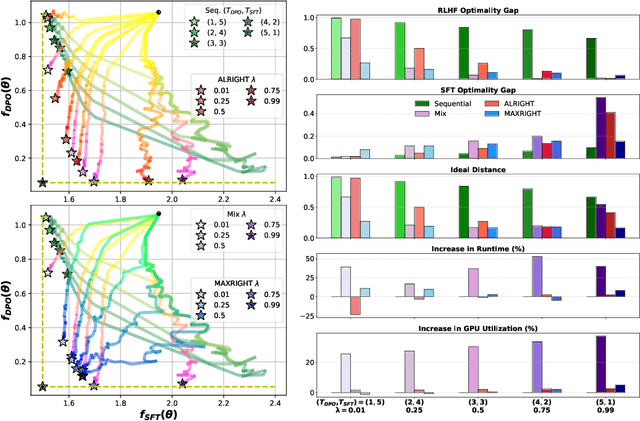
Post-training of pre-trained LLMs, which typically consists of the supervised fine-tuning (SFT) stage and the preference learning (RLHF or DPO) stage, is crucial to effective and safe LLM applications. The widely adopted approach in post-training popular open-source LLMs is to sequentially perform SFT and RLHF/DPO. However, sequential training is sub-optimal in terms of SFT and RLHF/DPO trade-off: the LLM gradually forgets about the first stage's training when undergoing the second stage's training. We theoretically prove the sub-optimality of sequential post-training. Furthermore, we propose a practical joint post-training framework with theoretical convergence guarantees and empirically outperforms sequential post-training framework, while having similar computational cost. Our code is available at https://github.com/heshandevaka/XRIGHT.
SEAL: Safety-enhanced Aligned LLM Fine-tuning via Bilevel Data Selection
Oct 09, 2024
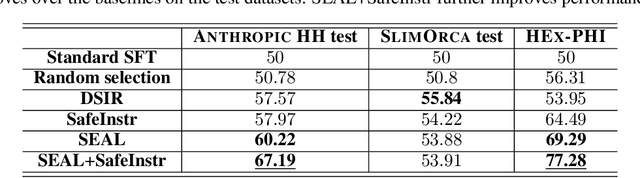

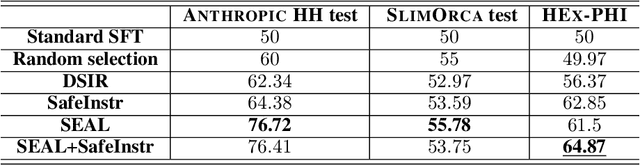
Fine-tuning on task-specific data to boost downstream performance is a crucial step for leveraging Large Language Models (LLMs). However, previous studies have demonstrated that fine-tuning the models on several adversarial samples or even benign data can greatly comprise the model's pre-equipped alignment and safety capabilities. In this work, we propose SEAL, a novel framework to enhance safety in LLM fine-tuning. SEAL learns a data ranker based on the bilevel optimization to up rank the safe and high-quality fine-tuning data and down rank the unsafe or low-quality ones. Models trained with SEAL demonstrate superior quality over multiple baselines, with 8.5% and 9.7% win rate increase compared to random selection respectively on Llama-3-8b-Instruct and Merlinite-7b models. Our code is available on github https://github.com/hanshen95/SEAL.
Principled Penalty-based Methods for Bilevel Reinforcement Learning and RLHF
Feb 10, 2024
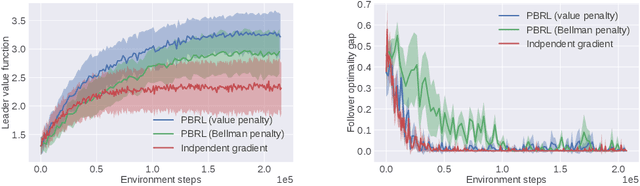

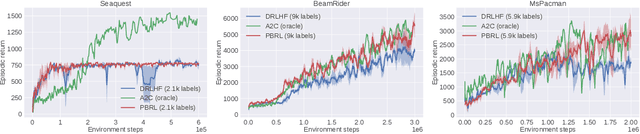
Bilevel optimization has been recently applied to many machine learning tasks. However, their applications have been restricted to the supervised learning setting, where static objective functions with benign structures are considered. But bilevel problems such as incentive design, inverse reinforcement learning (RL), and RL from human feedback (RLHF) are often modeled as dynamic objective functions that go beyond the simple static objective structures, which pose significant challenges of using existing bilevel solutions. To tackle this new class of bilevel problems, we introduce the first principled algorithmic framework for solving bilevel RL problems through the lens of penalty formulation. We provide theoretical studies of the problem landscape and its penalty-based (policy) gradient algorithms. We demonstrate the effectiveness of our algorithms via simulations in the Stackelberg Markov game, RL from human feedback and incentive design.
Joint Unsupervised and Supervised Training for Automatic Speech Recognition via Bilevel Optimization
Jan 13, 2024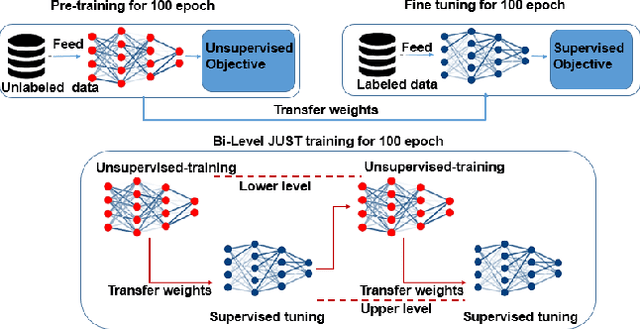

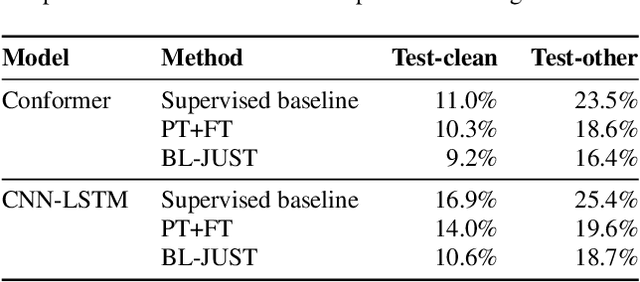
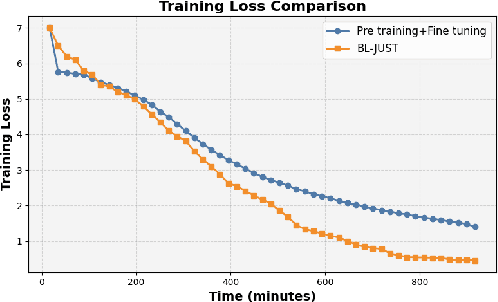
In this paper, we present a novel bilevel optimization-based training approach to training acoustic models for automatic speech recognition (ASR) tasks that we term {bi-level joint unsupervised and supervised training (BL-JUST)}. {BL-JUST employs a lower and upper level optimization with an unsupervised loss and a supervised loss respectively, leveraging recent advances in penalty-based bilevel optimization to solve this challenging ASR problem with affordable complexity and rigorous convergence guarantees.} To evaluate BL-JUST, extensive experiments on the LibriSpeech and TED-LIUM v2 datasets have been conducted. BL-JUST achieves superior performance over the commonly used pre-training followed by fine-tuning strategy.
On Penalty-based Bilevel Gradient Descent Method
Feb 10, 2023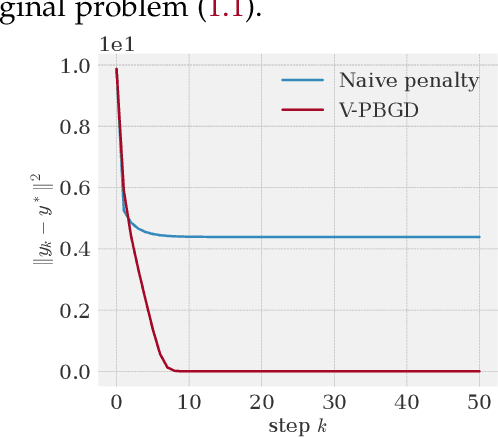


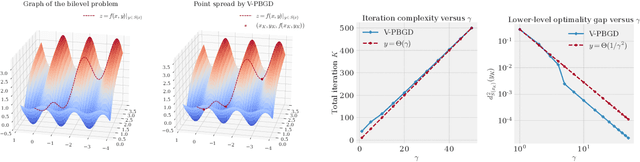
Bilevel optimization enjoys a wide range of applications in hyper-parameter optimization, meta-learning and reinforcement learning. However, bilevel optimization problems are difficult to solve. Recent progress on scalable bilevel algorithms mainly focuses on bilevel optimization problems where the lower-level objective is either strongly convex or unconstrained. In this work, we tackle the bilevel problem through the lens of the penalty method. We show that under certain conditions, the penalty reformulation recovers the solutions of the original bilevel problem. Further, we propose the penalty-based bilevel gradient descent (PBGD) algorithm and establish its finite-time convergence for the constrained bilevel problem without lower-level strong convexity. Experiments showcase the efficiency of the proposed PBGD algorithm.
Alternating Implicit Projected SGD and Its Efficient Variants for Equality-constrained Bilevel Optimization
Nov 14, 2022Stochastic bilevel optimization, which captures the inherent nested structure of machine learning problems, is gaining popularity in many recent applications. Existing works on bilevel optimization mostly consider either unconstrained problems or constrained upper-level problems. This paper considers the stochastic bilevel optimization problems with equality constraints both in the upper and lower levels. By leveraging the special structure of the equality constraints problem, the paper first presents an alternating implicit projected SGD approach and establishes the $\tilde{\cal O}(\epsilon^{-2})$ sample complexity that matches the state-of-the-art complexity of ALSET \citep{chen2021closing} for unconstrained bilevel problems. To further save the cost of projection, the paper presents two alternating implicit projection-efficient SGD approaches, where one algorithm enjoys the $\tilde{\cal O}(\epsilon^{-2}/T)$ upper-level and ${\cal O}(\epsilon^{-1.5}/T^{\frac{3}{4}})$ lower-level projection complexity with ${\cal O}(T)$ lower-level batch size, and the other one enjoys $\tilde{\cal O}(\epsilon^{-1.5})$ upper-level and lower-level projection complexity with ${\cal O}(1)$ batch size. Application to federated bilevel optimization has been presented to showcase the empirical performance of our algorithms. Our results demonstrate that equality-constrained bilevel optimization with strongly-convex lower-level problems can be solved as efficiently as stochastic single-level optimization problems.