 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongDA: Benchmarking LLM Agents for Long-Document Data Analysis
Jan 05, 2026We introduce LongDA, a data analysis benchmark for evaluating LLM-based agents under documentation-intensive analytical workflows. In contrast to existing benchmarks that assume well-specified schemas and inputs, LongDA targets real-world settings in which navigating long documentation and complex data is the primary bottleneck. To this end, we manually curate raw data files, long and heterogeneous documentation, and expert-written publications from 17 publicly available U.S. national surveys, from which we extract 505 analytical queries grounded in real analytical practice. Solving these queries requires agents to first retrieve and integrate key information from multiple unstructured documents, before performing multi-step computations and writing executable code, which remains challenging for existing data analysis agents. To support the systematic evaluation under this setting, we develop LongTA, a tool-augmented agent framework that enables document access, retrieval, and code execution, and evaluate a range of proprietary and open-source models. Our experiments reveal substantial performance gaps even among state-of-the-art models, highlighting the challenges researchers should consider before applying LLM agents for decision support in real-world, high-stakes analytical settings.
Patching LLM Like Software: A Lightweight Method for Improving Safety Policy in Large Language Models
Nov 11, 2025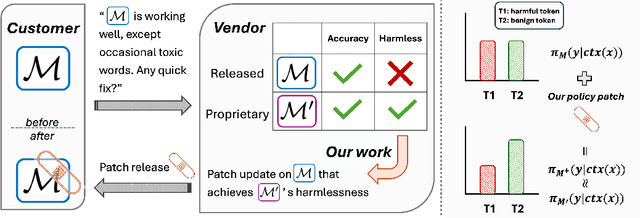
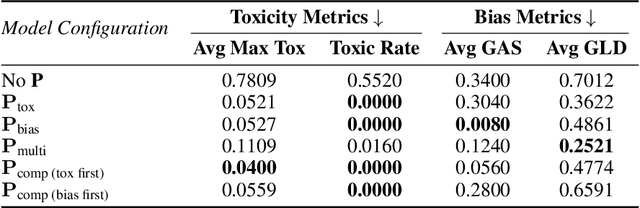
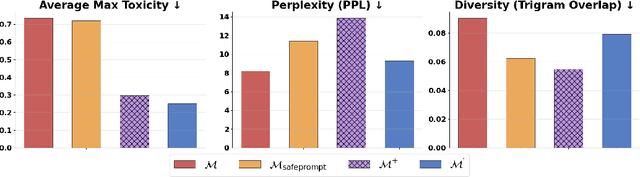
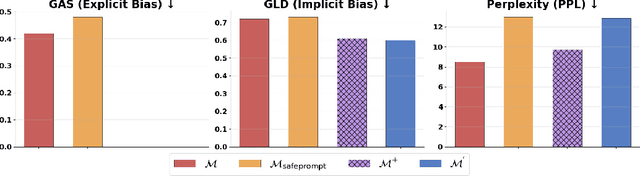
We propose patching for large language models (LLMs) like software versions, a lightweight and modular approach for addressing safety vulnerabilities. While vendors release improved LLM versions, major releases are costly, infrequent, and difficult to tailor to customer needs, leaving released models with known safety gaps. Unlike full-model fine-tuning or major version updates, our method enables rapid remediation by prepending a compact, learnable prefix to an existing model. This "patch" introduces only 0.003% additional parameters, yet reliably steers model behavior toward that of a safer reference model. Across three critical domains (toxicity mitigation, bias reduction, and harmfulness refusal) policy patches achieve safety improvements comparable to next-generation safety-aligned models while preserving fluency. Our results demonstrate that LLMs can be "patched" much like software, offering vendors and practitioners a practical mechanism for distributing scalable, efficient, and composable safety updates between major model releases.
Language Models Coupled with Metacognition Can Outperform Reasoning Models
Aug 25, 2025Large language models (LLMs) excel in speed and adaptability across various reasoning tasks, but they often struggle when strict logic or constraint enforcement is required. In contrast, Large Reasoning Models (LRMs) are specifically designed for complex, step-by-step reasoning, although they come with significant computational costs and slower inference times. To address these trade-offs, we employ and generalize the SOFAI (Slow and Fast AI) cognitive architecture into SOFAI-LM, which coordinates a fast LLM with a slower but more powerful LRM through metacognition. The metacognitive module actively monitors the LLM's performance and provides targeted, iterative feedback with relevant examples. This enables the LLM to progressively refine its solutions without requiring the need for additional model fine-tuning. Extensive experiments on graph coloring and code debugging problems demonstrate that our feedback-driven approach significantly enhances the problem-solving capabilities of the LLM. In many instances, it achieves performance levels that match or even exceed those of standalone LRMs while requiring considerably less time. Additionally, when the LLM and feedback mechanism alone are insufficient, we engage the LRM by providing appropriate information collected during the LLM's feedback loop, tailored to the specific characteristics of the problem domain and leads to improved overall performance. Evaluations on two contrasting domains: graph coloring, requiring globally consistent solutions, and code debugging, demanding localized fixes, demonstrate that SOFAI-LM enables LLMs to match or outperform standalone LRMs in accuracy while maintaining significantly lower inference time.
Highlight All the Phrases: Enhancing LLM Transparency through Visual Factuality Indicators
Aug 09, 2025Large language models (LLMs) are susceptible to generating inaccurate or false information, often referred to as "hallucinations" or "confabulations." While several technical advancements have been made to detect hallucinated content by assessing the factuality of the model's responses, there is still limited research on how to effectively communicate this information to users. To address this gap, we conducted two scenario-based experiments with a total of 208 participants to systematically compare the effects of various design strategies for communicating factuality scores by assessing participants' ratings of trust, ease in validating response accuracy, and preference. Our findings reveal that participants preferred and trusted a design in which all phrases within a response were color-coded based on factuality scores. Participants also found it easier to validate accuracy of the response in this style compared to a baseline with no style applied. Our study offers practical design guidelines for LLM application developers and designers, aimed at calibrating user trust, aligning with user preferences, and enhancing users' ability to scrutinize LLM outputs.
AutoData: A Multi-Agent System for Open Web Data Collection
May 21, 2025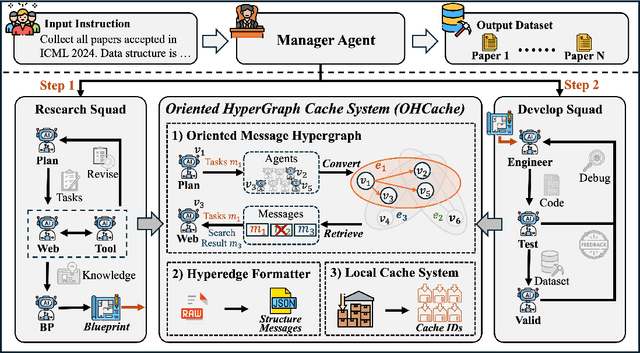
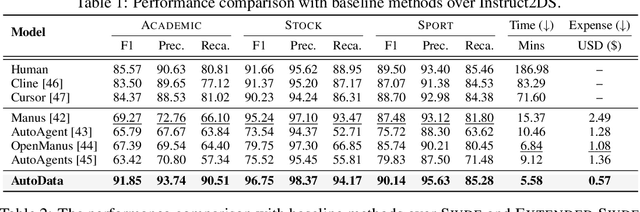
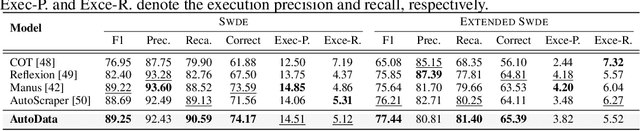

The exponential growth of data-driven systems and AI technologies has intensified the demand for high-quality web-sourced datasets. While existing datasets have proven valuable, conventional web data collection approaches face significant limitations in terms of human effort and scalability. Current data-collecting solutions fall into two categories: wrapper-based methods that struggle with adaptability and reproducibility, and large language model (LLM)-based approaches that incur substantial computational and financial costs. To address these challenges, we propose AutoData, a novel multi-agent system for Automated web Data collection, that requires minimal human intervention, i.e., only necessitating a natural language instruction specifying the desired dataset. In addition, AutoData is designed with a robust multi-agent architecture, featuring a novel oriented message hypergraph coordinated by a central task manager, to efficiently organize agents across research and development squads. Besides, we introduce a novel hypergraph cache system to advance the multi-agent collaboration process that enables efficient automated data collection and mitigates the token cost issues prevalent in existing LLM-based systems. Moreover, we introduce Instruct2DS, a new benchmark dataset supporting live data collection from web sources across three domains: academic, finance, and sports. Comprehensive evaluations over Instruct2DS and three existing benchmark datasets demonstrate AutoData's superior performance compared to baseline methods. Case studies on challenging tasks such as picture book collection and paper extraction from surveys further validate its applicability. Our source code and dataset are available at https://github.com/GraphResearcher/AutoData.
EfficientLLM: Efficiency in Large Language Models
May 20, 2025Large Language Models (LLMs) have driven significant progress, yet their growing parameter counts and context windows incur prohibitive compute, energy, and monetary costs. We introduce EfficientLLM, a novel benchmark and the first comprehensive empirical study evaluating efficiency techniques for LLMs at scale. Conducted on a production-class cluster (48xGH200, 8xH200 GPUs), our study systematically explores three key axes: (1) architecture pretraining (efficient attention variants: MQA, GQA, MLA, NSA; sparse Mixture-of-Experts (MoE)), (2) fine-tuning (parameter-efficient methods: LoRA, RSLoRA, DoRA), and (3) inference (quantization methods: int4, float16). We define six fine-grained metrics (Memory Utilization, Compute Utilization, Latency, Throughput, Energy Consumption, Compression Rate) to capture hardware saturation, latency-throughput balance, and carbon cost. Evaluating over 100 model-technique pairs (0.5B-72B parameters), we derive three core insights: (i) Efficiency involves quantifiable trade-offs: no single method is universally optimal; e.g., MoE reduces FLOPs and improves accuracy but increases VRAM by 40%, while int4 quantization cuts memory/energy by up to 3.9x at a 3-5% accuracy drop. (ii) Optima are task- and scale-dependent: MQA offers optimal memory-latency trade-offs for constrained devices, MLA achieves lowest perplexity for quality-critical tasks, and RSLoRA surpasses LoRA efficiency only beyond 14B parameters. (iii) Techniques generalize across modalities: we extend evaluations to Large Vision Models (Stable Diffusion 3.5, Wan 2.1) and Vision-Language Models (Qwen2.5-VL), confirming effective transferability. By open-sourcing datasets, evaluation pipelines, and leaderboards, EfficientLLM provides essential guidance for researchers and engineers navigating the efficiency-performance landscape of next-generation foundation models.
PEEL the Layers and Find Yourself: Revisiting Inference-time Data Leakage for Residual Neural Networks
Apr 08, 2025This paper explores inference-time data leakage risks of deep neural networks (NNs), where a curious and honest model service provider is interested in retrieving users' private data inputs solely based on the model inference results. Particularly, we revisit residual NNs due to their popularity in computer vision and our hypothesis that residual blocks are a primary cause of data leakage owing to the use of skip connections. By formulating inference-time data leakage as a constrained optimization problem, we propose a novel backward feature inversion method, \textbf{PEEL}, which can effectively recover block-wise input features from the intermediate output of residual NNs. The surprising results in high-quality input data recovery can be explained by the intuition that the output from these residual blocks can be considered as a noisy version of the input and thus the output retains sufficient information for input recovery. We demonstrate the effectiveness of our layer-by-layer feature inversion method on facial image datasets and pre-trained classifiers. Our results show that PEEL outperforms the state-of-the-art recovery methods by an order of magnitude when evaluated by mean squared error (MSE). The code is available at \href{https://github.com/Huzaifa-Arif/PEEL}{https://github.com/Huzaifa-Arif/PEEL}
Cross-Examiner: Evaluating Consistency of Large Language Model-Generated Explanations
Mar 11, 2025Large Language Models (LLMs) are often asked to explain their outputs to enhance accuracy and transparency. However, evidence suggests that these explanations can misrepresent the models' true reasoning processes. One effective way to identify inaccuracies or omissions in these explanations is through consistency checking, which typically involves asking follow-up questions. This paper introduces, cross-examiner, a new method for generating follow-up questions based on a model's explanation of an initial question. Our method combines symbolic information extraction with language model-driven question generation, resulting in better follow-up questions than those produced by LLMs alone. Additionally, this approach is more flexible than other methods and can generate a wider variety of follow-up questions.
Protecting Users From Themselves: Safeguarding Contextual Privacy in Interactions with Conversational Agents
Feb 22, 2025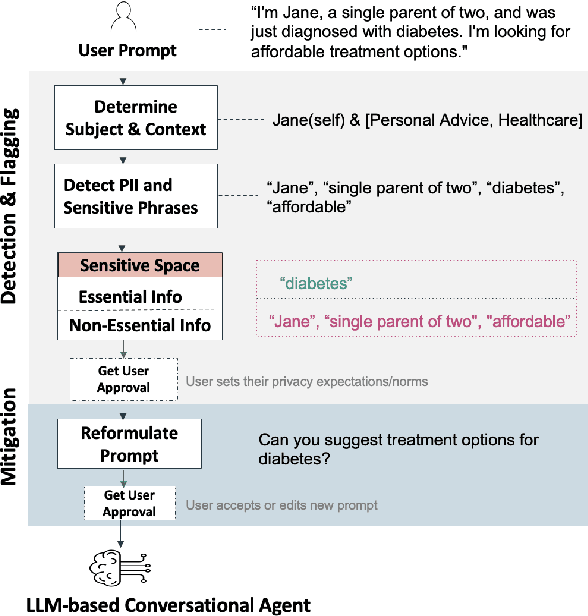

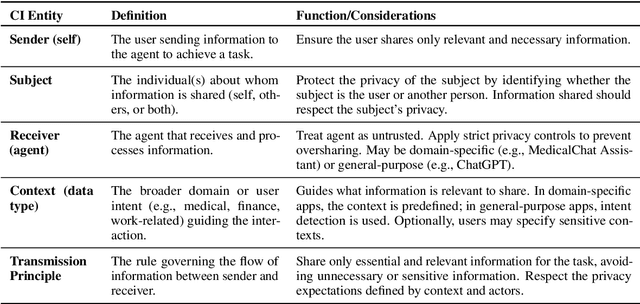
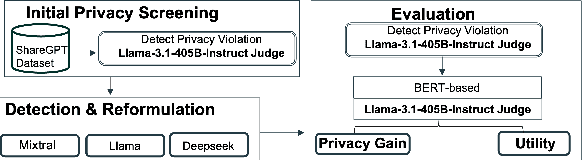
Conversational agents are increasingly woven into individuals' personal lives, yet users often underestimate the privacy risks involved. The moment users share information with these agents (e.g., LLMs), their private information becomes vulnerable to exposure. In this paper, we characterize the notion of contextual privacy for user interactions with LLMs. It aims to minimize privacy risks by ensuring that users (sender) disclose only information that is both relevant and necessary for achieving their intended goals when interacting with LLMs (untrusted receivers). Through a formative design user study, we observe how even "privacy-conscious" users inadvertently reveal sensitive information through indirect disclosures. Based on insights from this study, we propose a locally-deployable framework that operates between users and LLMs, and identifies and reformulates out-of-context information in user prompts. Our evaluation using examples from ShareGPT shows that lightweight models can effectively implement this framework, achieving strong gains in contextual privacy while preserving the user's intended interaction goals through different approaches to classify information relevant to the intended goals.
NGQA: A Nutritional Graph Question Answering Benchmark for Personalized Health-aware Nutritional Reasoning
Dec 20, 2024



Diet plays a critical role in human health, yet tailoring dietary reasoning to individual health conditions remains a major challenge. Nutrition Question Answering (QA) has emerged as a popular method for addressing this problem. However, current research faces two critical limitations. On one hand, the absence of datasets involving user-specific medical information severely limits \textit{personalization}. This challenge is further compounded by the wide variability in individual health needs. On the other hand, while large language models (LLMs), a popular solution for this task, demonstrate strong reasoning abilities, they struggle with the domain-specific complexities of personalized healthy dietary reasoning, and existing benchmarks fail to capture these challenges. To address these gaps, we introduce the Nutritional Graph Question Answering (NGQA) benchmark, the first graph question answering dataset designed for personalized nutritional health reasoning. NGQA leverages data from the National Health and Nutrition Examination Survey (NHANES) and the Food and Nutrient Database for Dietary Studies (FNDDS) to evaluate whether a food is healthy for a specific user, supported by explanations of the key contributing nutrients. The benchmark incorporates three question complexity settings and evaluates reasoning across three downstream tasks. Extensive experiments with LLM backbones and baseline models demonstrate that the NGQA benchmark effectively challenges existing models. In sum, NGQA addresses a critical real-world problem while advancing GraphQA research with a novel domain-specific benchmark.