 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCTBench: A Comprehensive Benchmark for Evaluating Language Model Capabilities in Clinical Trial Design
Jun 25, 2024CTBench is introduced as a benchmark to assess language models (LMs) in aiding clinical study design. Given study-specific metadata, CTBench evaluates AI models' ability to determine the baseline features of a clinical trial (CT), which include demographic and relevant features collected at the trial's start from all participants. These baseline features, typically presented in CT publications (often as Table 1), are crucial for characterizing study cohorts and validating results. Baseline features, including confounders and covariates, are also necessary for accurate treatment effect estimation in studies involving observational data. CTBench consists of two datasets: "CT-Repo," containing baseline features from 1,690 clinical trials sourced from clinicaltrials.gov, and "CT-Pub," a subset of 100 trials with more comprehensive baseline features gathered from relevant publications. Two LM-based evaluation methods are developed to compare the actual baseline feature lists against LM-generated responses. "ListMatch-LM" and "ListMatch-BERT" use GPT-4o and BERT scores (at various thresholds), respectively, for evaluation. To establish baseline results, advanced prompt engineering techniques using LLaMa3-70B-Instruct and GPT-4o in zero-shot and three-shot learning settings are applied to generate potential baseline features. The performance of GPT-4o as an evaluator is validated through human-in-the-loop evaluations on the CT-Pub dataset, where clinical experts confirm matches between actual and LM-generated features. The results highlight a promising direction with significant potential for improvement, positioning CTBench as a useful tool for advancing research on AI in CT design and potentially enhancing the efficacy and robustness of CTs.
InceptB: A CNN Based Classification Approach for Recognizing Traditional Bengali Games
Sep 16, 2018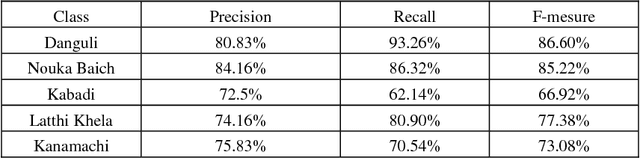
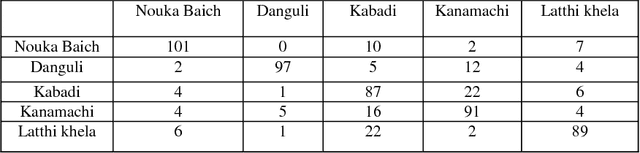
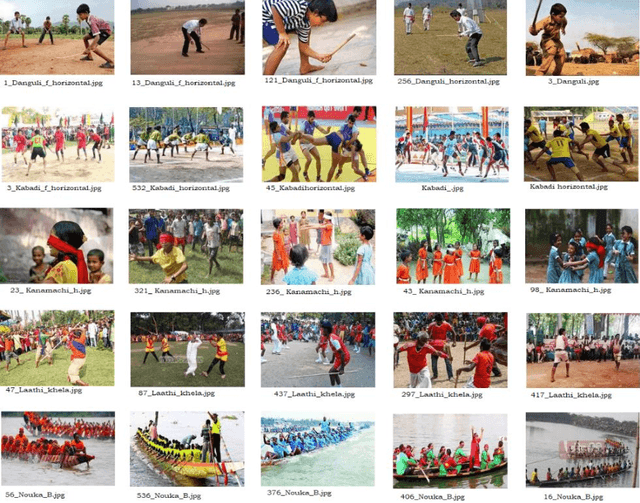
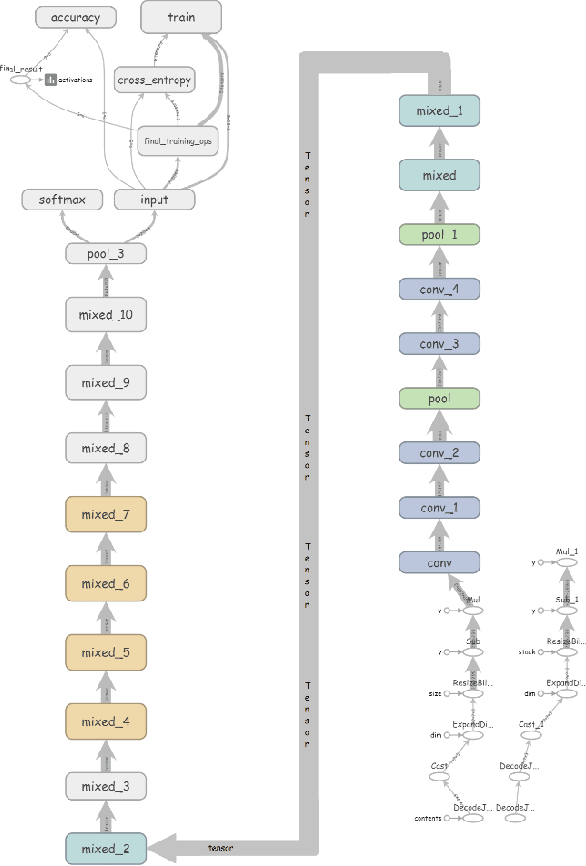
Sports activities are an integral part of our day to day life. Introducing autonomous decision making and predictive models to recognize and analyze different sports events and activities has become an emerging trend in computer vision arena. Albeit the advances and vivid applications of artificial intelligence and computer vision in recognizing different popular western games, there remains a very minimal amount of efforts in the application of computer vision in recognizing traditional Bangladeshi games. We, in this paper, have described a novel Deep Learning based approach for recognizing traditional Bengali games. We have retrained the final layer of the renowned Inception V3 architecture developed by Google for our classification approach. Our approach shows promising results with an average accuracy of 80% approximately in correctly recognizing among 5 traditional Bangladeshi sports events.
Incept-N: A Convolutional Neural Network based Classification Approach for Predicting Nationality from Facial Features
May 18, 2018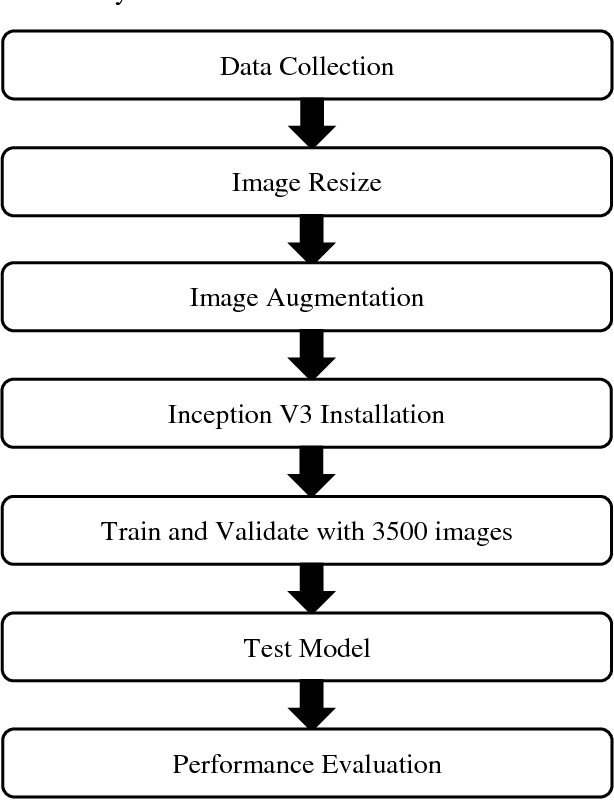

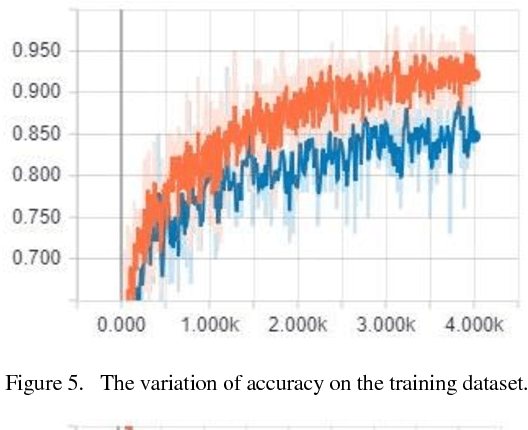
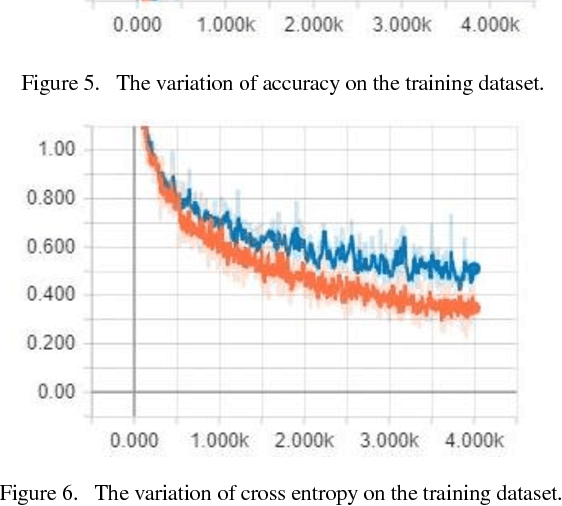
The nationality of a human being is a well-known identifying characteristic used for every major authentication purpose in every country. Albeit advances in the application of Artificial Intelligence and Computer Vision in different aspects, its contribution to this specific security procedure is yet to be cultivated. With a goal to successfully applying computer vision techniques to predict the nationality of a person based on his facial features, we have proposed this novel method and have achieved an average of 93.6% accuracy with very low misclassification rate.
Crick-net: A Convolutional Neural Network based Classification Approach for Detecting Waist High No Balls in Cricket
May 15, 2018



Cricket is undoubtedly one of the most popular games in this modern era. As human beings are prone to error, there remains a constant need for automated analysis and decision making of different events in this game. Simultaneously, with advent and advances in Artificial Intelligence and Computer Vision, application of these two in different domains has become an emerging trend. Applying several computer vision techniques in analyzing different Cricket events and automatically coming into decisions has become popular in recent days. In this paper, we have deployed a CNN based classification method with Inception V3 in order to automatically detect and differentiate waist high no balls with fair balls. Our approach achieves an overall average accuracy of 88% with a fairly low cross-entropy value.