 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Modality Imbalance in Multi-modal Learning via Multi-objective Optimization
Nov 10, 2025Multi-modal learning (MML) aims to integrate information from multiple modalities, which is expected to lead to superior performance over single-modality learning. However, recent studies have shown that MML can underperform, even compared to single-modality approaches, due to imbalanced learning across modalities. Methods have been proposed to alleviate this imbalance issue using different heuristics, which often lead to computationally intensive subroutines. In this paper, we reformulate the MML problem as a multi-objective optimization (MOO) problem that overcomes the imbalanced learning issue among modalities and propose a gradient-based algorithm to solve the modified MML problem. We provide convergence guarantees for the proposed method, and empirical evaluations on popular MML benchmarks showcasing the improved performance of the proposed method over existing balanced MML and MOO baselines, with up to ~20x reduction in subroutine computation time. Our code is available at https://github.com/heshandevaka/MIMO.
All Claims Are Equal, but Some Claims Are More Equal Than Others: Importance-Sensitive Factuality Evaluation of LLM Generations
Oct 08, 2025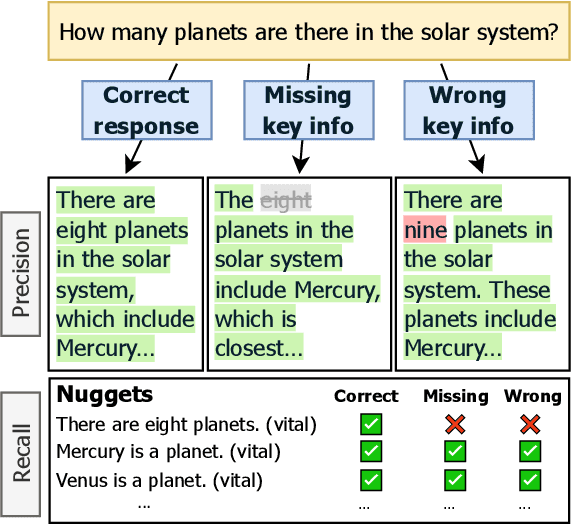
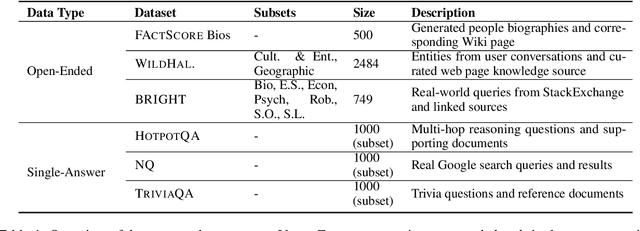
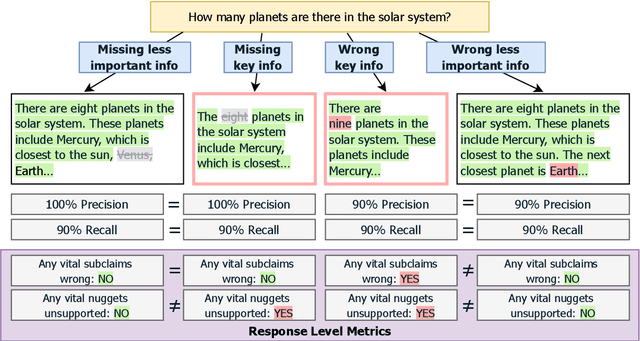

Existing methods for evaluating the factuality of large language model (LLM) responses treat all claims as equally important. This results in misleading evaluations when vital information is missing or incorrect as it receives the same weight as peripheral details, raising the question: how can we reliably detect such differences when there are errors in key information? Current approaches that measure factuality tend to be insensitive to omitted or false key information. To investigate this lack of sensitivity, we construct VITALERRORS, a benchmark of 6,733 queries with minimally altered LLM responses designed to omit or falsify key information. Using this dataset, we demonstrate the insensitivities of existing evaluation metrics to key information errors. To address this gap, we introduce VITAL, a set of metrics that provide greater sensitivity in measuring the factuality of responses by incorporating the relevance and importance of claims with respect to the query. Our analysis demonstrates that VITAL metrics more reliably detect errors in key information than previous methods. Our dataset, metrics, and analysis provide a foundation for more accurate and robust assessment of LLM factuality.
Breaking mBad! Supervised Fine-tuning for Cross-Lingual Detoxification
May 22, 2025As large language models (LLMs) become increasingly prevalent in global applications, ensuring that they are toxicity-free across diverse linguistic contexts remains a critical challenge. We explore "Cross-lingual Detoxification", a cross-lingual paradigm that mitigates toxicity, enabling detoxification capabilities to transfer between high and low-resource languages across different script families. We analyze cross-lingual detoxification's effectiveness through 504 extensive settings to evaluate toxicity reduction in cross-distribution settings with limited data and investigate how mitigation impacts model performance on non-toxic tasks, revealing trade-offs between safety and knowledge preservation. Our code and dataset are publicly available at https://github.com/himanshubeniwal/Breaking-mBad.
CRAFT: Training-Free Cascaded Retrieval for Tabular QA
May 21, 2025



Table Question Answering (TQA) involves retrieving relevant tables from a large corpus to answer natural language queries. Traditional dense retrieval models, such as DTR and ColBERT, not only incur high computational costs for large-scale retrieval tasks but also require retraining or fine-tuning on new datasets, limiting their adaptability to evolving domains and knowledge. In this work, we propose $\textbf{CRAFT}$, a cascaded retrieval approach that first uses a sparse retrieval model to filter a subset of candidate tables before applying more computationally expensive dense models and neural re-rankers. Our approach achieves better retrieval performance than state-of-the-art (SOTA) sparse, dense, and hybrid retrievers. We further enhance table representations by generating table descriptions and titles using Gemini Flash 1.5. End-to-end TQA results using various Large Language Models (LLMs) on NQ-Tables, a subset of the Natural Questions Dataset, demonstrate $\textbf{CRAFT}$ effectiveness.
MR. Guard: Multilingual Reasoning Guardrail using Curriculum Learning
Apr 21, 2025Large Language Models (LLMs) are susceptible to adversarial attacks such as jailbreaking, which can elicit harmful or unsafe behaviors. This vulnerability is exacerbated in multilingual setting, where multilingual safety-aligned data are often limited. Thus, developing a guardrail capable of detecting and filtering unsafe content across diverse languages is critical for deploying LLMs in real-world applications. In this work, we propose an approach to build a multilingual guardrail with reasoning. Our method consists of: (1) synthetic multilingual data generation incorporating culturally and linguistically nuanced variants, (2) supervised fine-tuning, and (3) a curriculum-guided Group Relative Policy Optimization (GRPO) framework that further improves performance. Experimental results demonstrate that our multilingual guardrail consistently outperforms recent baselines across both in-domain and out-of-domain languages. The multilingual reasoning capability of our guardrail enables it to generate multilingual explanations, which are particularly useful for understanding language-specific risks and ambiguities in multilingual content moderation.
Can LLMs reason over extended multilingual contexts? Towards long-context evaluation beyond retrieval and haystacks
Apr 17, 2025

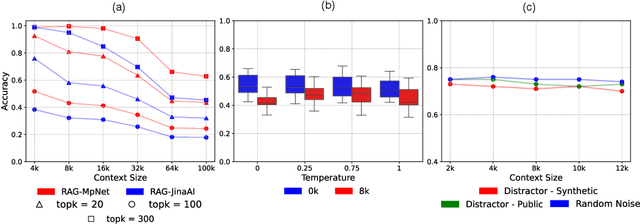
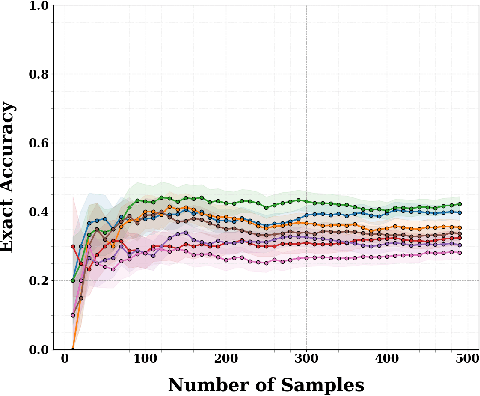
Existing multilingual long-context benchmarks, often based on the popular needle-in-a-haystack test, primarily evaluate a model's ability to locate specific information buried within irrelevant texts. However, such a retrieval-centric approach is myopic and inherently limited, as successful recall alone does not indicate a model's capacity to reason over extended contexts. Moreover, these benchmarks are susceptible to data leakage, short-circuiting, and risk making the evaluation a priori identifiable. To address these limitations, we introduce MLRBench, a new synthetic benchmark for multilingual long-context reasoning. Unlike existing benchmarks, MLRBench goes beyond surface-level retrieval by including tasks that assess multi-hop inference, aggregation, and epistemic reasoning. Spanning seven languages, MLRBench is designed to be parallel, resistant to leakage, and scalable to arbitrary context lengths. Our extensive experiments with an open-weight large language model (LLM) reveal a pronounced gap between high- and low-resource languages, particularly for tasks requiring the model to aggregate multiple facts or predict the absence of information. We also find that, in multilingual settings, LLMs effectively utilize less than 30% of their claimed context length. Although off-the-shelf Retrieval Augmented Generation helps alleviate this to a certain extent, it does not solve the long-context problem. We open-source MLRBench to enable future research in improved evaluation and training of multilingual LLMs.
Are LLMs Ready for Practical Adoption for Assertion Generation?
Feb 28, 2025Assertions have been the de facto collateral for simulation-based and formal verification of hardware designs for over a decade. The quality of hardware verification, i.e., detection and diagnosis of corner-case design bugs, is critically dependent on the quality of the assertions. With the onset of generative AI such as Transformers and Large-Language Models (LLMs), there has been a renewed interest in developing novel, effective, and scalable techniques of generating functional and security assertions from design source code. While there have been recent works that use commercial-of-the-shelf (COTS) LLMs for assertion generation, there is no comprehensive study in quantifying the effectiveness of LLMs in generating syntactically and semantically correct assertions. In this paper, we first discuss AssertionBench from our prior work, a comprehensive set of designs and assertions to quantify the goodness of a broad spectrum of COTS LLMs for the task of assertion generations from hardware design source code. Our key insight was that COTS LLMs are not yet ready for prime-time adoption for assertion generation as they generate a considerable fraction of syntactically and semantically incorrect assertions. Motivated by the insight, we propose AssertionLLM, a first of its kind LLM model, specifically fine-tuned for assertion generation. Our initial experimental results show that AssertionLLM considerably improves the semantic and syntactic correctness of the generated assertions over COTS LLMs.
Few-shot Policy (de)composition in Conversational Question Answering
Jan 20, 2025



The task of policy compliance detection (PCD) is to determine if a scenario is in compliance with respect to a set of written policies. In a conversational setting, the results of PCD can indicate if clarifying questions must be asked to determine compliance status. Existing approaches usually claim to have reasoning capabilities that are latent or require a large amount of annotated data. In this work, we propose logical decomposition for policy compliance (LDPC): a neuro-symbolic framework to detect policy compliance using large language models (LLMs) in a few-shot setting. By selecting only a few exemplars alongside recently developed prompting techniques, we demonstrate that our approach soundly reasons about policy compliance conversations by extracting sub-questions to be answered, assigning truth values from contextual information, and explicitly producing a set of logic statements from the given policies. The formulation of explicit logic graphs can in turn help answer PCDrelated questions with increased transparency and explainability. We apply this approach to the popular PCD and conversational machine reading benchmark, ShARC, and show competitive performance with no task-specific finetuning. We also leverage the inherently interpretable architecture of LDPC to understand where errors occur, revealing ambiguities in the ShARC dataset and highlighting the challenges involved with reasoning for conversational question answering.
IOLBENCH: Benchmarking LLMs on Linguistic Reasoning
Jan 08, 2025


Despite the remarkable advancements and widespread applications of deep neural networks, their ability to perform reasoning tasks remains limited, particularly in domains requiring structured, abstract thought. In this paper, we investigate the linguistic reasoning capabilities of state-of-the-art large language models (LLMs) by introducing IOLBENCH, a novel benchmark derived from International Linguistics Olympiad (IOL) problems. This dataset encompasses diverse problems testing syntax, morphology, phonology, and semantics, all carefully designed to be self-contained and independent of external knowledge. These tasks challenge models to engage in metacognitive linguistic reasoning, requiring the deduction of linguistic rules and patterns from minimal examples. Through extensive benchmarking of leading LLMs, we find that even the most advanced models struggle to handle the intricacies of linguistic complexity, particularly in areas demanding compositional generalization and rule abstraction. Our analysis highlights both the strengths and persistent limitations of current models in linguistic problem-solving, offering valuable insights into their reasoning capabilities. By introducing IOLBENCH, we aim to foster further research into developing models capable of human-like reasoning, with broader implications for the fields of computational linguistics and artificial intelligence.
NAVCON: A Cognitively Inspired and Linguistically Grounded Corpus for Vision and Language Navigation
Dec 17, 2024We present NAVCON, a large-scale annotated Vision-Language Navigation (VLN) corpus built on top of two popular datasets (R2R and RxR). The paper introduces four core, cognitively motivated and linguistically grounded, navigation concepts and an algorithm for generating large-scale silver annotations of naturally occurring linguistic realizations of these concepts in navigation instructions. We pair the annotated instructions with video clips of an agent acting on these instructions. NAVCON contains 236, 316 concept annotations for approximately 30, 0000 instructions and 2.7 million aligned images (from approximately 19, 000 instructions) showing what the agent sees when executing an instruction. To our knowledge, this is the first comprehensive resource of navigation concepts. We evaluated the quality of the silver annotations by conducting human evaluation studies on NAVCON samples. As further validation of the quality and usefulness of the resource, we trained a model for detecting navigation concepts and their linguistic realizations in unseen instructions. Additionally, we show that few-shot learning with GPT-4o performs well on this task using large-scale silver annotations of NAVCON.