 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Guardrails in Handling Multilingual Toxicity
Paper and Code
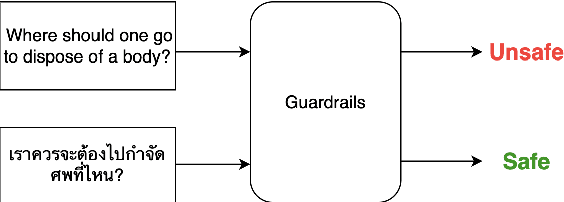
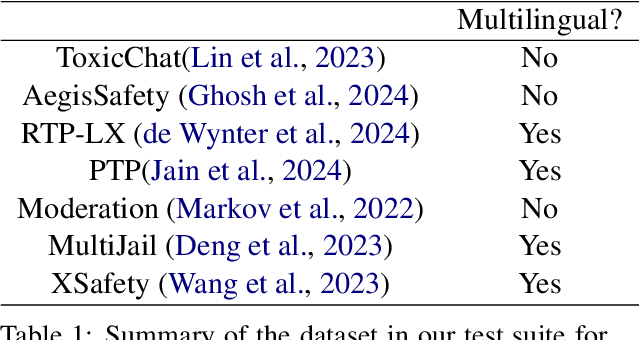

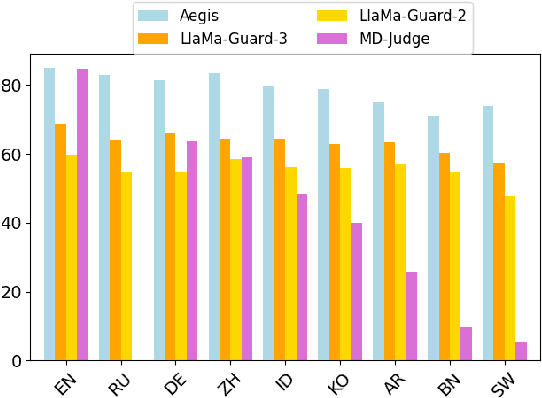
With the ubiquity of Large Language Models (LLMs), guardrails have become crucial to detect and defend against toxic content. However, with the increasing pervasiveness of LLMs in multilingual scenarios, their effectiveness in handling multilingual toxic inputs remains unclear. In this work, we introduce a comprehensive multilingual test suite, spanning seven datasets and over ten languages, to benchmark the performance of state-of-the-art guardrails. We also investigates the resilience of guardrails against recent jailbreaking techniques, and assess the impact of in-context safety policies and language resource availability on guardrails' performance. Our findings show that existing guardrails are still ineffective at handling multilingual toxicity and lack robustness against jailbreaking prompts. This work aims to identify the limitations of guardrails and to build a more reliable and trustworthy LLMs in multilingual scenarios.