 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolicy-Guided Stepwise Model Routing for Cost-Effective Reasoning
May 07, 2026Inference-time computation has greatly enhanced the performance of large language models (LLMs) on challenging reasoning tasks, but this strategy can incur high inference costs. One solution is to route intermediate chain-of-thought (CoT) states to language models of different sizes; however, existing approaches rely on handcrafted routing strategies that limit performance, or on training large process reward models that may be infeasible in many applications. We formulate stepwise model routing as a constrained decision-making problem, which we solve by training a small control policy using reinforcement learning in conjunction with threshold calibration to tune the performance-efficiency tradeoff. We validate our method on three math benchmarks (GSM8K, MATH500, and OmniMath) on both open and closed models. Our method consistently improves the accuracy-cost tradeoff compared to handcrafted approaches, while achieving a comparable tradeoff to methods that require training large process reward models.
SafeGen-LLM: Enhancing Safety Generalization in Task Planning for Robotic Systems
Feb 27, 2026Safety-critical task planning in robotic systems remains challenging: classical planners suffer from poor scalability, Reinforcement Learning (RL)-based methods generalize poorly, and base Large Language Models (LLMs) cannot guarantee safety. To address this gap, we propose safety-generalizable large language models, named SafeGen-LLM. SafeGen-LLM can not only enhance the safety satisfaction of task plans but also generalize well to novel safety properties in various domains. We first construct a multi-domain Planning Domain Definition Language 3 (PDDL3) benchmark with explicit safety constraints. Then, we introduce a two-stage post-training framework: Supervised Fine-Tuning (SFT) on a constraint-compliant planning dataset to learn planning syntax and semantics, and Group Relative Policy Optimization (GRPO) guided by fine-grained reward machines derived from formal verification to enforce safety alignment and by curriculum learning to better handle complex tasks. Extensive experiments show that SafeGen-LLM achieves strong safety generalization and outperforms frontier proprietary baselines across multi-domain planning tasks and multiple input formats (e.g., PDDLs and natural language).
Pattern-Guided Diffusion Models
Dec 15, 2025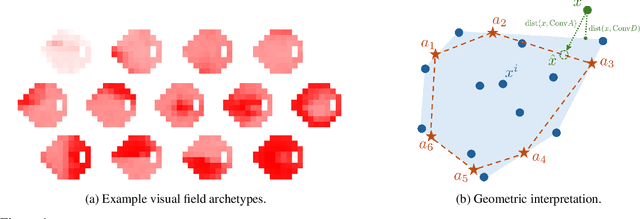
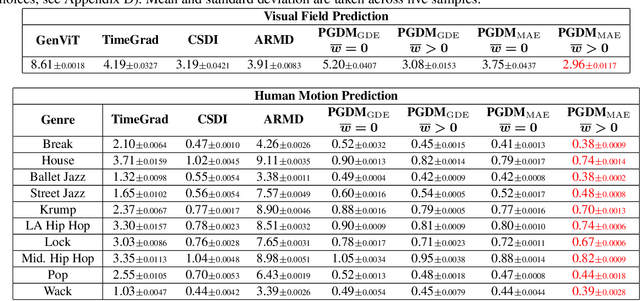
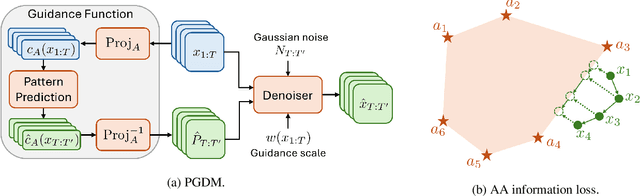
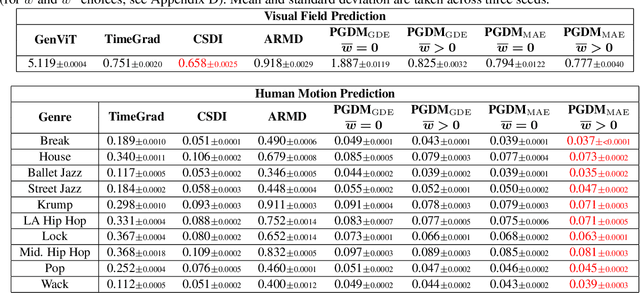
Diffusion models have shown promise in forecasting future data from multivariate time series. However, few existing methods account for recurring structures, or patterns, that appear within the data. We present Pattern-Guided Diffusion Models (PGDM), which leverage inherent patterns within temporal data for forecasting future time steps. PGDM first extracts patterns using archetypal analysis and estimates the most likely next pattern in the sequence. By guiding predictions with this pattern estimate, PGDM makes more realistic predictions that fit within the set of known patterns. We additionally introduce a novel uncertainty quantification technique based on archetypal analysis, and we dynamically scale the guidance level based on the pattern estimate uncertainty. We apply our method to two well-motivated forecasting applications, predicting visual field measurements and motion capture frames. On both, we show that pattern guidance improves PGDM's performance (MAE / CRPS) by up to 40.67% / 56.26% and 14.12% / 14.10%, respectively. PGDM also outperforms baselines by up to 65.58% / 84.83% and 93.64% / 92.55%.
Quantifying and Improving Adaptivity in Conformal Prediction through Input Transformations
Nov 17, 2025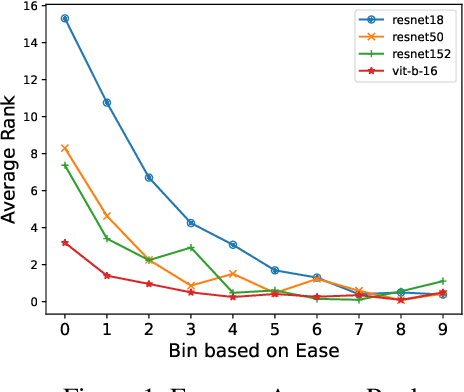
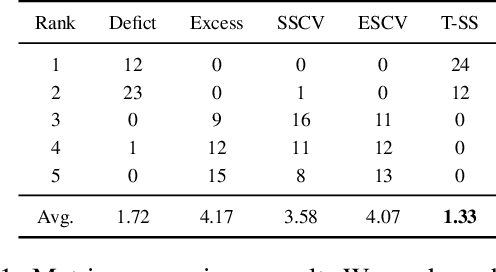
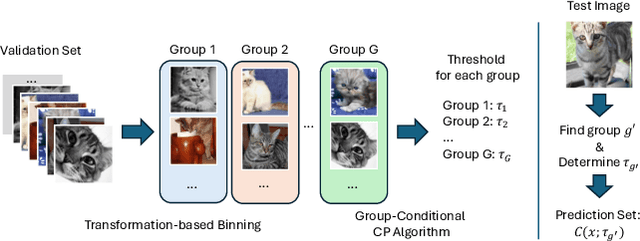
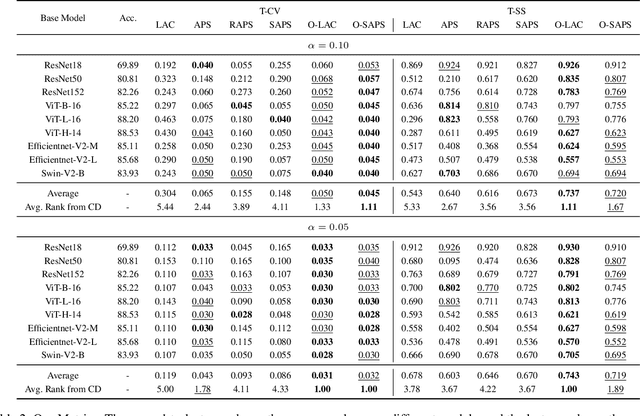
Conformal prediction constructs a set of labels instead of a single point prediction, while providing a probabilistic coverage guarantee. Beyond the coverage guarantee, adaptiveness to example difficulty is an important property. It means that the method should produce larger prediction sets for more difficult examples, and smaller ones for easier examples. Existing evaluation methods for adaptiveness typically analyze coverage rate violation or average set size across bins of examples grouped by difficulty. However, these approaches often suffer from imbalanced binning, which can lead to inaccurate estimates of coverage or set size. To address this issue, we propose a binning method that leverages input transformations to sort examples by difficulty, followed by uniform-mass binning. Building on this binning, we introduce two metrics to better evaluate adaptiveness. These metrics provide more reliable estimates of coverage rate violation and average set size due to balanced binning, leading to more accurate adaptivity assessment. Through experiments, we demonstrate that our proposed metric correlates more strongly with the desired adaptiveness property compared to existing ones. Furthermore, motivated by our findings, we propose a new adaptive prediction set algorithm that groups examples by estimated difficulty and applies group-conditional conformal prediction. This allows us to determine appropriate thresholds for each group. Experimental results on both (a) an Image Classification (ImageNet) (b) a medical task (visual acuity prediction) show that our method outperforms existing approaches according to the new metrics.
Conformal Constrained Policy Optimization for Cost-Effective LLM Agents
Nov 14, 2025While large language models (LLMs) have recently made tremendous progress towards solving challenging AI problems, they have done so at increasingly steep computational and API costs. We propose a novel strategy where we combine multiple LLM models with varying cost/accuracy tradeoffs in an agentic manner, where models and tools are run in sequence as determined by an orchestration model to minimize cost subject to a user-specified level of reliability; this constraint is formalized using conformal prediction to provide guarantees. To solve this problem, we propose Conformal Constrained Policy Optimization (CCPO), a training paradigm that integrates constrained policy optimization with off-policy reinforcement learning and recent advances in online conformal prediction. CCPO jointly optimizes a cost-aware policy (score function) and an adaptive threshold. Across two multi-hop question answering benchmarks, CCPO achieves up to a 30% cost reduction compared to other cost-aware baselines and LLM-guided methods without compromising reliability. Our approach provides a principled and practical framework for deploying LLM agents that are significantly more cost-effective while maintaining reliability.
Effective Reinforcement Learning for Reasoning in Language Models
May 22, 2025Reinforcement learning (RL) has emerged as a promising strategy for improving the reasoning capabilities of language models (LMs) in domains such as mathematics and coding. However, most modern RL algorithms were designed to target robotics applications, which differ significantly from LM reasoning. We analyze RL algorithm design decisions for LM reasoning, for both accuracy and computational efficiency, focusing on relatively small models due to computational constraints. Our findings are: (i) on-policy RL significantly outperforms supervised fine-tuning (SFT), (ii) PPO-based off-policy updates increase accuracy instead of reduce variance, and (iii) removing KL divergence can lead to more concise generations and higher accuracy. Furthermore, we find that a key bottleneck to computational efficiency is that the optimal batch sizes for inference and backpropagation are different. We propose a novel algorithm, DASH, that performs preemptive sampling (i.e., sample a large batch and accumulate gradient updates in small increments), and gradient filtering (i.e., drop samples with small advantage estimates). We show that DASH reduces training time by 83% compared to a standard implementation of GRPO without sacrificing accuracy. Our findings provide valuable insights on designing effective RL algorithms for LM reasoning.
MR. Guard: Multilingual Reasoning Guardrail using Curriculum Learning
Apr 21, 2025Large Language Models (LLMs) are susceptible to adversarial attacks such as jailbreaking, which can elicit harmful or unsafe behaviors. This vulnerability is exacerbated in multilingual setting, where multilingual safety-aligned data are often limited. Thus, developing a guardrail capable of detecting and filtering unsafe content across diverse languages is critical for deploying LLMs in real-world applications. In this work, we propose an approach to build a multilingual guardrail with reasoning. Our method consists of: (1) synthetic multilingual data generation incorporating culturally and linguistically nuanced variants, (2) supervised fine-tuning, and (3) a curriculum-guided Group Relative Policy Optimization (GRPO) framework that further improves performance. Experimental results demonstrate that our multilingual guardrail consistently outperforms recent baselines across both in-domain and out-of-domain languages. The multilingual reasoning capability of our guardrail enables it to generate multilingual explanations, which are particularly useful for understanding language-specific risks and ambiguities in multilingual content moderation.
Monitor and Recover: A Paradigm for Future Research on Distribution Shift in Learning-Enabled Cyber-Physical Systems
Apr 18, 2025With the known vulnerability of neural networks to distribution shift, maintaining reliability in learning-enabled cyber-physical systems poses a salient challenge. In response, many existing methods adopt a detect and abstain methodology, aiming to detect distribution shift at inference time so that the learning-enabled component can abstain from decision-making. This approach, however, has limited use in real-world applications. We instead propose a monitor and recover paradigm as a promising direction for future research. This philosophy emphasizes 1) robust safety monitoring instead of distribution shift detection and 2) distribution shift recovery instead of abstention. We discuss two examples from our recent work.
Safety Monitoring for Learning-Enabled Cyber-Physical Systems in Out-of-Distribution Scenarios
Apr 18, 2025The safety of learning-enabled cyber-physical systems is compromised by the well-known vulnerabilities of deep neural networks to out-of-distribution (OOD) inputs. Existing literature has sought to monitor the safety of such systems by detecting OOD data. However, such approaches have limited utility, as the presence of an OOD input does not necessarily imply the violation of a desired safety property. We instead propose to directly monitor safety in a manner that is itself robust to OOD data. To this end, we predict violations of signal temporal logic safety specifications based on predicted future trajectories. Our safety monitor additionally uses a novel combination of adaptive conformal prediction and incremental learning. The former obtains probabilistic prediction guarantees even on OOD data, and the latter prevents overly conservative predictions. We evaluate the efficacy of the proposed approach in two case studies on safety monitoring: 1) predicting collisions of an F1Tenth car with static obstacles, and 2) predicting collisions of a race car with multiple dynamic obstacles. We find that adaptive conformal prediction obtains theoretical guarantees where other uncertainty quantification methods fail to do so. Additionally, combining adaptive conformal prediction and incremental learning for safety monitoring achieves high recall and timeliness while reducing loss in precision. We achieve these results even in OOD settings and outperform alternative methods.
Fundus Image-based Visual Acuity Assessment with PAC-Guarantees
Dec 09, 2024Timely detection and treatment are essential for maintaining eye health. Visual acuity (VA), which measures the clarity of vision at a distance, is a crucial metric for managing eye health. Machine learning (ML) techniques have been introduced to assist in VA measurement, potentially alleviating clinicians' workloads. However, the inherent uncertainties in ML models make relying solely on them for VA prediction less than ideal. The VA prediction task involves multiple sources of uncertainty, requiring more robust approaches. A promising method is to build prediction sets or intervals rather than point estimates, offering coverage guarantees through techniques like conformal prediction and Probably Approximately Correct (PAC) prediction sets. Despite the potential, to date, these approaches have not been applied to the VA prediction task.To address this, we propose a method for deriving prediction intervals for estimating visual acuity from fundus images with a PAC guarantee. Our experimental results demonstrate that the PAC guarantees are upheld, with performance comparable to or better than that of two prior works that do not provide such guarantees.