 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Weak Label Generation for Data Programming with Clinicians in the Loop
Jul 10, 2024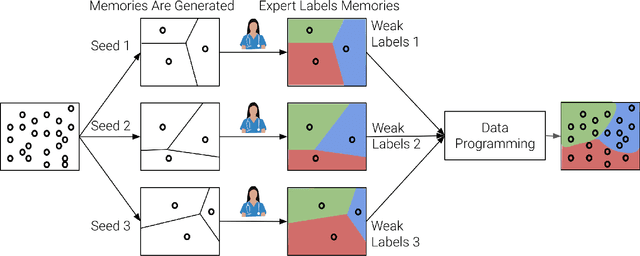
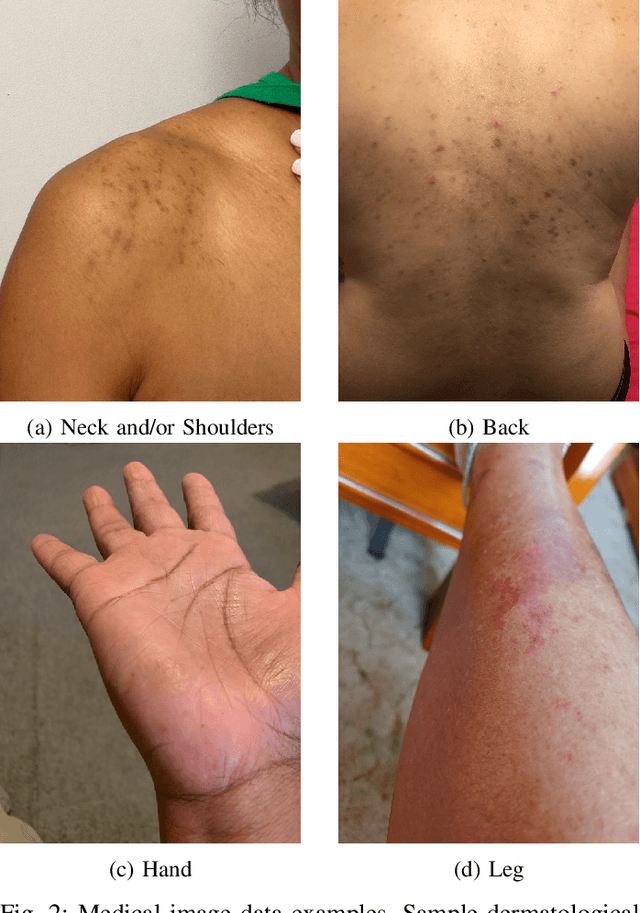
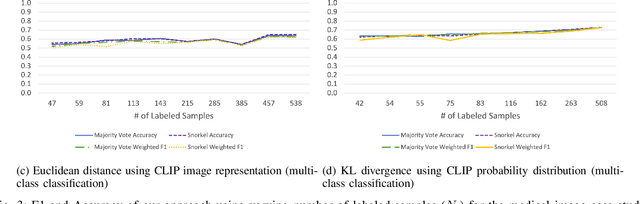
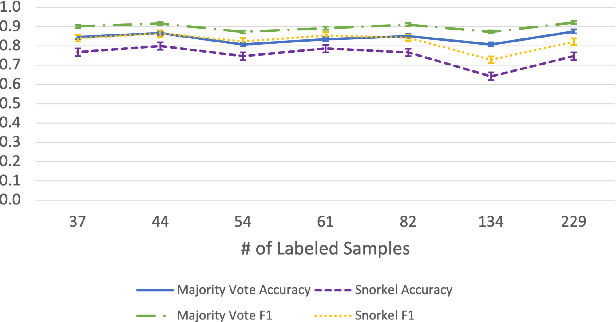
Large Deep Neural Networks (DNNs) are often data hungry and need high-quality labeled data in copious amounts for learning to converge. This is a challenge in the field of medicine since high quality labeled data is often scarce. Data programming has been the ray of hope in this regard, since it allows us to label unlabeled data using multiple weak labeling functions. Such functions are often supplied by a domain expert. Data-programming can combine multiple weak labeling functions and suggest labels better than simple majority voting over the different functions. However, it is not straightforward to express such weak labeling functions, especially in high-dimensional settings such as images and time-series data. What we propose in this paper is a way to bypass this issue, using distance functions. In high-dimensional spaces, it is easier to find meaningful distance metrics which can generalize across different labeling tasks. We propose an algorithm that queries an expert for labels of a few representative samples of the dataset. These samples are carefully chosen by the algorithm to capture the distribution of the dataset. The labels assigned by the expert on the representative subset induce a labeling on the full dataset, thereby generating weak labels to be used in the data programming pipeline. In our medical time series case study, labeling a subset of 50 to 130 out of 3,265 samples showed 17-28% improvement in accuracy and 13-28% improvement in F1 over the baseline using clinician-defined labeling functions. In our medical image case study, labeling a subset of about 50 to 120 images from 6,293 unlabeled medical images using our approach showed significant improvement over the baseline method, Snuba, with an increase of approximately 5-15% in accuracy and 12-19% in F1 score.
Curating Naturally Adversarial Datasets for Trustworthy AI in Healthcare
Sep 01, 2023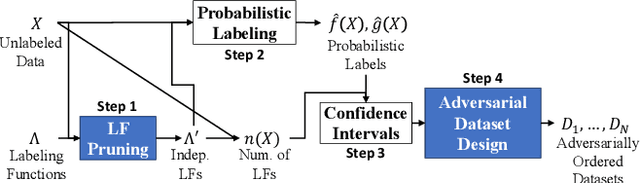


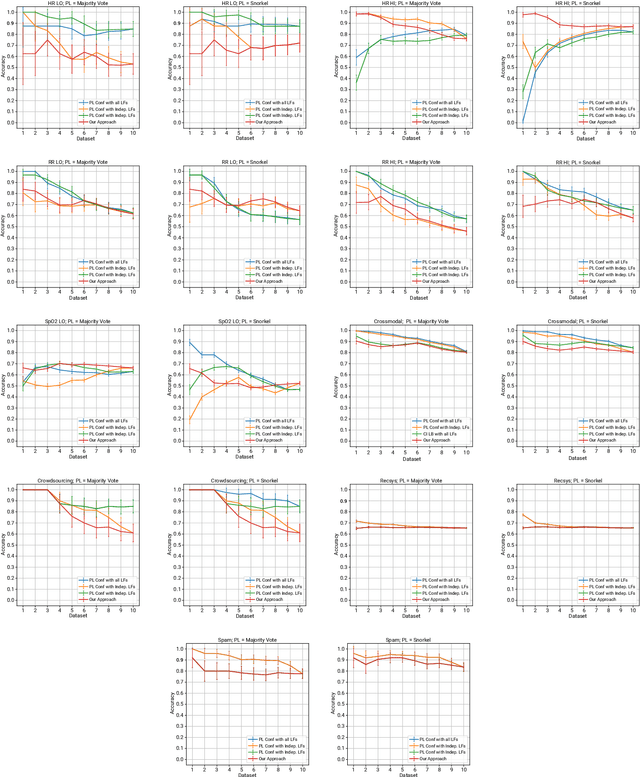
Deep learning models have shown promising predictive accuracy for time-series healthcare applications. However, ensuring the robustness of these models is vital for building trustworthy AI systems. Existing research predominantly focuses on robustness to synthetic adversarial examples, crafted by adding imperceptible perturbations to clean input data. However, these synthetic adversarial examples do not accurately reflect the most challenging real-world scenarios, especially in the context of healthcare data. Consequently, robustness to synthetic adversarial examples may not necessarily translate to robustness against naturally occurring adversarial examples, which is highly desirable for trustworthy AI. We propose a method to curate datasets comprised of natural adversarial examples to evaluate model robustness. The method relies on probabilistic labels obtained from automated weakly-supervised labeling that combines noisy and cheap-to-obtain labeling heuristics. Based on these labels, our method adversarially orders the input data and uses this ordering to construct a sequence of increasingly adversarial datasets. Our evaluation on six medical case studies and three non-medical case studies demonstrates the efficacy and statistical validity of our approach to generating naturally adversarial datasets