 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMemory-Consistent Neural Networks for Imitation Learning
Oct 09, 2023Imitation learning considerably simplifies policy synthesis compared to alternative approaches by exploiting access to expert demonstrations. For such imitation policies, errors away from the training samples are particularly critical. Even rare slip-ups in the policy action outputs can compound quickly over time, since they lead to unfamiliar future states where the policy is still more likely to err, eventually causing task failures. We revisit simple supervised ``behavior cloning'' for conveniently training the policy from nothing more than pre-recorded demonstrations, but carefully design the model class to counter the compounding error phenomenon. Our ``memory-consistent neural network'' (MCNN) outputs are hard-constrained to stay within clearly specified permissible regions anchored to prototypical ``memory'' training samples. We provide a guaranteed upper bound for the sub-optimality gap induced by MCNN policies. Using MCNNs on 9 imitation learning tasks, with MLP, Transformer, and Diffusion backbones, spanning dexterous robotic manipulation and driving, proprioceptive inputs and visual inputs, and varying sizes and types of demonstration data, we find large and consistent gains in performance, validating that MCNNs are better-suited than vanilla deep neural networks for imitation learning applications. Website: https://sites.google.com/view/mcnn-imitation
Curating Naturally Adversarial Datasets for Trustworthy AI in Healthcare
Sep 01, 2023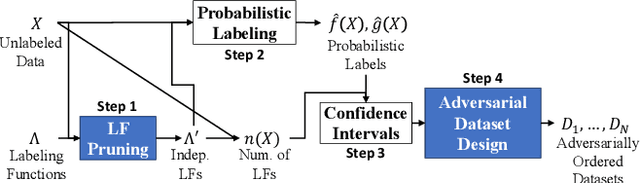


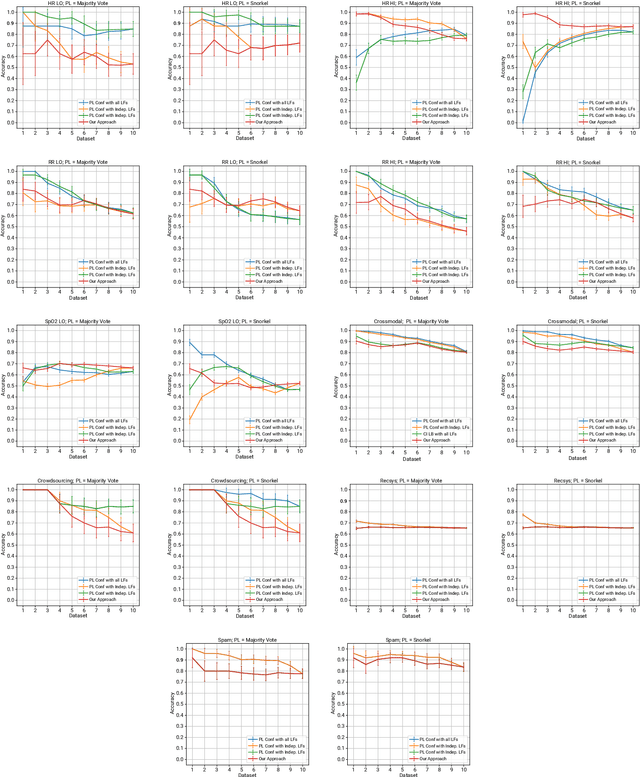
Deep learning models have shown promising predictive accuracy for time-series healthcare applications. However, ensuring the robustness of these models is vital for building trustworthy AI systems. Existing research predominantly focuses on robustness to synthetic adversarial examples, crafted by adding imperceptible perturbations to clean input data. However, these synthetic adversarial examples do not accurately reflect the most challenging real-world scenarios, especially in the context of healthcare data. Consequently, robustness to synthetic adversarial examples may not necessarily translate to robustness against naturally occurring adversarial examples, which is highly desirable for trustworthy AI. We propose a method to curate datasets comprised of natural adversarial examples to evaluate model robustness. The method relies on probabilistic labels obtained from automated weakly-supervised labeling that combines noisy and cheap-to-obtain labeling heuristics. Based on these labels, our method adversarially orders the input data and uses this ordering to construct a sequence of increasingly adversarial datasets. Our evaluation on six medical case studies and three non-medical case studies demonstrates the efficacy and statistical validity of our approach to generating naturally adversarial datasets
Detection of Adversarial Physical Attacks in Time-Series Image Data
Apr 27, 2023



Deep neural networks (DNN) have become a common sensing modality in autonomous systems as they allow for semantically perceiving the ambient environment given input images. Nevertheless, DNN models have proven to be vulnerable to adversarial digital and physical attacks. To mitigate this issue, several detection frameworks have been proposed to detect whether a single input image has been manipulated by adversarial digital noise or not. In our prior work, we proposed a real-time detector, called VisionGuard (VG), for adversarial physical attacks against single input images to DNN models. Building upon that work, we propose VisionGuard* (VG), which couples VG with majority-vote methods, to detect adversarial physical attacks in time-series image data, e.g., videos. This is motivated by autonomous systems applications where images are collected over time using onboard sensors for decision-making purposes. We emphasize that majority-vote mechanisms are quite common in autonomous system applications (among many other applications), as e.g., in autonomous driving stacks for object detection. In this paper, we investigate, both theoretically and experimentally, how this widely used mechanism can be leveraged to enhance the performance of adversarial detectors. We have evaluated VG* on videos of both clean and physically attacked traffic signs generated by a state-of-the-art robust physical attack. We provide extensive comparative experiments against detectors that have been designed originally for out-of-distribution data and digitally attacked images.
Guaranteed Conformance of Neurosymbolic Models to Natural Constraints
Dec 09, 2022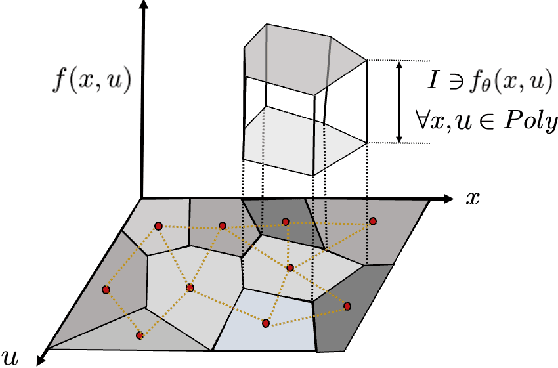
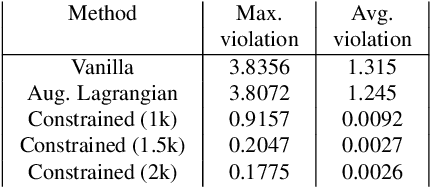
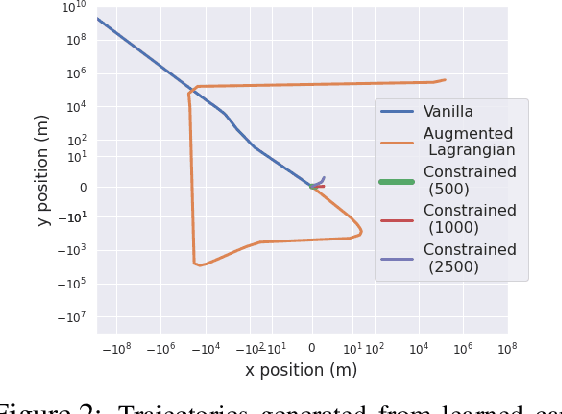
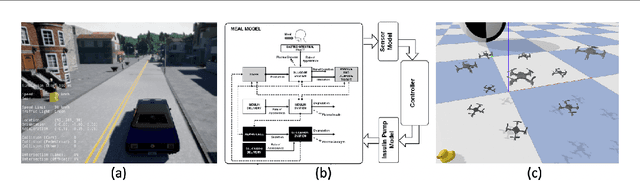
Deep neural networks have emerged as the workhorse for a large section of robotics and control applications, especially as models for dynamical systems. Such data-driven models are in turn used for designing and verifying autonomous systems. This is particularly useful in modeling medical systems where data can be leveraged to individualize treatment. In safety-critical applications, it is important that the data-driven model is conformant to established knowledge from the natural sciences. Such knowledge is often available or can often be distilled into a (possibly black-box) model $M$. For instance, the unicycle model for an F1 racing car. In this light, we consider the following problem - given a model $M$ and state transition dataset, we wish to best approximate the system model while being bounded distance away from $M$. We propose a method to guarantee this conformance. Our first step is to distill the dataset into few representative samples called memories, using the idea of a growing neural gas. Next, using these memories we partition the state space into disjoint subsets and compute bounds that should be respected by the neural network, when the input is drawn from a particular subset. This serves as a symbolic wrapper for guaranteed conformance. We argue theoretically that this only leads to bounded increase in approximation error; which can be controlled by increasing the number of memories. We experimentally show that on three case studies (Car Model, Drones, and Artificial Pancreas), our constrained neurosymbolic models conform to specified $M$ models (each encoding various constraints) with order-of-magnitude improvements compared to the augmented Lagrangian and vanilla training methods.
Towards Alternative Techniques for Improving Adversarial Robustness: Analysis of Adversarial Training at a Spectrum of Perturbations
Jun 13, 2022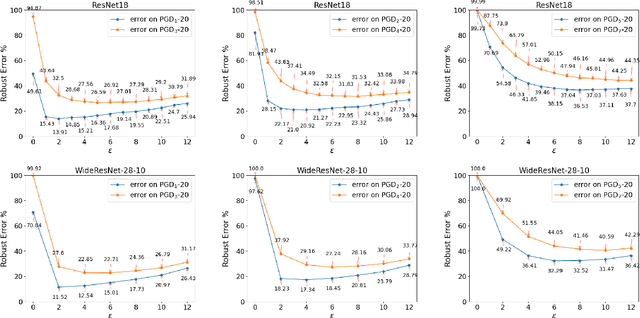
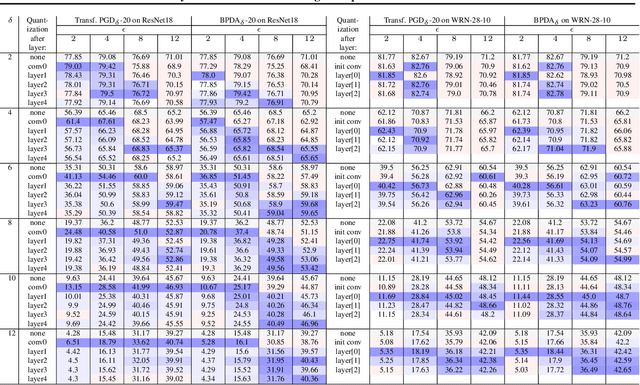
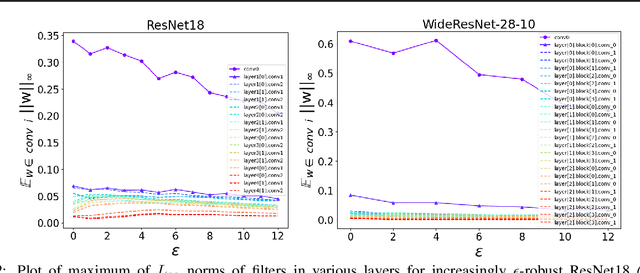
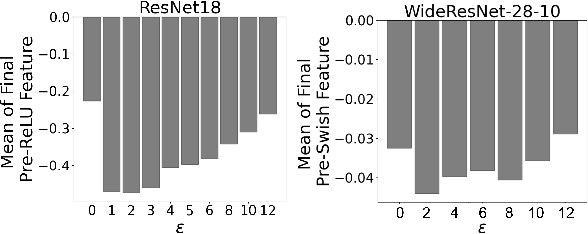
Adversarial training (AT) and its variants have spearheaded progress in improving neural network robustness to adversarial perturbations and common corruptions in the last few years. Algorithm design of AT and its variants are focused on training models at a specified perturbation strength $\epsilon$ and only using the feedback from the performance of that $\epsilon$-robust model to improve the algorithm. In this work, we focus on models, trained on a spectrum of $\epsilon$ values. We analyze three perspectives: model performance, intermediate feature precision and convolution filter sensitivity. In each, we identify alternative improvements to AT that otherwise wouldn't have been apparent at a single $\epsilon$. Specifically, we find that for a PGD attack at some strength $\delta$, there is an AT model at some slightly larger strength $\epsilon$, but no greater, that generalizes best to it. Hence, we propose overdesigning for robustness where we suggest training models at an $\epsilon$ just above $\delta$. Second, we observe (across various $\epsilon$ values) that robustness is highly sensitive to the precision of intermediate features and particularly those after the first and second layer. Thus, we propose adding a simple quantization to defenses that improves accuracy on seen and unseen adaptive attacks. Third, we analyze convolution filters of each layer of models at increasing $\epsilon$ and notice that those of the first and second layer may be solely responsible for amplifying input perturbations. We present our findings and demonstrate our techniques through experiments with ResNet and WideResNet models on the CIFAR-10 and CIFAR-10-C datasets.
Exploring with Sticky Mittens: Reinforcement Learning with Expert Interventions via Option Templates
Feb 25, 2022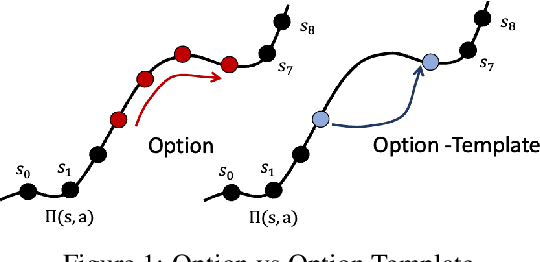
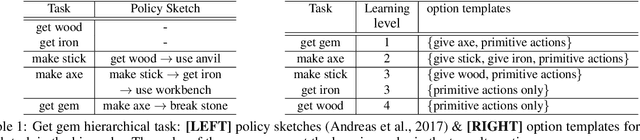
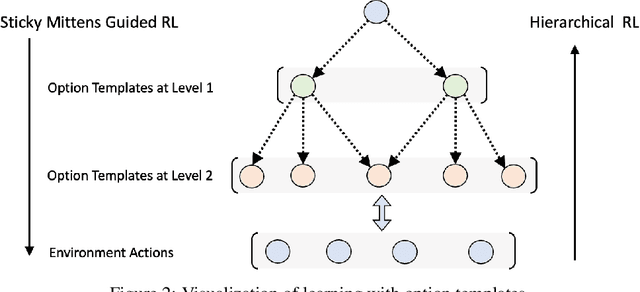
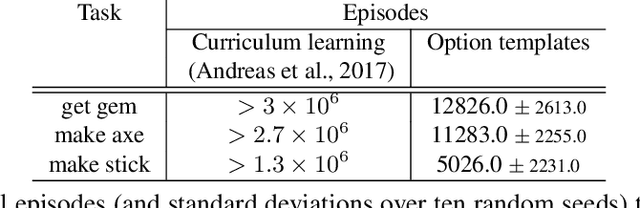
Environments with sparse rewards and long horizons pose a significant challenge for current reinforcement learning algorithms. A key feature enabling humans to learn challenging control tasks is that they often receive expert intervention that enables them to understand the high-level structure of the task before mastering low-level control actions. We propose a framework for leveraging expert intervention to solve long-horizon reinforcement learning tasks. We consider option templates, which are specifications encoding a potential option that can be trained using reinforcement learning. We formulate expert intervention as allowing the agent to execute option templates before learning an implementation. This enables them to use an option, before committing costly resources to learning it. We evaluate our approach on three challenging reinforcement learning problems, showing that it outperforms state of-the-art approaches by an order of magnitude. Project website at https://sites.google.com/view/stickymittens
CHEF: A Cheap and Fast Pipeline for Iteratively Cleaning Label Uncertainties
Jul 24, 2021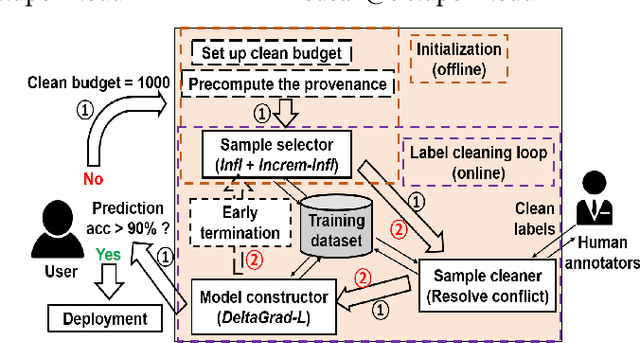


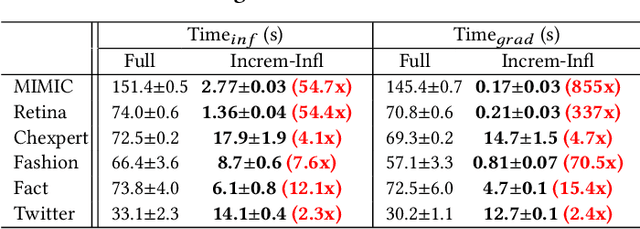
High-quality labels are expensive to obtain for many machine learning tasks, such as medical image classification tasks. Therefore, probabilistic (weak) labels produced by weak supervision tools are used to seed a process in which influential samples with weak labels are identified and cleaned by several human annotators to improve the model performance. To lower the overall cost and computational overhead of this process, we propose a solution called CHEF (CHEap and Fast label cleaning), which consists of the following three components. First, to reduce the cost of human annotators, we use Infl, which prioritizes the most influential training samples for cleaning and provides cleaned labels to save the cost of one human annotator. Second, to accelerate the sample selector phase and the model constructor phase, we use Increm-Infl to incrementally produce influential samples, and DeltaGrad-L to incrementally update the model. Third, we redesign the typical label cleaning pipeline so that human annotators iteratively clean smaller batch of samples rather than one big batch of samples. This yields better over all model performance and enables possible early termination when the expected model performance has been achieved. Extensive experiments show that our approach gives good model prediction performance while achieving significant speed-ups.
Robust Learning via Persistency of Excitation
Jun 11, 2021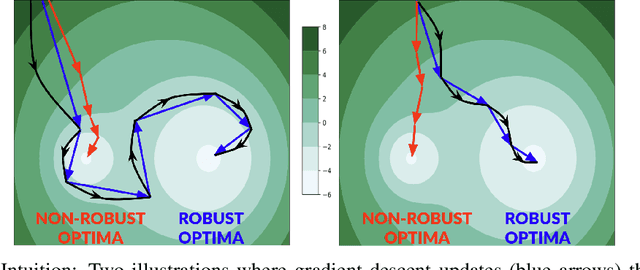
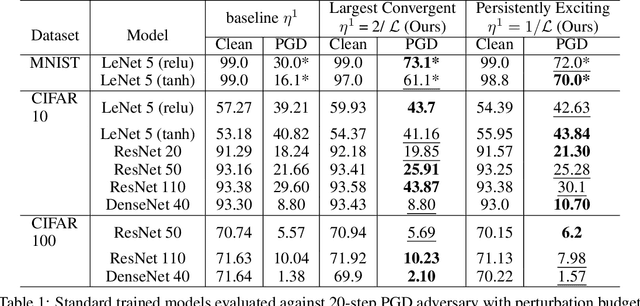
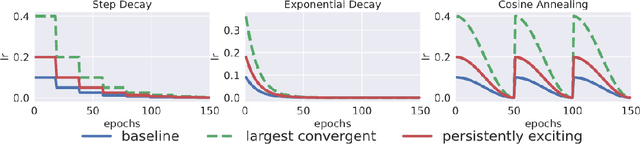
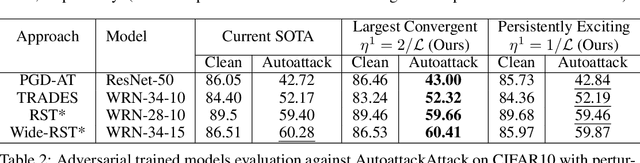
Improving adversarial robustness of neural networks remains a major challenge. Fundamentally, training a network is a parameter estimation problem. In adaptive control theory, maintaining persistency of excitation (PoE) is integral to ensuring convergence of parameter estimates in dynamical systems to their robust optima. In this work, we show that network training using gradient descent is equivalent to a dynamical system parameter estimation problem. Leveraging this relationship, we prove a sufficient condition for PoE of gradient descent is achieved when the learning rate is less than the inverse of the Lipschitz constant of the gradient of loss function. We provide an efficient technique for estimating the corresponding Lipschitz constant using extreme value theory and demonstrate that by only scaling the learning rate schedule we can increase adversarial accuracy by up to 15% points on benchmark datasets. Our approach also universally increases the adversarial accuracy by 0.1% to 0.3% points in various state-of-the-art adversarially trained models on the AutoAttack benchmark, where every small margin of improvement is significant.
ModelGuard: Runtime Validation of Lipschitz-continuous Models
Apr 30, 2021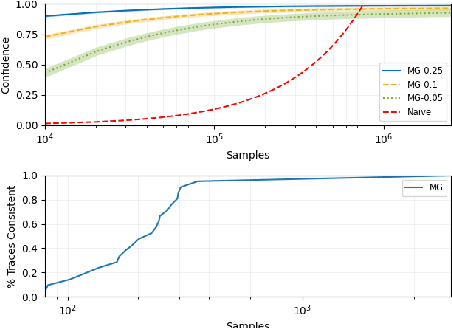


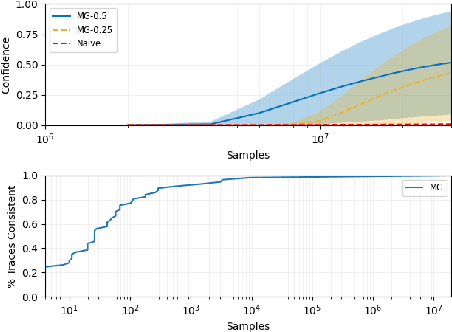
This paper presents ModelGuard, a sampling-based approach to runtime model validation for Lipschitz-continuous models. Although techniques exist for the validation of many classes of models the majority of these methods cannot be applied to the whole of Lipschitz-continuous models, which includes neural network models. Additionally, existing techniques generally consider only white-box models. By taking a sampling-based approach, we can address black-box models, represented only by an input-output relationship and a Lipschitz constant. We show that by randomly sampling from a parameter space and evaluating the model, it is possible to guarantee the correctness of traces labeled consistent and provide a confidence on the correctness of traces labeled inconsistent. We evaluate the applicability and scalability of ModelGuard in three case studies, including a physical platform.
Confidence Calibration with Bounded Error Using Transformations
Feb 25, 2021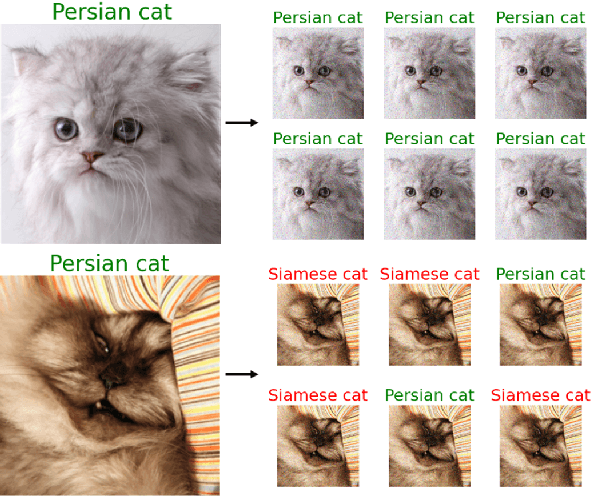
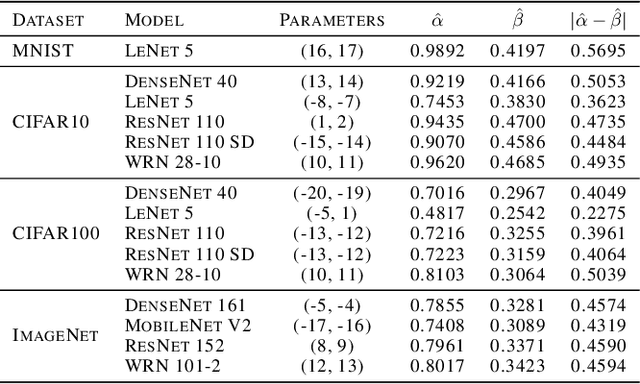


As machine learning techniques become widely adopted in new domains, especially in safety-critical systems such as autonomous vehicles, it is crucial to provide accurate output uncertainty estimation. As a result, many approaches have been proposed to calibrate neural networks to accurately estimate the likelihood of misclassification. However, while these methods achieve low expected calibration error (ECE), few techniques provide theoretical performance guarantees on the calibration error (CE). In this paper, we introduce Hoki, a novel calibration algorithm with a theoretical bound on the CE. Hoki works by transforming the neural network logits and/or inputs and recursively performing calibration leveraging the information from the corresponding change in the output. We provide a PAC-like bounds on CE that is shown to decrease with the number of samples used for calibration, and increase proportionally with ECE and the number of discrete bins used to calculate ECE. We perform experiments on multiple datasets, including ImageNet, and show that the proposed approach generally outperforms state-of-the-art calibration algorithms across multiple datasets and models - providing nearly an order or magnitude improvement in ECE on ImageNet. In addition, Hoki is fast algorithm which is comparable to temperature scaling in terms of learning time.