 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCHEF: A Cheap and Fast Pipeline for Iteratively Cleaning Label Uncertainties
Jul 24, 2021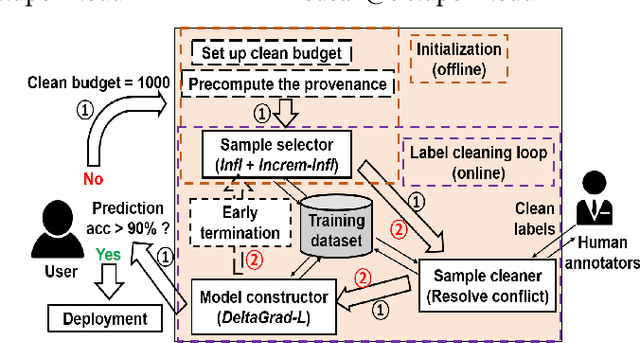


High-quality labels are expensive to obtain for many machine learning tasks, such as medical image classification tasks. Therefore, probabilistic (weak) labels produced by weak supervision tools are used to seed a process in which influential samples with weak labels are identified and cleaned by several human annotators to improve the model performance. To lower the overall cost and computational overhead of this process, we propose a solution called CHEF (CHEap and Fast label cleaning), which consists of the following three components. First, to reduce the cost of human annotators, we use Infl, which prioritizes the most influential training samples for cleaning and provides cleaned labels to save the cost of one human annotator. Second, to accelerate the sample selector phase and the model constructor phase, we use Increm-Infl to incrementally produce influential samples, and DeltaGrad-L to incrementally update the model. Third, we redesign the typical label cleaning pipeline so that human annotators iteratively clean smaller batch of samples rather than one big batch of samples. This yields better over all model performance and enables possible early termination when the expected model performance has been achieved. Extensive experiments show that our approach gives good model prediction performance while achieving significant speed-ups.
DeltaGrad: Rapid retraining of machine learning models
Jun 30, 2020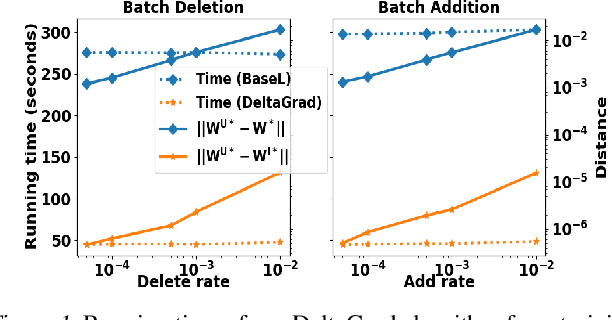
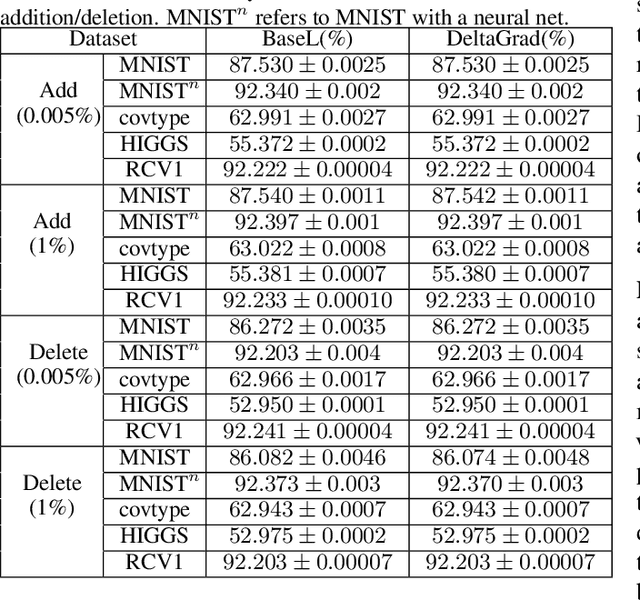

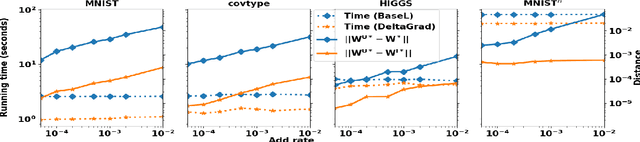
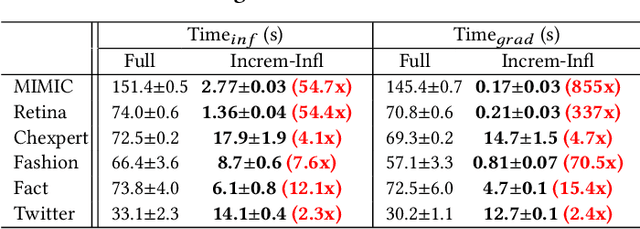
Machine learning models are not static and may need to be retrained on slightly changed datasets, for instance, with the addition or deletion of a set of data points. This has many applications, including privacy, robustness, bias reduction, and uncertainty quantifcation. However, it is expensive to retrain models from scratch. To address this problem, we propose the DeltaGrad algorithm for rapid retraining machine learning models based on information cached during the training phase. We provide both theoretical and empirical support for the effectiveness of DeltaGrad, and show that it compares favorably to the state of the art.
PrIU: A Provenance-Based Approach for Incrementally Updating Regression Models
Feb 26, 2020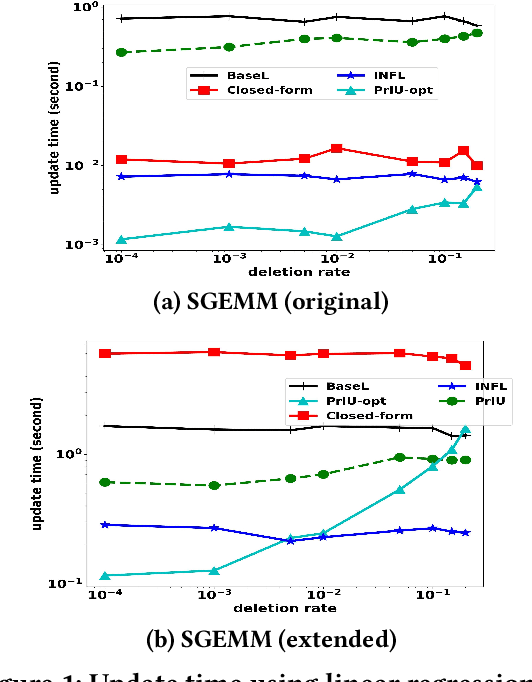
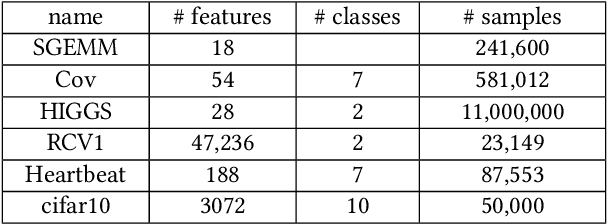
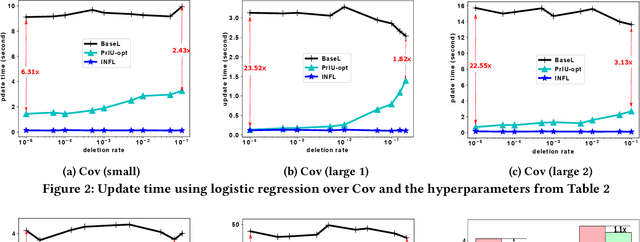
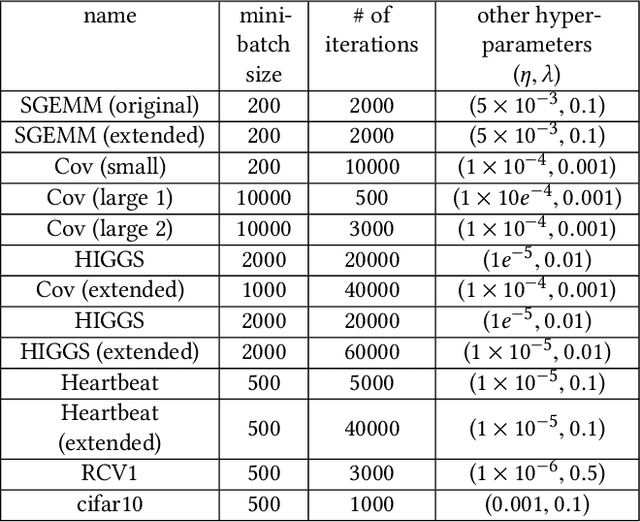
The ubiquitous use of machine learning algorithms brings new challenges to traditional database problems such as incremental view update. Much effort is being put in better understanding and debugging machine learning models, as well as in identifying and repairing errors in training datasets. Our focus is on how to assist these activities when they have to retrain the machine learning model after removing problematic training samples in cleaning or selecting different subsets of training data for interpretability. This paper presents an efficient provenance-based approach, PrIU, and its optimized version, PrIU-opt, for incrementally updating model parameters without sacrificing prediction accuracy. We prove the correctness and convergence of the incrementally updated model parameters, and validate it experimentally. Experimental results show that up to two orders of magnitude speed-ups can be achieved by PrIU-opt compared to simply retraining the model from scratch, yet obtaining highly similar models.