 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOQD: Performance-Oriented Query Decomposer for Multi-vector retrieval
May 25, 2025Although Multi-Vector Retrieval (MVR) has achieved the state of the art on many information retrieval (IR) tasks, its performance highly depends on how to decompose queries into smaller pieces, say phrases or tokens. However, optimizing query decomposition for MVR performance is not end-to-end differentiable. Even worse, jointly solving this problem and training the downstream retrieval-based systems, say RAG systems could be highly inefficient. To overcome these challenges, we propose Performance-Oriented Query Decomposer (POQD), a novel query decomposition framework for MVR. POQD leverages one LLM for query decomposition and searches the optimal prompt with an LLM-based optimizer. We further propose an end-to-end training algorithm to alternatively optimize the prompt for query decomposition and the downstream models. This algorithm can achieve superior MVR performance at a reasonable training cost as our theoretical analysis suggests. POQD can be integrated seamlessly into arbitrary retrieval-based systems such as Retrieval-Augmented Generation (RAG) systems. Extensive empirical studies on representative RAG-based QA tasks show that POQD outperforms existing query decomposition strategies in both retrieval performance and end-to-end QA accuracy. POQD is available at https://github.com/PKU-SDS-lab/POQD-ICML25.
Towards Compositionality in Concept Learning
Jun 26, 2024



Concept-based interpretability methods offer a lens into the internals of foundation models by decomposing their embeddings into high-level concepts. These concept representations are most useful when they are compositional, meaning that the individual concepts compose to explain the full sample. We show that existing unsupervised concept extraction methods find concepts which are not compositional. To automatically discover compositional concept representations, we identify two salient properties of such representations, and propose Compositional Concept Extraction (CCE) for finding concepts which obey these properties. We evaluate CCE on five different datasets over image and text data. Our evaluation shows that CCE finds more compositional concept representations than baselines and yields better accuracy on four downstream classification tasks. Code and data are available at https://github.com/adaminsky/compositional_concepts .
DISCRET: Synthesizing Faithful Explanations For Treatment Effect Estimation
Jun 02, 2024


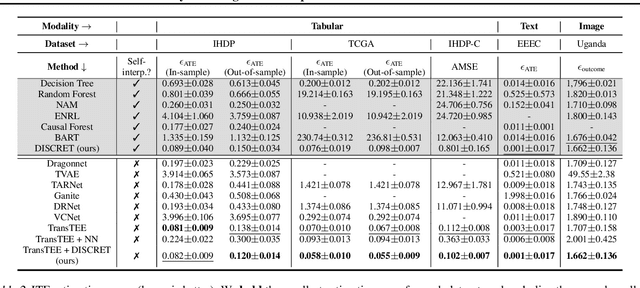
Designing faithful yet accurate AI models is challenging, particularly in the field of individual treatment effect estimation (ITE). ITE prediction models deployed in critical settings such as healthcare should ideally be (i) accurate, and (ii) provide faithful explanations. However, current solutions are inadequate: state-of-the-art black-box models do not supply explanations, post-hoc explainers for black-box models lack faithfulness guarantees, and self-interpretable models greatly compromise accuracy. To address these issues, we propose DISCRET, a self-interpretable ITE framework that synthesizes faithful, rule-based explanations for each sample. A key insight behind DISCRET is that explanations can serve dually as database queries to identify similar subgroups of samples. We provide a novel RL algorithm to efficiently synthesize these explanations from a large search space. We evaluate DISCRET on diverse tasks involving tabular, image, and text data. DISCRET outperforms the best self-interpretable models and has accuracy comparable to the best black-box models while providing faithful explanations. DISCRET is available at https://github.com/wuyinjun-1993/DISCRET-ICML2024.
MDB: Interactively Querying Datasets and Models
Aug 13, 2023As models are trained and deployed, developers need to be able to systematically debug errors that emerge in the machine learning pipeline. We present MDB, a debugging framework for interactively querying datasets and models. MDB integrates functional programming with relational algebra to build expressive queries over a database of datasets and model predictions. Queries are reusable and easily modified, enabling debuggers to rapidly iterate and refine queries to discover and characterize errors and model behaviors. We evaluate MDB on object detection, bias discovery, image classification, and data imputation tasks across self-driving videos, large language models, and medical records. Our experiments show that MDB enables up to 10x faster and 40\% shorter queries than other baselines. In a user study, we find developers can successfully construct complex queries that describe errors of machine learning models.
Rectifying Group Irregularities in Explanations for Distribution Shift
May 25, 2023It is well-known that real-world changes constituting distribution shift adversely affect model performance. How to characterize those changes in an interpretable manner is poorly understood. Existing techniques to address this problem take the form of shift explanations that elucidate how to map samples from the original distribution toward the shifted one by reducing the disparity between these two distributions. However, these methods can introduce group irregularities, leading to explanations that are less feasible and robust. To address these issues, we propose Group-aware Shift Explanations (GSE), a method that produces interpretable explanations by leveraging worst-group optimization to rectify group irregularities. We demonstrate how GSE not only maintains group structures, such as demographic and hierarchical subpopulations, but also enhances feasibility and robustness in the resulting explanations in a wide range of tabular, language, and image settings.
Do Machine Learning Models Learn Common Sense?
Mar 02, 2023



Machine learning models can make basic errors that are easily hidden within vast amounts of data. Such errors often run counter to human intuition referred to as "common sense". We thereby seek to characterize common sense for data-driven models, and quantify the extent to which a model has learned common sense. We propose a framework that integrates logic-based methods with statistical inference to derive common sense rules from a model's training data without supervision. We further show how to adapt models at test-time to reduce common sense rule violations and produce more coherent predictions. We evaluate our framework on datasets and models for three different domains. It generates around 250 to 300k rules over these datasets, and uncovers 1.5k to 26k violations of those rules by state-of-the-art models for the respective datasets. Test-time adaptation reduces these violations by up to 38% without impacting overall model accuracy.
Learning to Select Pivotal Samples for Meta Re-weighting
Feb 09, 2023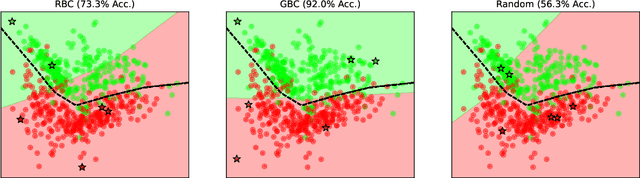
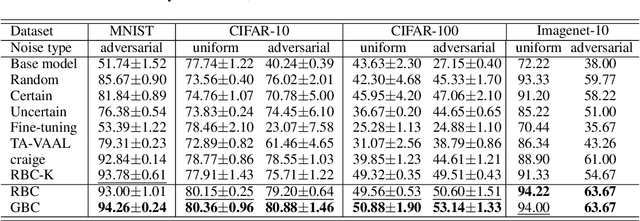
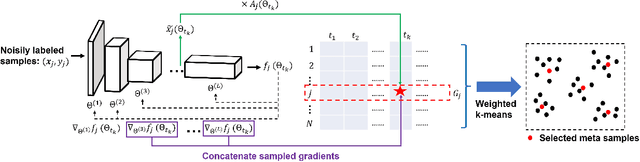
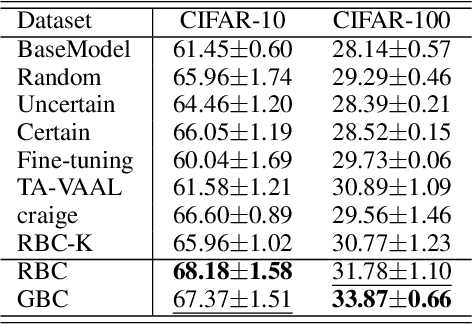
Sample re-weighting strategies provide a promising mechanism to deal with imperfect training data in machine learning, such as noisily labeled or class-imbalanced data. One such strategy involves formulating a bi-level optimization problem called the meta re-weighting problem, whose goal is to optimize performance on a small set of perfect pivotal samples, called meta samples. Many approaches have been proposed to efficiently solve this problem. However, all of them assume that a perfect meta sample set is already provided while we observe that the selections of meta sample set is performance critical. In this paper, we study how to learn to identify such a meta sample set from a large, imperfect training set, that is subsequently cleaned and used to optimize performance in the meta re-weighting setting. We propose a learning framework which reduces the meta samples selection problem to a weighted K-means clustering problem through rigorously theoretical analysis. We propose two clustering methods within our learning framework, Representation-based clustering method (RBC) and Gradient-based clustering method (GBC), for balancing performance and computational efficiency. Empirical studies demonstrate the performance advantage of our methods over various baseline methods.
CHEF: A Cheap and Fast Pipeline for Iteratively Cleaning Label Uncertainties
Jul 24, 2021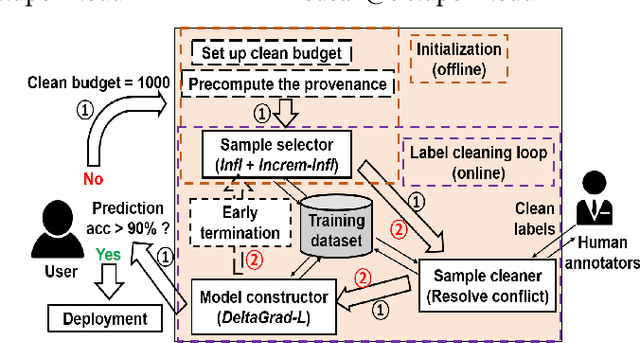


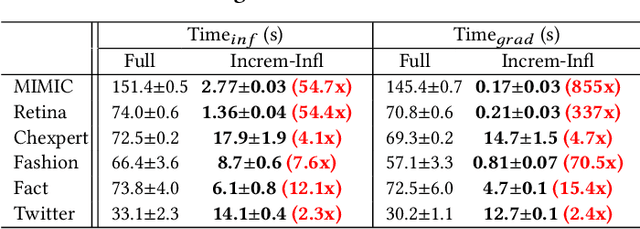
High-quality labels are expensive to obtain for many machine learning tasks, such as medical image classification tasks. Therefore, probabilistic (weak) labels produced by weak supervision tools are used to seed a process in which influential samples with weak labels are identified and cleaned by several human annotators to improve the model performance. To lower the overall cost and computational overhead of this process, we propose a solution called CHEF (CHEap and Fast label cleaning), which consists of the following three components. First, to reduce the cost of human annotators, we use Infl, which prioritizes the most influential training samples for cleaning and provides cleaned labels to save the cost of one human annotator. Second, to accelerate the sample selector phase and the model constructor phase, we use Increm-Infl to incrementally produce influential samples, and DeltaGrad-L to incrementally update the model. Third, we redesign the typical label cleaning pipeline so that human annotators iteratively clean smaller batch of samples rather than one big batch of samples. This yields better over all model performance and enables possible early termination when the expected model performance has been achieved. Extensive experiments show that our approach gives good model prediction performance while achieving significant speed-ups.
Dynamic Gaussian Mixture based Deep Generative Model For Robust Forecasting on Sparse Multivariate Time Series
Mar 03, 2021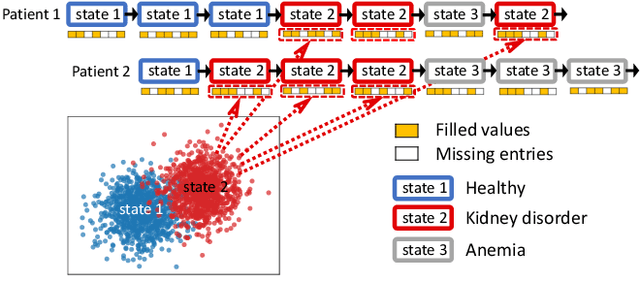
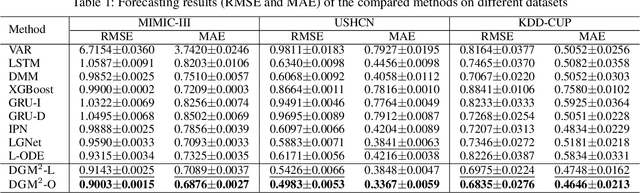
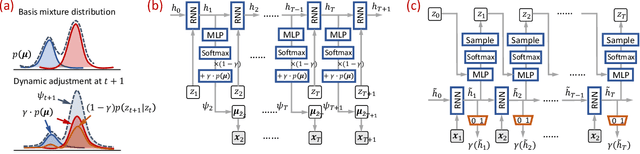
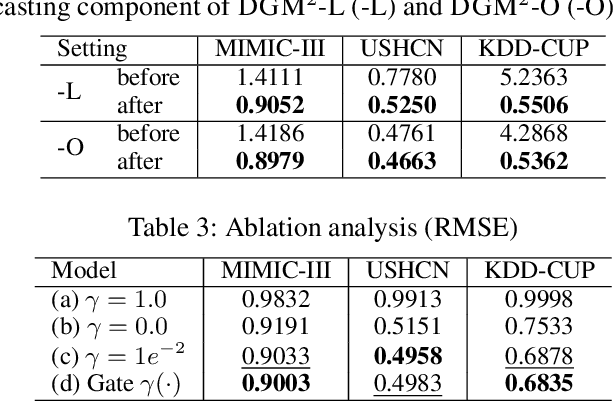
Forecasting on sparse multivariate time series (MTS) aims to model the predictors of future values of time series given their incomplete past, which is important for many emerging applications. However, most existing methods process MTS's individually, and do not leverage the dynamic distributions underlying the MTS's, leading to sub-optimal results when the sparsity is high. To address this challenge, we propose a novel generative model, which tracks the transition of latent clusters, instead of isolated feature representations, to achieve robust modeling. It is characterized by a newly designed dynamic Gaussian mixture distribution, which captures the dynamics of clustering structures, and is used for emitting timeseries. The generative model is parameterized by neural networks. A structured inference network is also designed for enabling inductive analysis. A gating mechanism is further introduced to dynamically tune the Gaussian mixture distributions. Extensive experimental results on a variety of real-life datasets demonstrate the effectiveness of our method.
DeltaGrad: Rapid retraining of machine learning models
Jun 30, 2020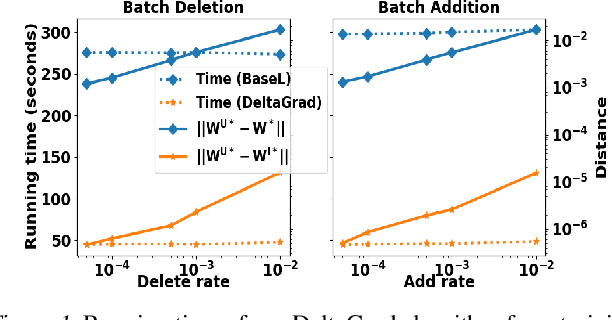
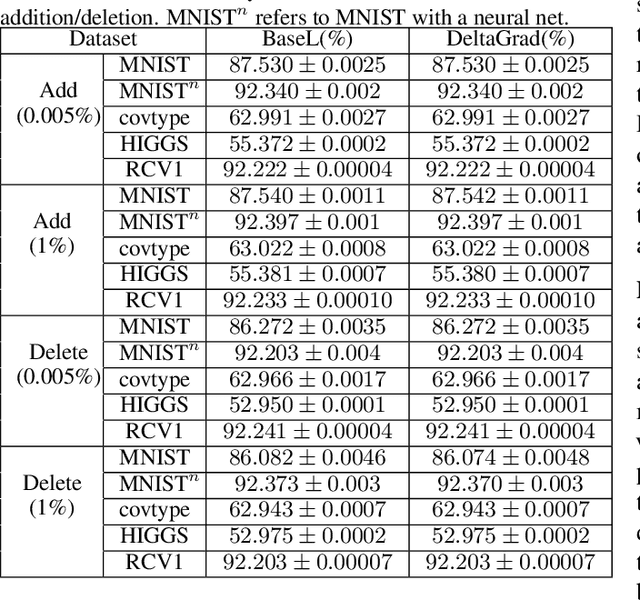

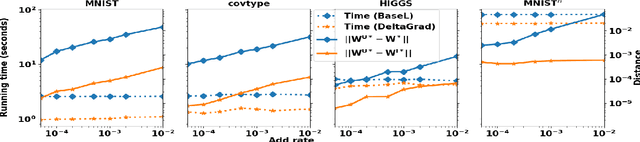
Machine learning models are not static and may need to be retrained on slightly changed datasets, for instance, with the addition or deletion of a set of data points. This has many applications, including privacy, robustness, bias reduction, and uncertainty quantifcation. However, it is expensive to retrain models from scratch. To address this problem, we propose the DeltaGrad algorithm for rapid retraining machine learning models based on information cached during the training phase. We provide both theoretical and empirical support for the effectiveness of DeltaGrad, and show that it compares favorably to the state of the art.