 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCAMEL: An ECG Language Model for Forecasting Cardiac Events
Feb 17, 2026Electrocardiograms (ECG) are electrical recordings of the heart that are critical for diagnosing cardiovascular conditions. ECG language models (ELMs) have recently emerged as a promising framework for ECG classification accompanied by report generation. However, current models cannot forecast future cardiac events despite the immense clinical value for planning earlier intervention. To address this gap, we propose CAMEL, the first ELM that is capable of inference over longer signal durations which enables its forecasting capability. Our key insight is a specialized ECG encoder which enables cross-understanding of ECG signals with text. We train CAMEL using established LLM training procedures, combining LoRA adaptation with a curriculum learning pipeline. Our curriculum includes ECG classification, metrics calculations, and multi-turn conversations to elicit reasoning. CAMEL demonstrates strong zero-shot performance across 6 tasks and 9 datasets, including ECGForecastBench, a new benchmark that we introduce for forecasting arrhythmias. CAMEL is on par with or surpasses ELMs and fully supervised baselines both in- and out-of-distribution, achieving SOTA results on ECGBench (+7.0% absolute average gain) as well as ECGForecastBench (+12.4% over fully supervised models and +21.1% over zero-shot ELMs).
On Improving Neurosymbolic Learning by Exploiting the Representation Space
Feb 08, 2026We study the problem of learning neural classifiers in a neurosymbolic setting where the hidden gold labels of input instances must satisfy a logical formula. Learning in this setting proceeds by first computing (a subset of) the possible combinations of labels that satisfy the formula and then computing a loss using those combinations and the classifiers' scores. One challenge is that the space of label combinations can grow exponentially, making learning difficult. We propose a technique that prunes this space by exploiting the intuition that instances with similar latent representations are likely to share the same label. While this intuition has been widely used in weakly supervised learning, its application in our setting is challenging due to label dependencies imposed by logical constraints. We formulate the pruning process as an integer linear program that discards inconsistent label combinations while respecting logical structure. Our approach, CLIPPER, is orthogonal to existing training algorithms and can be seamlessly integrated with them. Across 16 benchmarks over complex neurosymbolic tasks, we demonstrate that CLIPPER boosts the performance of state-of-the-art neurosymbolic engines like Scallop, Dolphin, and ISED by up to 48%, 53%, and 8%, leading to state-of-the-art accuracies.
Once Upon an Input: Reasoning via Per-Instance Program Synthesis
Oct 26, 2025Large language models (LLMs) excel at zero-shot inference but continue to struggle with complex, multi-step reasoning. Recent methods that augment LLMs with intermediate reasoning steps such as Chain of Thought (CoT) and Program of Thought (PoT) improve performance but often produce undesirable solutions, especially in algorithmic domains. We introduce Per-Instance Program Synthesis (PIPS), a method that generates and refines programs at the instance-level using structural feedback without relying on task-specific guidance or explicit test cases. To further improve performance, PIPS incorporates a confidence metric that dynamically chooses between direct inference and program synthesis on a per-instance basis. Experiments across three frontier LLMs and 30 benchmarks including all tasks of Big Bench Extra Hard (BBEH), visual question answering tasks, relational reasoning tasks, and mathematical reasoning tasks show that PIPS improves the absolute harmonic mean accuracy by up to 8.6% and 9.4% compared to PoT and CoT respectively, and reduces undesirable program generations by 65.1% on the algorithmic tasks compared to PoT with Gemini-2.0-Flash.
Stable Prediction of Adverse Events in Medical Time-Series Data
Oct 16, 2025
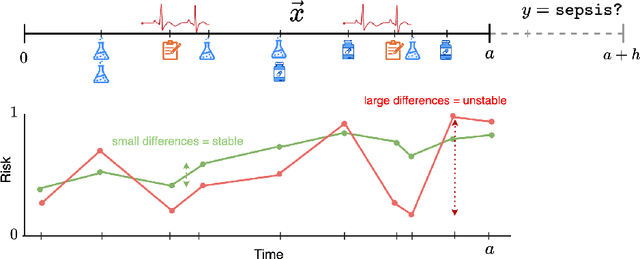
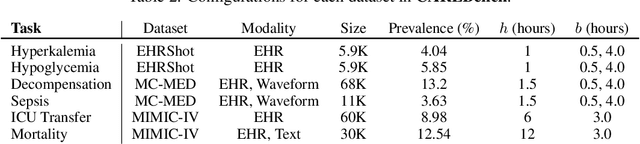
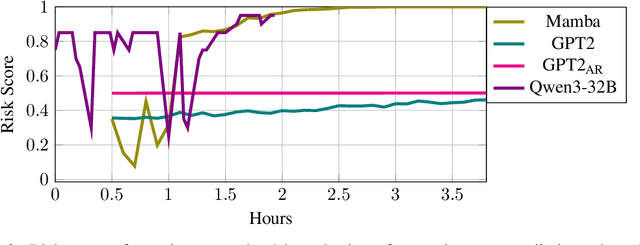
Early event prediction (EEP) systems continuously estimate a patient's imminent risk to support clinical decision-making. For bedside trust, risk trajectories must be accurate and temporally stable, shifting only with new, relevant evidence. However, current benchmarks (a) ignore stability of risk scores and (b) evaluate mainly on tabular inputs, leaving trajectory behavior untested. To address this gap, we introduce CAREBench, an EEP benchmark that evaluates deployability using multi-modal inputs-tabular EHR, ECG waveforms, and clinical text-and assesses temporal stability alongside predictive accuracy. We propose a stability metric that quantifies short-term variability in per-patient risk and penalizes abrupt oscillations based on local-Lipschitz constants. CAREBench spans six prediction tasks such as sepsis onset and compares classical learners, deep sequence models, and zero-shot LLMs. Across tasks, existing methods, especially LLMs, struggle to jointly optimize accuracy and stability, with notably poor recall at high-precision operating points. These results highlight the need for models that produce evidence-aligned, stable trajectories to earn clinician trust in continuous monitoring settings. (Code: https://github.com/SeewonChoi/CAREBench.)
Delta Activations: A Representation for Finetuned Large Language Models
Sep 04, 2025



The success of powerful open source Large Language Models (LLMs) has enabled the community to create a vast collection of post-trained models adapted to specific tasks and domains. However, navigating and understanding these models remains challenging due to inconsistent metadata and unstructured repositories. We introduce Delta Activations, a method to represent finetuned models as vector embeddings by measuring shifts in their internal activations relative to a base model. This representation allows for effective clustering by domain and task, revealing structure in the model landscape. Delta Activations also demonstrate desirable properties: it is robust across finetuning settings and exhibits an additive property when finetuning datasets are mixed. In addition, we show that Delta Activations can embed tasks via few-shot finetuning, and further explore its use for model selection and merging. We hope Delta Activations can facilitate the practice of reusing publicly available models. Code is available at https://github.com/OscarXZQ/delta_activations.
The Road to Generalizable Neuro-Symbolic Learning Should be Paved with Foundation Models
May 30, 2025Neuro-symbolic learning was proposed to address challenges with training neural networks for complex reasoning tasks with the added benefits of interpretability, reliability, and efficiency. Neuro-symbolic learning methods traditionally train neural models in conjunction with symbolic programs, but they face significant challenges that limit them to simplistic problems. On the other hand, purely-neural foundation models now reach state-of-the-art performance through prompting rather than training, but they are often unreliable and lack interpretability. Supplementing foundation models with symbolic programs, which we call neuro-symbolic prompting, provides a way to use these models for complex reasoning tasks. Doing so raises the question: What role does specialized model training as part of neuro-symbolic learning have in the age of foundation models? To explore this question, we highlight three pitfalls of traditional neuro-symbolic learning with respect to the compute, data, and programs leading to generalization problems. This position paper argues that foundation models enable generalizable neuro-symbolic solutions, offering a path towards achieving the original goals of neuro-symbolic learning without the downsides of training from scratch.
Lobster: A GPU-Accelerated Framework for Neurosymbolic Programming
Mar 27, 2025Neurosymbolic programs combine deep learning with symbolic reasoning to achieve better data efficiency, interpretability, and generalizability compared to standalone deep learning approaches. However, existing neurosymbolic learning frameworks implement an uneasy marriage between a highly scalable, GPU-accelerated neural component with a slower symbolic component that runs on CPUs. We propose Lobster, a unified framework for harnessing GPUs in an end-to-end manner for neurosymbolic learning. Lobster maps a general neurosymbolic language based on Datalog to the GPU programming paradigm. This mapping is implemented via compilation to a new intermediate language called APM. The extra abstraction provided by APM allows Lobster to be both flexible, supporting discrete, probabilistic, and differentiable modes of reasoning on GPU hardware with a library of provenance semirings, and performant, implementing new optimization passes. We demonstrate that Lobster programs can solve interesting problems spanning the domains of natural language processing, image processing, program reasoning, bioinformatics, and planning. On a suite of 8 applications, Lobster achieves an average speedup of 5.3x over Scallop, a state-of-the-art neurosymbolic framework, and enables scaling of neurosymbolic solutions to previously infeasible tasks.
Where's the Bug? Attention Probing for Scalable Fault Localization
Feb 20, 2025Ensuring code correctness remains a challenging problem even as large language models (LLMs) become increasingly capable at code-related tasks. While LLM-based program repair systems can propose bug fixes using only a user's bug report, their effectiveness is fundamentally limited by their ability to perform fault localization (FL), a challenging problem for both humans and LLMs. Existing FL approaches rely on executable test cases, require training on costly and often noisy line-level annotations, or demand resource-intensive LLMs. In this paper, we present Bug Attention Probe (BAP), a method which learns state-of-the-art fault localization without any direct localization labels, outperforming traditional FL baselines and prompting of large-scale LLMs. We evaluate our approach across a variety of code settings, including real-world Java bugs from the standard Defects4J dataset as well as seven other datasets which span a diverse set of bug types and languages. Averaged across all eight datasets, BAP improves by 34.6% top-1 accuracy compared to the strongest baseline and 93.4% over zero-shot prompting GPT-4o. BAP is also significantly more efficient than prompting, outperforming large open-weight models at a small fraction of the computational cost.
Relational Programming with Foundation Models
Dec 19, 2024Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
Dolphin: A Programmable Framework for Scalable Neurosymbolic Learning
Oct 04, 2024



Neurosymbolic learning has emerged as a promising paradigm to incorporate symbolic reasoning into deep learning models. However, existing frameworks are limited in scalability with respect to both the training data and the complexity of symbolic programs. We propose Dolphin, a framework to scale neurosymbolic learning at a fundamental level by mapping both forward chaining and backward gradient propagation in symbolic programs to vectorized computations. For this purpose, Dolphin introduces a set of abstractions and primitives built directly on top of a high-performance deep learning framework like PyTorch, effectively enabling symbolic programs to be written as PyTorch modules. It thereby enables neurosymbolic programs to be written in a language like Python that is familiar to developers and compile them to computation graphs that are amenable to end-to-end differentiation on GPUs. We evaluate Dolphin on a suite of 13 benchmarks across 5 neurosymbolic tasks that combine deep learning models for text, image, or video processing with symbolic programs that involve multi-hop reasoning, recursion, and even black-box functions like Python eval(). Dolphin only takes 0.33%-37.17% of the time (and 2.77% on average) to train these models on the largest input per task compared to baselines Scallop, ISED, and IndeCateR+, which time out on most of these inputs. Models written in Dolphin also achieve state-of-the-art accuracies even on the largest benchmarks.