 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo We Need Frontier Models to Verify Mathematical Proofs?
Apr 02, 2026Advances in training, post-training, and inference-time methods have enabled frontier reasoning models to win gold medals in math competitions and settle challenging open problems. Gaining trust in the responses of these models requires that natural language proofs be checked for errors. LLM judges are increasingly being adopted to meet the growing demand for evaluating such proofs. While verification is considered easier than generation, what model capability does reliable verification actually require? We systematically evaluate four open-source and two frontier LLMs on datasets of human-graded natural language proofs of competition-level problems. We consider two key metrics: verifier accuracy and self-consistency (the rate of agreement across repeated judgments on the same proof). We observe that smaller open-source models are only up to ~10% behind frontier models in accuracy but they are up to ~25% more inconsistent. Furthermore, we see that verifier accuracy is sensitive to prompt choice across all models. We then demonstrate that the smaller models, in fact, do possess the mathematical capabilities to verify proofs at the level of frontier models, but they struggle to reliably elicit these capabilities with general judging prompts. Through an LLM-guided prompt search, we synthesize an ensemble of specialized prompts that overcome the specific failure modes of smaller models, boosting their performance by up to 9.1% in accuracy and 15.9% in self-consistency. These gains are realized across models and datasets, allowing models like Qwen3.5-35B to perform on par with frontier models such as Gemini 3.1 Pro for proof verification.
CAMEL: An ECG Language Model for Forecasting Cardiac Events
Feb 17, 2026Electrocardiograms (ECG) are electrical recordings of the heart that are critical for diagnosing cardiovascular conditions. ECG language models (ELMs) have recently emerged as a promising framework for ECG classification accompanied by report generation. However, current models cannot forecast future cardiac events despite the immense clinical value for planning earlier intervention. To address this gap, we propose CAMEL, the first ELM that is capable of inference over longer signal durations which enables its forecasting capability. Our key insight is a specialized ECG encoder which enables cross-understanding of ECG signals with text. We train CAMEL using established LLM training procedures, combining LoRA adaptation with a curriculum learning pipeline. Our curriculum includes ECG classification, metrics calculations, and multi-turn conversations to elicit reasoning. CAMEL demonstrates strong zero-shot performance across 6 tasks and 9 datasets, including ECGForecastBench, a new benchmark that we introduce for forecasting arrhythmias. CAMEL is on par with or surpasses ELMs and fully supervised baselines both in- and out-of-distribution, achieving SOTA results on ECGBench (+7.0% absolute average gain) as well as ECGForecastBench (+12.4% over fully supervised models and +21.1% over zero-shot ELMs).
Stable Prediction of Adverse Events in Medical Time-Series Data
Oct 16, 2025
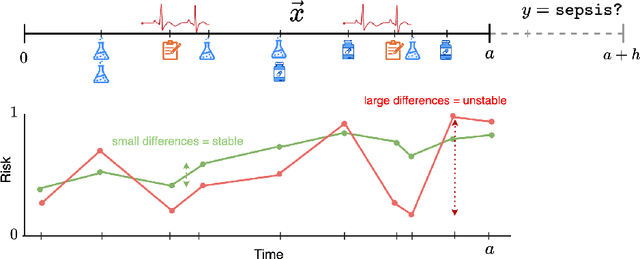
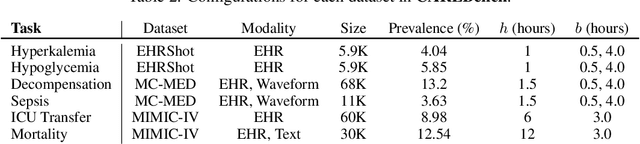
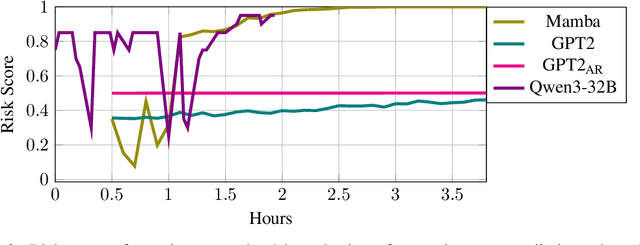
Early event prediction (EEP) systems continuously estimate a patient's imminent risk to support clinical decision-making. For bedside trust, risk trajectories must be accurate and temporally stable, shifting only with new, relevant evidence. However, current benchmarks (a) ignore stability of risk scores and (b) evaluate mainly on tabular inputs, leaving trajectory behavior untested. To address this gap, we introduce CAREBench, an EEP benchmark that evaluates deployability using multi-modal inputs-tabular EHR, ECG waveforms, and clinical text-and assesses temporal stability alongside predictive accuracy. We propose a stability metric that quantifies short-term variability in per-patient risk and penalizes abrupt oscillations based on local-Lipschitz constants. CAREBench spans six prediction tasks such as sepsis onset and compares classical learners, deep sequence models, and zero-shot LLMs. Across tasks, existing methods, especially LLMs, struggle to jointly optimize accuracy and stability, with notably poor recall at high-precision operating points. These results highlight the need for models that produce evidence-aligned, stable trajectories to earn clinician trust in continuous monitoring settings. (Code: https://github.com/SeewonChoi/CAREBench.)
Composing Agents to Minimize Worst-case Risk
Jun 05, 2025From software development to robot control, modern agentic systems decompose complex objectives into a sequence of subtasks and choose a set of specialized AI agents to complete them. We formalize an agentic workflow as a directed acyclic graph, called an agent graph, where edges represent AI agents and paths correspond to feasible compositions of agents. When deploying these systems in the real world, we need to choose compositions of agents that not only maximize the task success, but also minimize risk where the risk captures requirements like safety, fairness, and privacy. This additionally requires carefully analyzing the low-probability (tail) behaviors of compositions of agents. In this work, we consider worst-case risk minimization over the set of feasible agent compositions. We define worst-case risk as the tail quantile -- also known as value-at-risk -- of the loss distribution of the agent composition where the loss quantifies the risk associated with agent behaviors. We introduce an efficient algorithm that traverses the agent graph and finds a near-optimal composition of agents by approximating the value-at-risk via a union bound and dynamic programming. Furthermore, we prove that the approximation is near-optimal asymptotically for a broad class of practical loss functions. To evaluate our framework, we consider a suite of video game-like control benchmarks that require composing several agents trained with reinforcement learning and demonstrate our algorithm's effectiveness in approximating the value-at-risk and identifying the optimal agent composition.
Scenario-based Compositional Verification of Autonomous Systems with Neural Perception
Apr 29, 2025Recent advances in deep learning have enabled the development of autonomous systems that use deep neural networks for perception. Formal verification of these systems is challenging due to the size and complexity of the perception DNNs as well as hard-to-quantify, changing environment conditions. To address these challenges, we propose a probabilistic verification framework for autonomous systems based on the following key concepts: (1) Scenario-based Modeling: We decompose the task (e.g., car navigation) into a composition of scenarios, each representing a different environment condition. (2) Probabilistic Abstractions: For each scenario, we build a compact abstraction of perception based on the DNN's performance on an offline dataset that represents the scenario's environment condition. (3) Symbolic Reasoning and Acceleration: The abstractions enable efficient compositional verification of the autonomous system via symbolic reasoning and a novel acceleration proof rule that bounds the error probability of the system under arbitrary variations of environment conditions. We illustrate our approach on two case studies: an experimental autonomous system that guides airplanes on taxiways using high-dimensional perception DNNs and a simulation model of an F1Tenth autonomous car using LiDAR observations.
CTSketch: Compositional Tensor Sketching for Scalable Neurosymbolic Learning
Mar 31, 2025Many computational tasks benefit from being formulated as the composition of neural networks followed by a discrete symbolic program. The goal of neurosymbolic learning is to train the neural networks using only end-to-end input-output labels of the composite. We introduce CTSketch, a novel, scalable neurosymbolic learning algorithm. CTSketch uses two techniques to improve the scalability of neurosymbolic inference: decompose the symbolic program into sub-programs and summarize each sub-program with a sketched tensor. This strategy allows us to approximate the output distribution of the program with simple tensor operations over the input distributions and summaries. We provide theoretical insight into the maximum error of the approximation. Furthermore, we evaluate CTSketch on many benchmarks from the neurosymbolic literature, including some designed for evaluating scalability. Our results show that CTSketch pushes neurosymbolic learning to new scales that have previously been unattainable by obtaining high accuracy on tasks involving over one thousand inputs.
Relational Programming with Foundation Models
Dec 19, 2024Foundation models have vast potential to enable diverse AI applications. The powerful yet incomplete nature of these models has spurred a wide range of mechanisms to augment them with capabilities such as in-context learning, information retrieval, and code interpreting. We propose Vieira, a declarative framework that unifies these mechanisms in a general solution for programming with foundation models. Vieira follows a probabilistic relational paradigm and treats foundation models as stateless functions with relational inputs and outputs. It supports neuro-symbolic applications by enabling the seamless combination of such models with logic programs, as well as complex, multi-modal applications by streamlining the composition of diverse sub-models. We implement Vieira by extending the Scallop compiler with a foreign interface that supports foundation models as plugins. We implement plugins for 12 foundation models including GPT, CLIP, and SAM. We evaluate Vieira on 9 challenging tasks that span language, vision, and structured and vector databases. Our evaluation shows that programs in Vieira are concise, can incorporate modern foundation models, and have comparable or better accuracy than competitive baselines.
Logicbreaks: A Framework for Understanding Subversion of Rule-based Inference
Jun 21, 2024



We study how to subvert language models from following the rules. We model rule-following as inference in propositional Horn logic, a mathematical system in which rules have the form "if $P$ and $Q$, then $R$" for some propositions $P$, $Q$, and $R$. We prove that although transformers can faithfully abide by such rules, maliciously crafted prompts can nevertheless mislead even theoretically constructed models. Empirically, we find that attacks on our theoretical models mirror popular attacks on large language models. Our work suggests that studying smaller theoretical models can help understand the behavior of large language models in rule-based settings like logical reasoning and jailbreak attacks.
Data-Efficient Learning with Neural Programs
Jun 10, 2024



Many computational tasks can be naturally expressed as a composition of a DNN followed by a program written in a traditional programming language or an API call to an LLM. We call such composites "neural programs" and focus on the problem of learning the DNN parameters when the training data consist of end-to-end input-output labels for the composite. When the program is written in a differentiable logic programming language, techniques from neurosymbolic learning are applicable, but in general, the learning for neural programs requires estimating the gradients of black-box components. We present an algorithm for learning neural programs, called ISED, that only relies on input-output samples of black-box components. For evaluation, we introduce new benchmarks that involve calls to modern LLMs such as GPT-4 and also consider benchmarks from the neurosymolic learning literature. Our evaluation shows that for the latter benchmarks, ISED has comparable performance to state-of-the-art neurosymbolic frameworks. For the former, we use adaptations of prior work on gradient approximations of black-box components as a baseline, and show that ISED achieves comparable accuracy but in a more data- and sample-efficient manner.
Stability Guarantees for Feature Attributions with Multiplicative Smoothing
Jul 12, 2023



Explanation methods for machine learning models tend to not provide any formal guarantees and may not reflect the underlying decision-making process. In this work, we analyze stability as a property for reliable feature attribution methods. We prove that relaxed variants of stability are guaranteed if the model is sufficiently Lipschitz with respect to the masking of features. To achieve such a model, we develop a smoothing method called Multiplicative Smoothing (MuS). We show that MuS overcomes theoretical limitations of standard smoothing techniques and can be integrated with any classifier and feature attribution method. We evaluate MuS on vision and language models with a variety of feature attribution methods, such as LIME and SHAP, and demonstrate that MuS endows feature attributions with non-trivial stability guarantees.