 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMonotonicity as an Architectural Bias for Robust Language Models
Feb 02, 2026Large language models (LLMs) are known to exhibit brittle behavior under adversarial prompts and jailbreak attacks, even after extensive alignment and fine-tuning. This fragility reflects a broader challenge of modern neural language models: small, carefully structured perturbations in high-dimensional input spaces can induce large and unpredictable changes in internal semantic representations and output. We investigate monotonicity as an architectural inductive bias for improving the robustness of Transformer-based language models. Monotonicity constrains semantic transformations so that strengthening information, evidence, or constraints cannot lead to regressions in the corresponding internal representations. Such order-preserving behavior has long been exploited in control and safety-critical systems to simplify reasoning and improve robustness, but has traditionally been viewed as incompatible with the expressivity required by neural language models. We show that this trade-off is not inherent. By enforcing monotonicity selectively in the feed-forward sublayers of sequence-to-sequence Transformers -- while leaving attention mechanisms unconstrained -- we obtain monotone language models that preserve the performance of their pretrained counterparts. This architectural separation allows negation, contradiction, and contextual interactions to be introduced explicitly through attention, while ensuring that subsequent semantic refinement is order-preserving. Empirically, monotonicity substantially improves robustness: adversarial attack success rates drop from approximately 69% to 19%, while standard summarization performance degrades only marginally.
Uncovering Discrimination Clusters: Quantifying and Explaining Systematic Fairness Violations
Dec 29, 2025Fairness in algorithmic decision-making is often framed in terms of individual fairness, which requires that similar individuals receive similar outcomes. A system violates individual fairness if there exists a pair of inputs differing only in protected attributes (such as race or gender) that lead to significantly different outcomes-for example, one favorable and the other unfavorable. While this notion highlights isolated instances of unfairness, it fails to capture broader patterns of systematic or clustered discrimination that may affect entire subgroups. We introduce and motivate the concept of discrimination clustering, a generalization of individual fairness violations. Rather than detecting single counterfactual disparities, we seek to uncover regions of the input space where small perturbations in protected features lead to k-significantly distinct clusters of outcomes. That is, for a given input, we identify a local neighborhood-differing only in protected attributes-whose members' outputs separate into many distinct clusters. These clusters reveal significant arbitrariness in treatment solely based on protected attributes that help expose patterns of algorithmic bias that elude pairwise fairness checks. We present HyFair, a hybrid technique that combines formal symbolic analysis (via SMT and MILP solvers) to certify individual fairness with randomized search to discover discriminatory clusters. This combination enables both formal guarantees-when no counterexamples exist-and the detection of severe violations that are computationally challenging for symbolic methods alone. Given a set of inputs exhibiting high k-unfairness, we introduce a novel explanation method to generate interpretable, decision-tree-style artifacts. Our experiments demonstrate that HyFair outperforms state-of-the-art fairness verification and local explanation methods.
BarrierBench : Evaluating Large Language Models for Safety Verification in Dynamical Systems
Nov 12, 2025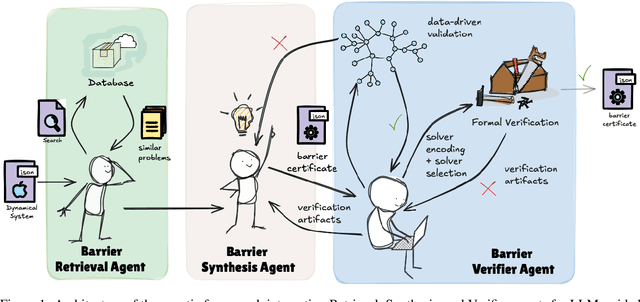



Safety verification of dynamical systems via barrier certificates is essential for ensuring correctness in autonomous applications. Synthesizing these certificates involves discovering mathematical functions with current methods suffering from poor scalability, dependence on carefully designed templates, and exhaustive or incremental function-space searches. They also demand substantial manual expertise--selecting templates, solvers, and hyperparameters, and designing sampling strategies--requiring both theoretical and practical knowledge traditionally shared through linguistic reasoning rather than formalized methods. This motivates a key question: can such expert reasoning be captured and operationalized by language models? We address this by introducing an LLM-based agentic framework for barrier certificate synthesis. The framework uses natural language reasoning to propose, refine, and validate candidate certificates, integrating LLM-driven template discovery with SMT-based verification, and supporting barrier-controller co-synthesis to ensure consistency between safety certificates and controllers. To evaluate this capability, we introduce BarrierBench, a benchmark of 100 dynamical systems spanning linear, nonlinear, discrete-time, and continuous-time settings. Our experiments assess not only the effectiveness of LLM-guided barrier synthesis but also the utility of retrieval-augmented generation and agentic coordination strategies in improving its reliability and performance. Across these tasks, the framework achieves more than 90% success in generating valid certificates. By releasing BarrierBench and the accompanying toolchain, we aim to establish a community testbed for advancing the integration of language-based reasoning with formal verification in dynamical systems. The benchmark is publicly available at https://hycodev.com/dataset/barrierbench
Explaining Hitori Puzzles: Neurosymbolic Proof Staging for Sequential Decisions
Aug 19, 2025We propose a neurosymbolic approach to the explanation of complex sequences of decisions that combines the strengths of decision procedures and Large Language Models (LLMs). We demonstrate this approach by producing explanations for the solutions of Hitori puzzles. The rules of Hitori include local constraints that are effectively explained by short resolution proofs. However, they also include a connectivity constraint that is more suitable for visual explanations. Hence, Hitori provides an excellent testing ground for a flexible combination of SAT solvers and LLMs. We have implemented a tool that assists humans in solving Hitori puzzles, and we present experimental evidence of its effectiveness.
Explaining Puzzle Solutions in Natural Language: An Exploratory Study on 6x6 Sudoku
May 21, 2025The success of Large Language Models (LLMs) in human-AI collaborative decision-making hinges on their ability to provide trustworthy, gradual, and tailored explanations. Solving complex puzzles, such as Sudoku, offers a canonical example of this collaboration, where clear and customized explanations often hold greater importance than the final solution. In this study, we evaluate the performance of five LLMs in solving and explaining \sixsix{} Sudoku puzzles. While one LLM demonstrates limited success in solving puzzles, none can explain the solution process in a manner that reflects strategic reasoning or intuitive problem-solving. These findings underscore significant challenges that must be addressed before LLMs can become effective partners in human-AI collaborative decision-making.
Technical Challenges in Maintaining Tax Prep Software with Large Language Models
Apr 25, 2025



As the US tax law evolves to adapt to ever-changing politico-economic realities, tax preparation software plays a significant role in helping taxpayers navigate these complexities. The dynamic nature of tax regulations poses a significant challenge to accurately and timely maintaining tax software artifacts. The state-of-the-art in maintaining tax prep software is time-consuming and error-prone as it involves manual code analysis combined with an expert interpretation of tax law amendments. We posit that the rigor and formality of tax amendment language, as expressed in IRS publications, makes it amenable to automatic translation to executable specifications (code). Our research efforts focus on identifying, understanding, and tackling technical challenges in leveraging Large Language Models (LLMs), such as ChatGPT and Llama, to faithfully extract code differentials from IRS publications and automatically integrate them with the prior version of the code to automate tax prep software maintenance.
Benchmarking Vision-Language Models on Optical Character Recognition in Dynamic Video Environments
Feb 10, 2025


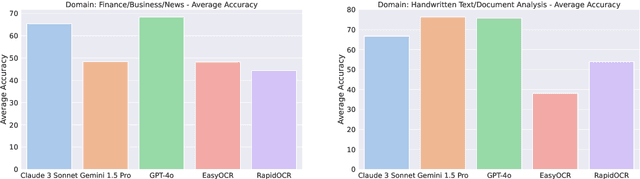
This paper introduces an open-source benchmark for evaluating Vision-Language Models (VLMs) on Optical Character Recognition (OCR) tasks in dynamic video environments. We present a curated dataset containing 1,477 manually annotated frames spanning diverse domains, including code editors, news broadcasts, YouTube videos, and advertisements. Three state of the art VLMs - Claude-3, Gemini-1.5, and GPT-4o are benchmarked against traditional OCR systems such as EasyOCR and RapidOCR. Evaluation metrics include Word Error Rate (WER), Character Error Rate (CER), and Accuracy. Our results highlight the strengths and limitations of VLMs in video-based OCR tasks, demonstrating their potential to outperform conventional OCR models in many scenarios. However, challenges such as hallucinations, content security policies, and sensitivity to occluded or stylized text remain. The dataset and benchmarking framework are publicly available to foster further research.
Fairness Testing through Extreme Value Theory
Jan 20, 2025



Data-driven software is increasingly being used as a critical component of automated decision-support systems. Since this class of software learns its logic from historical data, it can encode or amplify discriminatory practices. Previous research on algorithmic fairness has focused on improving average-case fairness. On the other hand, fairness at the extreme ends of the spectrum, which often signifies lasting and impactful shifts in societal attitudes, has received significantly less emphasis. Leveraging the statistics of extreme value theory (EVT), we propose a novel fairness criterion called extreme counterfactual discrimination (ECD). This criterion estimates the worst-case amounts of disadvantage in outcomes for individuals solely based on their memberships in a protected group. Utilizing tools from search-based software engineering and generative AI, we present a randomized algorithm that samples a statistically significant set of points from the tail of ML outcome distributions even if the input dataset lacks a sufficient number of relevant samples. We conducted several experiments on four ML models (deep neural networks, logistic regression, and random forests) over 10 socially relevant tasks from the literature on algorithmic fairness. First, we evaluate the generative AI methods and find that they generate sufficient samples to infer valid EVT distribution in 95% of cases. Remarkably, we found that the prevalent bias mitigators reduce the average-case discrimination but increase the worst-case discrimination significantly in 5% of cases. We also observed that even the tail-aware mitigation algorithm -- MiniMax-Fairness -- increased the worst-case discrimination in 30% of cases. We propose a novel ECD-based mitigator that improves fairness in the tail in 90% of cases with no degradation of the average-case discrimination.
Transfer Learning for Control Systems via Neural Simulation Relations
Dec 02, 2024



Transfer learning is an umbrella term for machine learning approaches that leverage knowledge gained from solving one problem (the source domain) to improve speed, efficiency, and data requirements in solving a different but related problem (the target domain). The performance of the transferred model in the target domain is typically measured via some notion of loss function in the target domain. This paper focuses on effectively transferring control logic from a source control system to a target control system while providing approximately similar behavioral guarantees in both domains. However, in the absence of a complete characterization of behavioral specifications, this problem cannot be captured in terms of loss functions. To overcome this challenge, we use (approximate) simulation relations to characterize observational equivalence between the behaviors of two systems. Simulation relations ensure that the outputs of both systems, equipped with their corresponding controllers, remain close to each other over time, and their closeness can be quantified {\it a priori}. By parameterizing simulation relations with neural networks, we introduce the notion of \emph{neural simulation relations}, which provides a data-driven approach to transfer any synthesized controller, regardless of the specification of interest, along with its proof of correctness. Compared with prior approaches, our method eliminates the need for a closed-loop mathematical model and specific requirements for both the source and target systems. We also introduce validity conditions that, when satisfied, guarantee the closeness of the outputs of two systems equipped with their corresponding controllers, thus eliminating the need for post-facto verification. We demonstrate the effectiveness of our approach through case studies involving a vehicle and a double inverted pendulum.
Show, Don't Tell: Learning Reward Machines from Demonstrations for Reinforcement Learning-Based Cardiac Pacemaker Synthesis
Nov 04, 2024An (artificial cardiac) pacemaker is an implantable electronic device that sends electrical impulses to the heart to regulate the heartbeat. As the number of pacemaker users continues to rise, so does the demand for features with additional sensors, adaptability, and improved battery performance. Reinforcement learning (RL) has recently been proposed as a performant algorithm for creative design space exploration, adaptation, and statistical verification of cardiac pacemakers. The design of correct reward functions, expressed as a reward machine, is a key programming activity in this process. In 2007, Boston Scientific published a detailed description of their pacemaker specifications. This document has since formed the basis for several formal characterizations of pacemaker specifications using real-time automata and logic. However, because these translations are done manually, they are challenging to verify. Moreover, capturing requirements in automata or logic is notoriously difficult. We posit that it is significantly easier for domain experts, such as electrophysiologists, to observe and identify abnormalities in electrocardiograms that correspond to patient-pacemaker interactions. Therefore, we explore the possibility of learning correctness specifications from such labeled demonstrations in the form of a reward machine and training an RL agent to synthesize a cardiac pacemaker based on the resulting reward machine. We leverage advances in machine learning to extract signals from labeled demonstrations as reward machines using recurrent neural networks and transformer architectures. These reward machines are then used to design a simple pacemaker with RL. Finally, we validate the resulting pacemaker using properties extracted from the Boston Scientific document.