 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Oblivious Opponents in Stochastic Games
Sep 18, 2024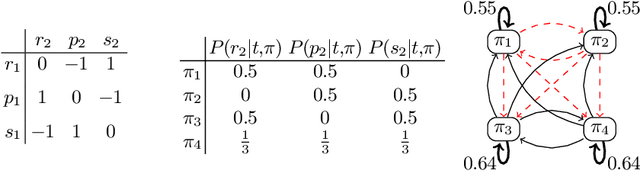


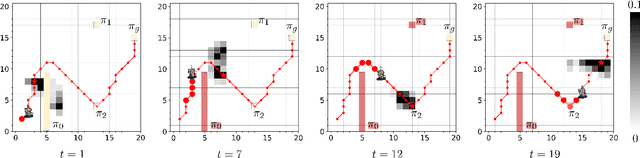
We present an approach for systematically anticipating the actions and policies employed by \emph{oblivious} environments in concurrent stochastic games, while maximizing a reward function. Our main contribution lies in the synthesis of a finite \emph{information state machine} whose alphabet ranges over the actions of the environment. Each state of the automaton is mapped to a belief state about the policy used by the environment. We introduce a notion of consistency that guarantees that the belief states tracked by our automaton stays within a fixed distance of the precise belief state obtained by knowledge of the full history. We provide methods for checking consistency of an automaton and a synthesis approach which upon successful termination yields such a machine. We show how the information state machine yields an MDP that serves as the starting point for computing optimal policies for maximizing a reward function defined over plays. We present an experimental evaluation over benchmark examples including human activity data for tasks such as cataract surgery and furniture assembly, wherein our approach successfully anticipates the policies and actions of the environment in order to maximize the reward.
Large Language Models Enable Automated Formative Feedback in Human-Robot Interaction Tasks
May 25, 2024We claim that LLMs can be paired with formal analysis methods to provide accessible, relevant feedback for HRI tasks. While logic specifications are useful for defining and assessing a task, these representations are not easily interpreted by non-experts. Luckily, LLMs are adept at generating easy-to-understand text that explains difficult concepts. By integrating task assessment outcomes and other contextual information into an LLM prompt, we can effectively synthesize a useful set of recommendations for the learner to improve their performance.
Automated Assessment and Adaptive Multimodal Formative Feedback Improves Psychomotor Skills Training Outcomes in Quadrotor Teleoperation
May 24, 2024The workforce will need to continually upskill in order to meet the evolving demands of industry, especially working with robotic and autonomous systems. Current training methods are not scalable and do not adapt to the skills that learners already possess. In this work, we develop a system that automatically assesses learner skill in a quadrotor teleoperation task using temporal logic task specifications. This assessment is used to generate multimodal feedback based on the principles of effective formative feedback. Participants perceived the feedback positively. Those receiving formative feedback viewed the feedback as more actionable compared to receiving summary statistics. Participants in the multimodal feedback condition were more likely to achieve a safe landing and increased their safe landings more over the experiment compared to other feedback conditions. Finally, we identify themes to improve adaptive feedback and discuss and how training for complex psychomotor tasks can be integrated with learning theories.
Worst-Case Convergence Time of ML Algorithms via Extreme Value Theory
Apr 10, 2024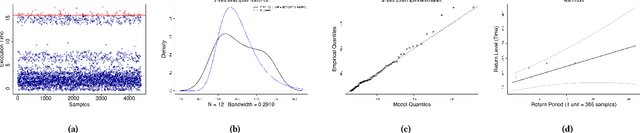



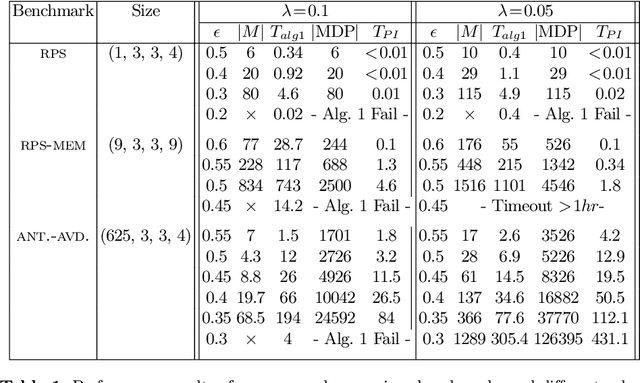
This paper leverages the statistics of extreme values to predict the worst-case convergence times of machine learning algorithms. Timing is a critical non-functional property of ML systems, and providing the worst-case converge times is essential to guarantee the availability of ML and its services. However, timing properties such as worst-case convergence times (WCCT) are difficult to verify since (1) they are not encoded in the syntax or semantics of underlying programming languages of AI, (2) their evaluations depend on both algorithmic implementations and underlying systems, and (3) their measurements involve uncertainty and noise. Therefore, prevalent formal methods and statistical models fail to provide rich information on the amounts and likelihood of WCCT. Our key observation is that the timing information we seek represents the extreme tail of execution times. Therefore, extreme value theory (EVT), a statistical discipline that focuses on understanding and predicting the distribution of extreme values in the tail of outcomes, provides an ideal framework to model and analyze WCCT in the training and inference phases of ML paradigm. Building upon the mathematical tools from EVT, we propose a practical framework to predict the worst-case timing properties of ML. Over a set of linear ML training algorithms, we show that EVT achieves a better accuracy for predicting WCCTs than relevant statistical methods such as the Bayesian factor. On the set of larger machine learning training algorithms and deep neural network inference, we show the feasibility and usefulness of EVT models to accurately predict WCCTs, their expected return periods, and their likelihood.
Certifiably-correct Control Policies for Safe Learning and Adaptation in Assistive Robotics
Mar 12, 2023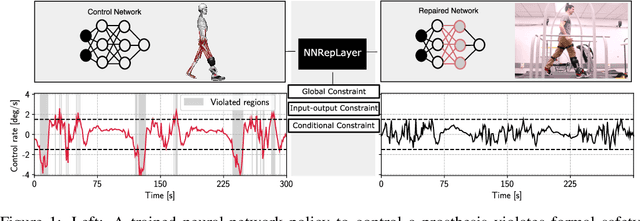



Guaranteeing safety in human-centric applications is critical in robot learning as the learned policies may demonstrate unsafe behaviors in formerly unseen scenarios. We present a framework to locally repair an erroneous policy network to satisfy a set of formal safety constraints using Mixed Integer Quadratic Programming (MIQP). Our MIQP formulation explicitly imposes the safety constraints to the learned policy while minimizing the original loss function. The policy network is then verified to be locally safe. We demonstrate the application of our framework to derive safe policies for a robotic lower-leg prosthesis.
Safe Robot Learning in Assistive Devices through Neural Network Repair
Mar 08, 2023



Assistive robotic devices are a particularly promising field of application for neural networks (NN) due to the need for personalization and hard-to-model human-machine interaction dynamics. However, NN based estimators and controllers may produce potentially unsafe outputs over previously unseen data points. In this paper, we introduce an algorithm for updating NN control policies to satisfy a given set of formal safety constraints, while also optimizing the original loss function. Given a set of mixed-integer linear constraints, we define the NN repair problem as a Mixed Integer Quadratic Program (MIQP). In extensive experiments, we demonstrate the efficacy of our repair method in generating safe policies for a lower-leg prosthesis.
Mathematical Models of Human Drivers Using Artificial Risk Fields
May 24, 2022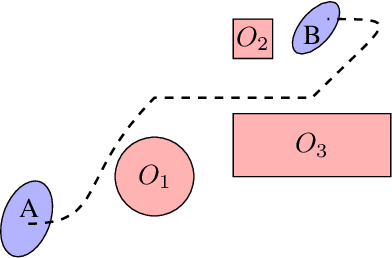
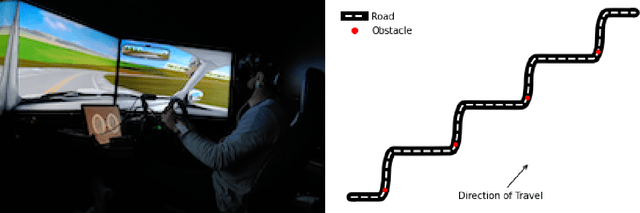
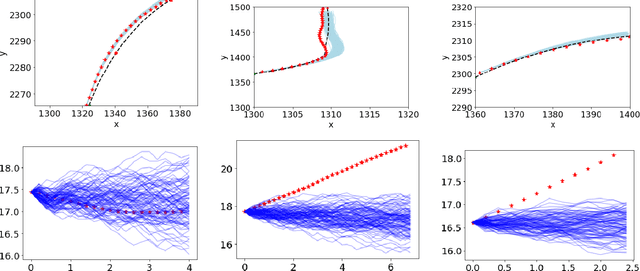
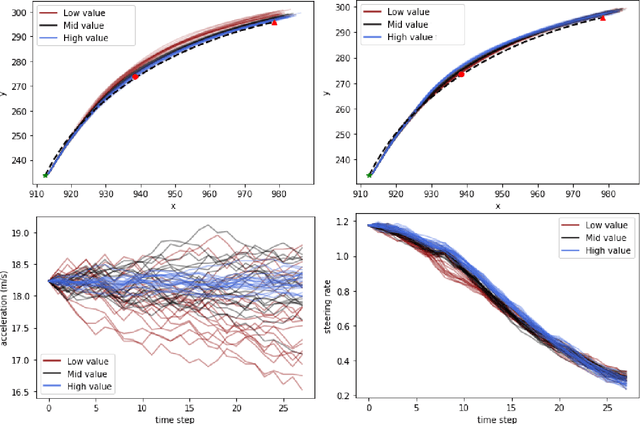
In this paper, we use the concept of artificial risk fields to predict how human operators control a vehicle in response to upcoming road situations. A risk field assigns a non-negative risk measure to the state of the system in order to model how close that state is to violating a safety property, such as hitting an obstacle or exiting the road. Using risk fields, we construct a stochastic model of the operator that maps from states to likely actions. We demonstrate our approach on a driving task wherein human subjects are asked to drive a car inside a realistic driving simulator while avoiding obstacles placed on the road. We show that the most likely risk field given the driving data is obtained by solving a convex optimization problem. Next, we apply the inferred risk fields to generate distinct driving behaviors while comparing predicted trajectories against ground truth measurements. We observe that the risk fields are excellent at predicting future trajectory distributions with high prediction accuracy for up to twenty seconds prediction horizons. At the same time, we observe some challenges such as the inability to account for how drivers choose to accelerate/decelerate based on the road conditions.
Local Repair of Neural Networks Using Optimization
Sep 28, 2021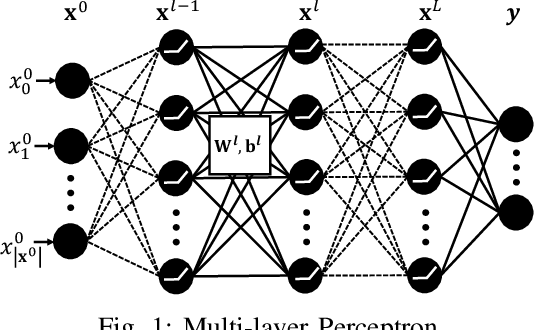
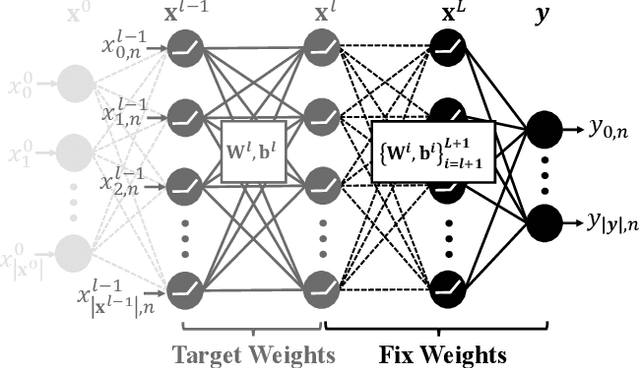
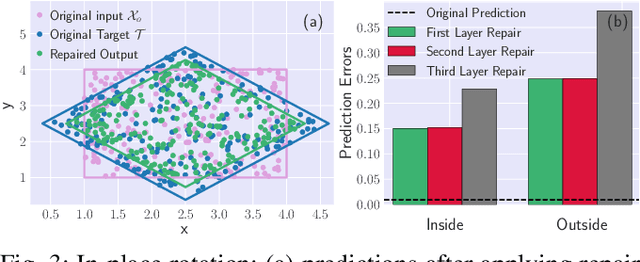
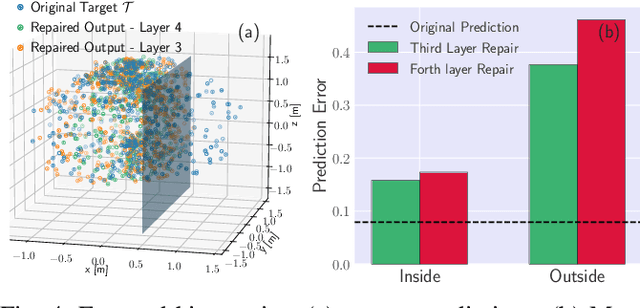
In this paper, we propose a framework to repair a pre-trained feed-forward neural network (NN) to satisfy a set of properties. We formulate the properties as a set of predicates that impose constraints on the output of NN over the target input domain. We define the NN repair problem as a Mixed Integer Quadratic Program (MIQP) to adjust the weights of a single layer subject to the given predicates while minimizing the original loss function over the original training domain. We demonstrate the application of our framework in bounding an affine transformation, correcting an erroneous NN in classification, and bounding the inputs of a NN controller.
Static analysis of ReLU neural networks with tropical polyhedra
Aug 23, 2021


This paper studies the problem of range analysis for feedforward neural networks, which is a basic primitive for applications such as robustness of neural networks, compliance to specifications and reachability analysis of neural-network feedback systems. Our approach focuses on ReLU (rectified linear unit) feedforward neural nets that present specific difficulties: approaches that exploit derivatives do not apply in general, the number of patterns of neuron activations can be quite large even for small networks, and convex approximations are generally too coarse. In this paper, we employ set-based methods and abstract interpretation that have been very successful in coping with similar difficulties in classical program verification. We present an approach that abstracts ReLU feedforward neural networks using tropical polyhedra. We show that tropical polyhedra can efficiently abstract ReLU activation function, while being able to control the loss of precision due to linear computations. We show how the connection between ReLU networks and tropical rational functions can provide approaches for range analysis of ReLU neural networks.
Predictive Runtime Monitoring for Mobile Robots using Logic-Based Bayesian Intent Inference
Aug 03, 2021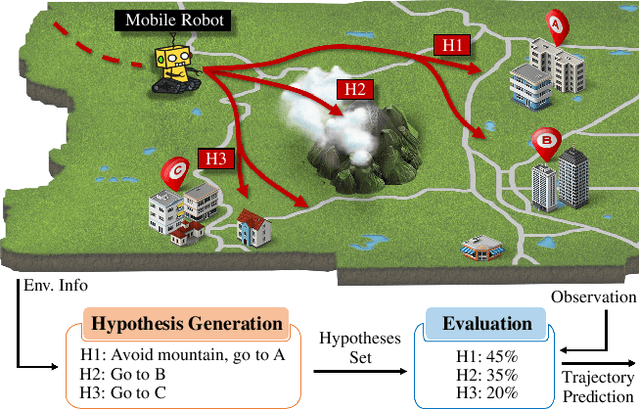
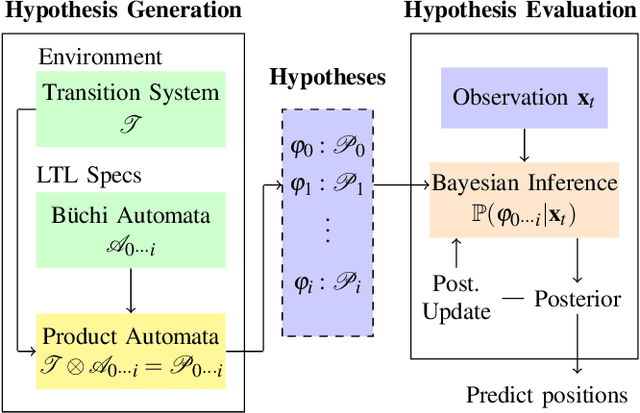
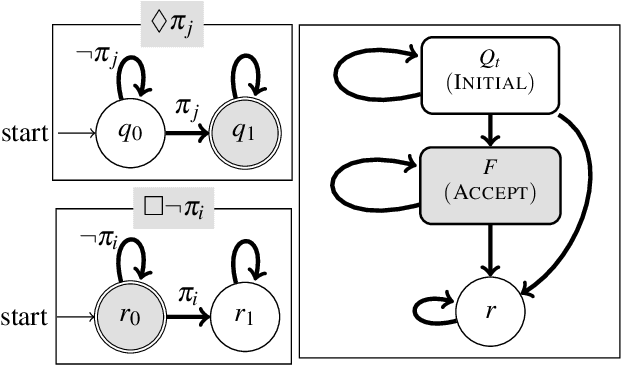
We propose a predictive runtime monitoring framework that forecasts the distribution of future positions of mobile robots in order to detect and avoid impending property violations such as collisions with obstacles or other agents. Our approach uses a restricted class of temporal logic formulas to represent the likely intentions of the agents along with a combination of temporal logic-based optimal cost path planning and Bayesian inference to compute the probability of these intents given the current trajectory of the robot. First, we construct a large but finite hypothesis space of possible intents represented as temporal logic formulas whose atomic propositions are derived from a detailed map of the robot's workspace. Next, our approach uses real-time observations of the robot's position to update a distribution over temporal logic formulae that represent its likely intent. This is performed by using a combination of optimal cost path planning and a Boltzmann noisy rationality model. In this manner, we construct a Bayesian approach to evaluating the posterior probability of various hypotheses given the observed states and actions of the robot. Finally, we predict the future position of the robot by drawing posterior predictive samples using a Monte-Carlo method. We evaluate our framework using two different trajectory datasets that contain multiple scenarios implementing various tasks. The results show that our method can predict future positions precisely and efficiently, so that the computation time for generating a prediction is a tiny fraction of the overall time horizon.