 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOCAII: Parameter Optimization with Conscious Allocation using Iterative Intelligence
May 16, 2025In this paper we propose for the first time the hyperparameter optimization (HPO) algorithm POCAII. POCAII differs from the Hyperband and Successive Halving literature by explicitly separating the search and evaluation phases and utilizing principled approaches to exploration and exploitation principles during both phases. Such distinction results in a highly flexible scheme for managing a hyperparameter optimization budget by focusing on search (i.e., generating competing configurations) towards the start of the HPO process while increasing the evaluation effort as the HPO comes to an end. POCAII was compared to state of the art approaches SMAC, BOHB and DEHB. Our algorithm shows superior performance in low-budget hyperparameter optimization regimes. Since many practitioners do not have exhaustive resources to assign to HPO, it has wide applications to real-world problems. Moreover, the empirical evidence showed how POCAII demonstrates higher robustness and lower variance in the results. This is again very important when considering realistic scenarios with extremely expensive models to train.
Parameter Optimization with Conscious Allocation (POCA)
Dec 29, 2023



The performance of modern machine learning algorithms depends upon the selection of a set of hyperparameters. Common examples of hyperparameters are learning rate and the number of layers in a dense neural network. Auto-ML is a branch of optimization that has produced important contributions in this area. Within Auto-ML, hyperband-based approaches, which eliminate poorly-performing configurations after evaluating them at low budgets, are among the most effective. However, the performance of these algorithms strongly depends on how effectively they allocate the computational budget to various hyperparameter configurations. We present the new Parameter Optimization with Conscious Allocation (POCA), a hyperband-based algorithm that adaptively allocates the inputted budget to the hyperparameter configurations it generates following a Bayesian sampling scheme. We compare POCA to its nearest competitor at optimizing the hyperparameters of an artificial toy function and a deep neural network and find that POCA finds strong configurations faster in both settings.
Certifiably-correct Control Policies for Safe Learning and Adaptation in Assistive Robotics
Mar 12, 2023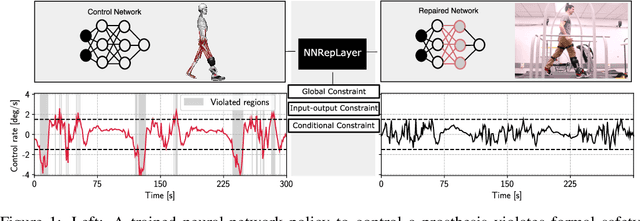



Guaranteeing safety in human-centric applications is critical in robot learning as the learned policies may demonstrate unsafe behaviors in formerly unseen scenarios. We present a framework to locally repair an erroneous policy network to satisfy a set of formal safety constraints using Mixed Integer Quadratic Programming (MIQP). Our MIQP formulation explicitly imposes the safety constraints to the learned policy while minimizing the original loss function. The policy network is then verified to be locally safe. We demonstrate the application of our framework to derive safe policies for a robotic lower-leg prosthesis.
Safe Robot Learning in Assistive Devices through Neural Network Repair
Mar 08, 2023



Assistive robotic devices are a particularly promising field of application for neural networks (NN) due to the need for personalization and hard-to-model human-machine interaction dynamics. However, NN based estimators and controllers may produce potentially unsafe outputs over previously unseen data points. In this paper, we introduce an algorithm for updating NN control policies to satisfy a given set of formal safety constraints, while also optimizing the original loss function. Given a set of mixed-integer linear constraints, we define the NN repair problem as a Mixed Integer Quadratic Program (MIQP). In extensive experiments, we demonstrate the efficacy of our repair method in generating safe policies for a lower-leg prosthesis.
Part-X: A Family of Stochastic Algorithms for Search-Based Test Generation with Probabilistic Guarantees
Oct 20, 2021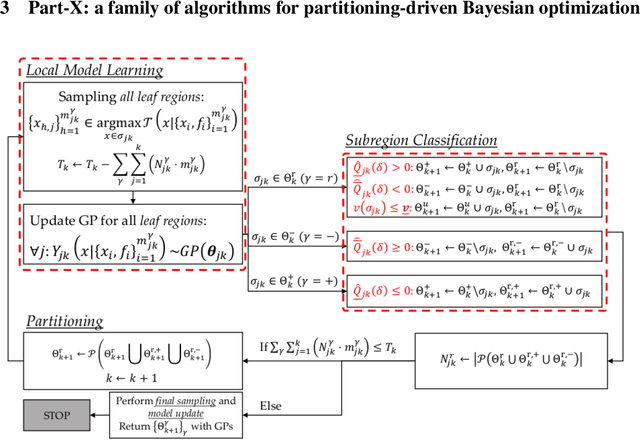
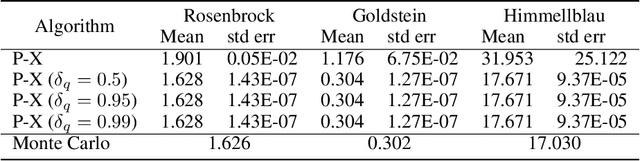
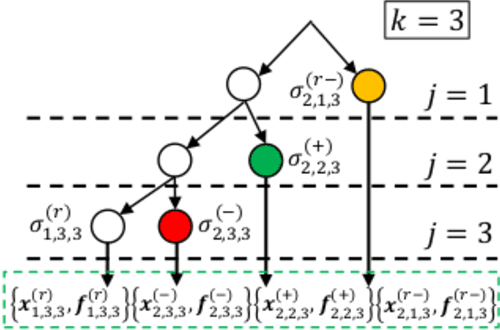
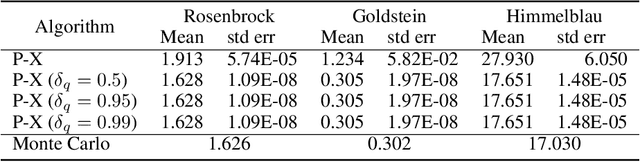
Requirements driven search-based testing (also known as falsification) has proven to be a practical and effective method for discovering erroneous behaviors in Cyber-Physical Systems. Despite the constant improvements on the performance and applicability of falsification methods, they all share a common characteristic. Namely, they are best-effort methods which do not provide any guarantees on the absence of erroneous behaviors (falsifiers) when the testing budget is exhausted. The absence of finite time guarantees is a major limitation which prevents falsification methods from being utilized in certification procedures. In this paper, we address the finite-time guarantees problem by developing a new stochastic algorithm. Our proposed algorithm not only estimates (bounds) the probability that falsifying behaviors exist, but also it identifies the regions where these falsifying behaviors may occur. We demonstrate the applicability of our approach on standard benchmark functions from the optimization literature and on the F16 benchmark problem.
Impact of News on the Commodity Market: Dataset and Results
Sep 09, 2020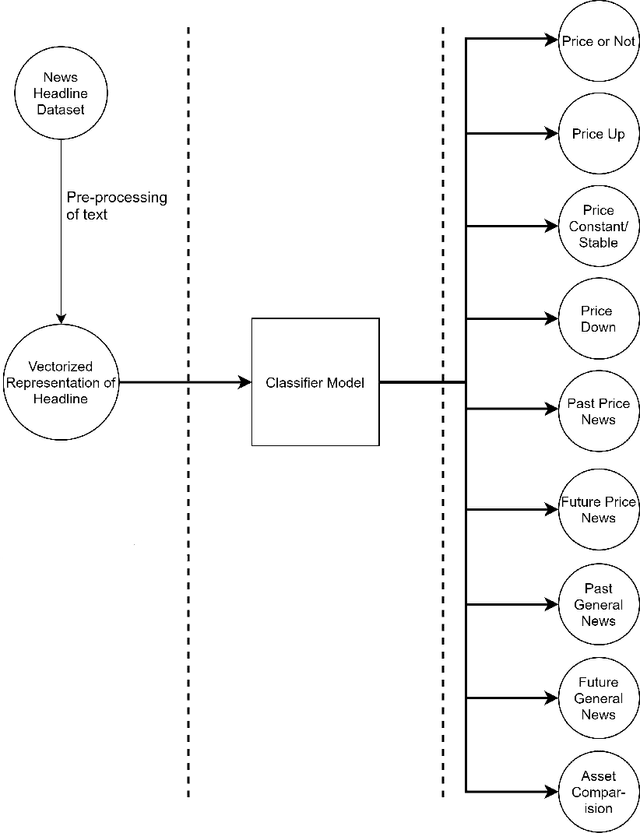
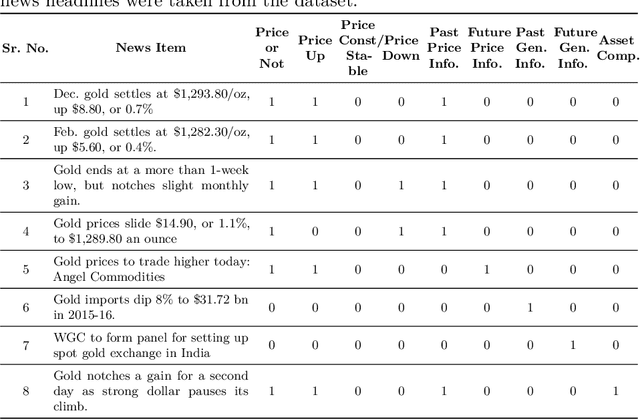
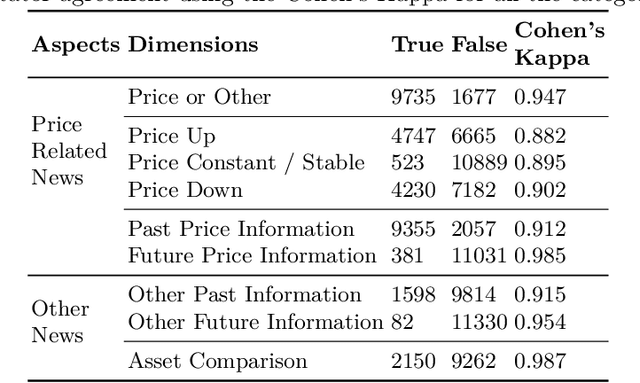
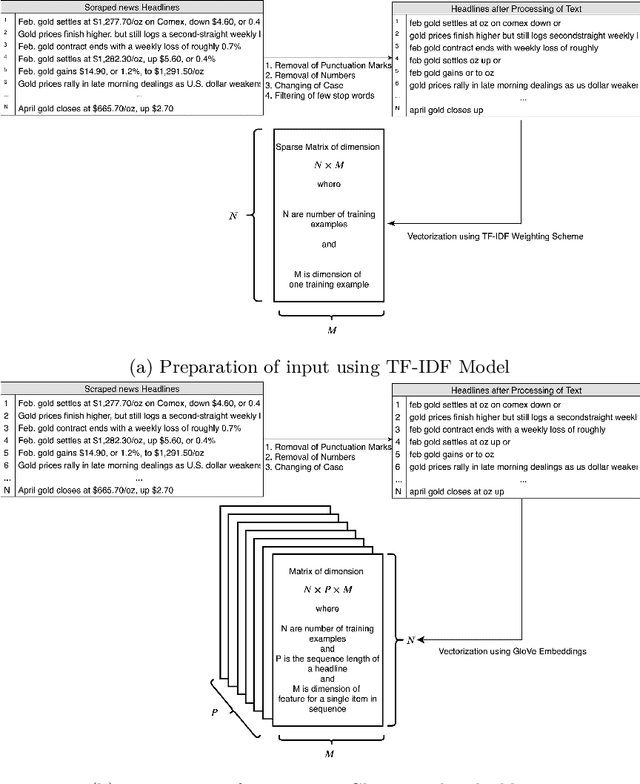
Over the last few years, machine learning based methods have been applied to extract information from news flow in the financial domain. However, this information has mostly been in the form of the financial sentiments contained in the news headlines, primarily for the stock prices. In our current work, we propose that various other dimensions of information can be extracted from news headlines, which will be of interest to investors, policy-makers and other practitioners. We propose a framework that extracts information such as past movements and expected directionality in prices, asset comparison and other general information that the news is referring to. We apply this framework to the commodity "Gold" and train the machine learning models using a dataset of 11,412 human-annotated news headlines (released with this study), collected from the period 2000-2019. We experiment to validate the causal effect of news flow on gold prices and observe that the information produced from our framework significantly impacts the future gold price.
A Gradient-based Bilevel Optimization Approach for Tuning Hyperparameters in Machine Learning
Jul 21, 2020
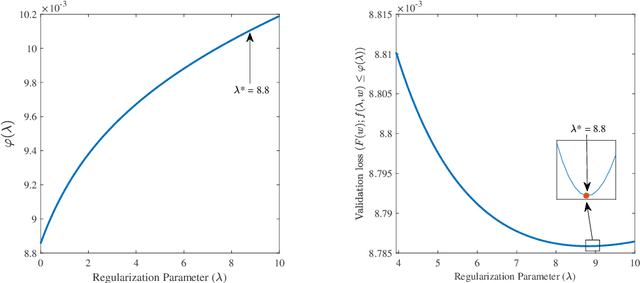
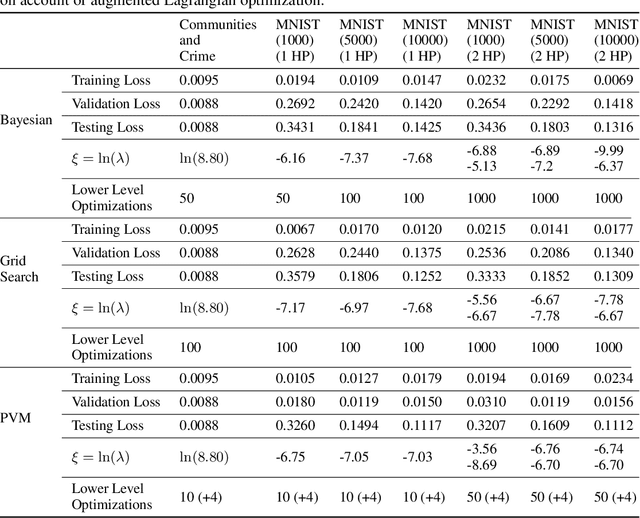
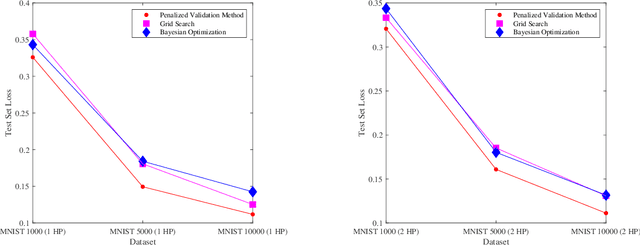
Hyperparameter tuning is an active area of research in machine learning, where the aim is to identify the optimal hyperparameters that provide the best performance on the validation set. Hyperparameter tuning is often achieved using naive techniques, such as random search and grid search. However, most of these methods seldom lead to an optimal set of hyperparameters and often get very expensive. In this paper, we propose a bilevel solution method for solving the hyperparameter optimization problem that does not suffer from the drawbacks of the earlier studies. The proposed method is general and can be easily applied to any class of machine learning algorithms. The idea is based on the approximation of the lower level optimal value function mapping, which is an important mapping in bilevel optimization and helps in reducing the bilevel problem to a single level constrained optimization task. The single-level constrained optimization problem is solved using the augmented Lagrangian method. We discuss the theory behind the proposed algorithm and perform extensive computational study on two datasets that confirm the efficiency of the proposed method. We perform a comparative study against grid search, random search and Bayesian optimization techniques that shows that the proposed algorithm is multiple times faster on problems with one or two hyperparameters. The computational gain is expected to be significantly higher as the number of hyperparameters increase. Corresponding to a given hyperparameter most of the techniques in the literature often assume a unique optimal parameter set that minimizes loss on the training set. Such an assumption is often violated by deep learning architectures and the proposed method does not require any such assumption.