 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwinTrack: Bridging Vision and Contact Physics for Real-Time Tracking of Unknown Dynamic Objects
May 28, 2025
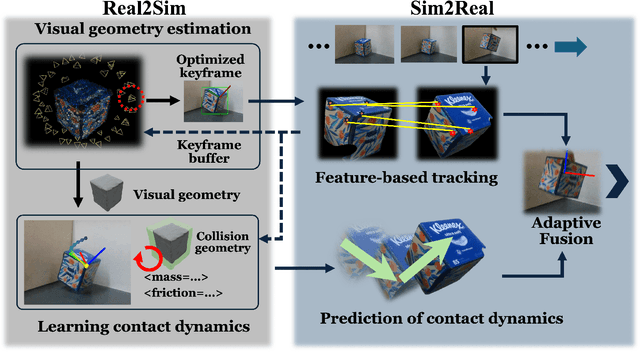
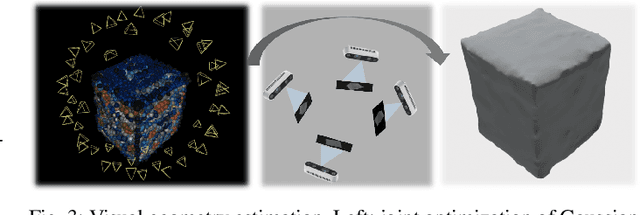
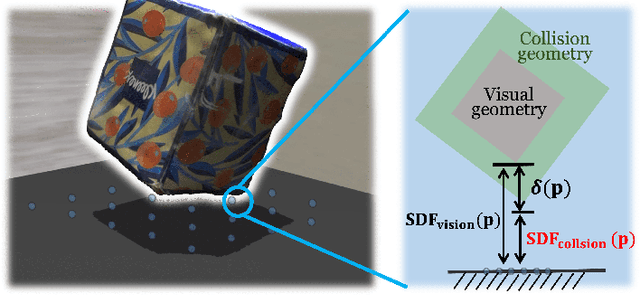
Real-time tracking of previously unseen, highly dynamic objects in contact-rich environments -- such as during dexterous in-hand manipulation -- remains a significant challenge. Purely vision-based tracking often suffers from heavy occlusions due to the frequent contact interactions and motion blur caused by abrupt motion during contact impacts. We propose TwinTrack, a physics-aware visual tracking framework that enables robust and real-time 6-DoF pose tracking of unknown dynamic objects in a contact-rich scene by leveraging the contact physics of the observed scene. At the core of TwinTrack is an integration of Real2Sim and Sim2Real. In Real2Sim, we combine the complementary strengths of vision and contact physics to estimate object's collision geometry and physical properties: object's geometry is first reconstructed from vision, then updated along with other physical parameters from contact dynamics for physical accuracy. In Sim2Real, robust pose estimation of the object is achieved by adaptive fusion between visual tracking and prediction of the learned contact physics. TwinTrack is built on a GPU-accelerated, deeply customized physics engine to ensure real-time performance. We evaluate our method on two contact-rich scenarios: object falling with rich contact impacts against the environment, and contact-rich in-hand manipulation. Experimental results demonstrate that, compared to baseline methods, TwinTrack achieves significantly more robust, accurate, and real-time 6-DoF tracking in these challenging scenarios, with tracking speed exceeding 20 Hz. Project page: https://irislab.tech/TwinTrack-webpage/
SAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025

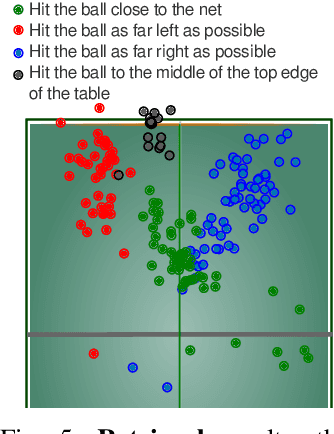

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
Repairing Neural Networks for Safety in Robotic Systems using Predictive Models
Nov 07, 2024



This paper introduces a new method for safety-aware robot learning, focusing on repairing policies using predictive models. Our method combines behavioral cloning with neural network repair in a two-step supervised learning framework. It first learns a policy from expert demonstrations and then applies repair subject to predictive models to enforce safety constraints. The predictive models can encompass various aspects relevant to robot learning applications, such as proprioceptive states and collision likelihood. Our experimental results demonstrate that the learned policy successfully adheres to a predefined set of safety constraints on two applications: mobile robot navigation, and real-world lower-leg prostheses. Additionally, we have shown that our method effectively reduces repeated interaction with the robot, leading to substantial time savings during the learning process.
SiSCo: Signal Synthesis for Effective Human-Robot Communication Via Large Language Models
Sep 20, 2024

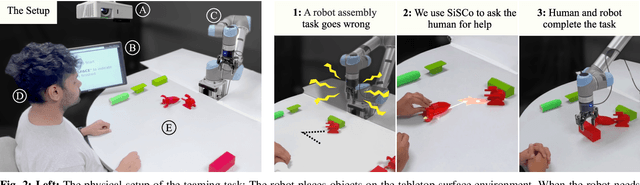

Effective human-robot collaboration hinges on robust communication channels, with visual signaling playing a pivotal role due to its intuitive appeal. Yet, the creation of visually intuitive cues often demands extensive resources and specialized knowledge. The emergence of Large Language Models (LLMs) offers promising avenues for enhancing human-robot interactions and revolutionizing the way we generate context-aware visual cues. To this end, we introduce SiSCo--a novel framework that combines the computational power of LLMs with mixed-reality technologies to streamline the creation of visual cues for human-robot collaboration. Our results show that SiSCo improves the efficiency of communication in human-robot teaming tasks, reducing task completion time by approximately 73% and increasing task success rates by 18% compared to baseline natural language signals. Additionally, SiSCo reduces cognitive load for participants by 46%, as measured by the NASA-TLX subscale, and receives above-average user ratings for on-the-fly signals generated for unseen objects. To encourage further development and broader community engagement, we provide full access to SiSCo's implementation and related materials on our GitHub repository.
A Comparison of Imitation Learning Algorithms for Bimanual Manipulation
Aug 13, 2024



Amidst the wide popularity of imitation learning algorithms in robotics, their properties regarding hyperparameter sensitivity, ease of training, data efficiency, and performance have not been well-studied in high-precision industry-inspired environments. In this work, we demonstrate the limitations and benefits of prominent imitation learning approaches and analyze their capabilities regarding these properties. We evaluate each algorithm on a complex bimanual manipulation task involving an over-constrained dynamics system in a setting involving multiple contacts between the manipulated object and the environment. While we find that imitation learning is well suited to solve such complex tasks, not all algorithms are equal in terms of handling environmental and hyperparameter perturbations, training requirements, performance, and ease of use. We investigate the empirical influence of these key characteristics by employing a carefully designed experimental procedure and learning environment. Paper website: https://bimanual-imitation.github.io/
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Ubiquitous Robot Control Through Multimodal Motion Capture Using Smartwatch and Smartphone Data
Jun 03, 2024



We present an open-source library for seamless robot control through motion capture using smartphones and smartwatches. Our library features three modes: Watch Only Mode, enabling control with a single smartwatch; Upper Arm Mode, offering heightened accuracy by incorporating the smartphone attached to the upper arm; and Pocket Mode, determining body orientation via the smartphone placed in any pocket. These modes are applied in two real-robot tasks, showcasing placement accuracy within 2 cm compared to a gold-standard motion capture system. WearMoCap stands as a suitable alternative to conventional motion capture systems, particularly in environments where ubiquity is essential. The library is available at: www.github.com/wearable-motion-capture.
Enabling Stateful Behaviors for Diffusion-based Policy Learning
Apr 18, 2024



While imitation learning provides a simple and effective framework for policy learning, acquiring consistent actions during robot execution remains a challenging task. Existing approaches primarily focus on either modifying the action representation at data curation stage or altering the model itself, both of which do not fully address the scalability of consistent action generation. To overcome this limitation, we introduce the Diff-Control policy, which utilizes a diffusion-based model to learn the action representation from a state-space modeling viewpoint. We demonstrate that we can reduce diffusion-based policies' uncertainty by making it stateful through a Bayesian formulation facilitated by ControlNet, leading to improved robustness and success rates. Our experimental results demonstrate the significance of incorporating action statefulness in policy learning, where Diff-Control shows improved performance across various tasks. Specifically, Diff-Control achieves an average success rate of 72% and 84% on stateful and dynamic tasks, respectively. Project page: https://github.com/ir-lab/Diff-Control
iRoCo: Intuitive Robot Control From Anywhere Using a Smartwatch
Mar 11, 2024



This paper introduces iRoCo (intuitive Robot Control) - a framework for ubiquitous human-robot collaboration using a single smartwatch and smartphone. By integrating probabilistic differentiable filters, iRoCo optimizes a combination of precise robot control and unrestricted user movement from ubiquitous devices. We demonstrate and evaluate the effectiveness of iRoCo in practical teleoperation and drone piloting applications. Comparative analysis shows no significant difference between task performance with iRoCo and gold-standard control systems in teleoperation tasks. Additionally, iRoCo users complete drone piloting tasks 32\% faster than with a traditional remote control and report less frustration in a subjective load index questionnaire. Our findings strongly suggest that iRoCo is a promising new approach for intuitive robot control through smartwatches and smartphones from anywhere, at any time. The code is available at www.github.com/wearable-motion-capture
"Task Success" is not Enough: Investigating the Use of Video-Language Models as Behavior Critics for Catching Undesirable Agent Behaviors
Feb 06, 2024Large-scale generative models are shown to be useful for sampling meaningful candidate solutions, yet they often overlook task constraints and user preferences. Their full power is better harnessed when the models are coupled with external verifiers and the final solutions are derived iteratively or progressively according to the verification feedback. In the context of embodied AI, verification often solely involves assessing whether goal conditions specified in the instructions have been met. Nonetheless, for these agents to be seamlessly integrated into daily life, it is crucial to account for a broader range of constraints and preferences beyond bare task success (e.g., a robot should grasp bread with care to avoid significant deformations). However, given the unbounded scope of robot tasks, it is infeasible to construct scripted verifiers akin to those used for explicit-knowledge tasks like the game of Go and theorem proving. This begs the question: when no sound verifier is available, can we use large vision and language models (VLMs), which are approximately omniscient, as scalable Behavior Critics to catch undesirable robot behaviors in videos? To answer this, we first construct a benchmark that contains diverse cases of goal-reaching yet undesirable robot policies. Then, we comprehensively evaluate VLM critics to gain a deeper understanding of their strengths and failure modes. Based on the evaluation, we provide guidelines on how to effectively utilize VLM critiques and showcase a practical way to integrate the feedback into an iterative process of policy refinement. The dataset and codebase are released at: https://guansuns.github.io/pages/vlm-critic.