 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCode World Models for General Game Playing
Oct 06, 2025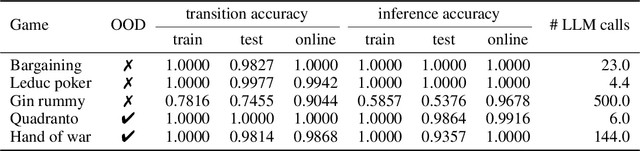

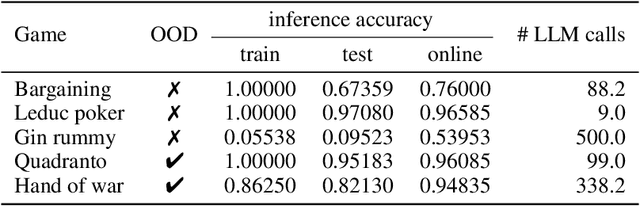
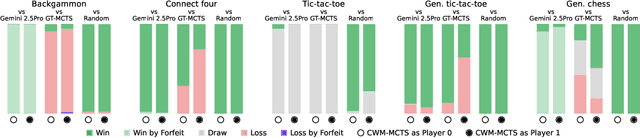
Large Language Models (LLMs) reasoning abilities are increasingly being applied to classical board and card games, but the dominant approach -- involving prompting for direct move generation -- has significant drawbacks. It relies on the model's implicit fragile pattern-matching capabilities, leading to frequent illegal moves and strategically shallow play. Here we introduce an alternative approach: We use the LLM to translate natural language rules and game trajectories into a formal, executable world model represented as Python code. This generated model -- comprising functions for state transition, legal move enumeration, and termination checks -- serves as a verifiable simulation engine for high-performance planning algorithms like Monte Carlo tree search (MCTS). In addition, we prompt the LLM to generate heuristic value functions (to make MCTS more efficient), and inference functions (to estimate hidden states in imperfect information games). Our method offers three distinct advantages compared to directly using the LLM as a policy: (1) Verifiability: The generated CWM serves as a formal specification of the game's rules, allowing planners to algorithmically enumerate valid actions and avoid illegal moves, contingent on the correctness of the synthesized model; (2) Strategic Depth: We combine LLM semantic understanding with the deep search power of classical planners; and (3) Generalization: We direct the LLM to focus on the meta-task of data-to-code translation, enabling it to adapt to new games more easily. We evaluate our agent on 10 different games, of which 4 are novel and created for this paper. 5 of the games are fully observed (perfect information), and 5 are partially observed (imperfect information). We find that our method outperforms or matches Gemini 2.5 Pro in 9 out of the 10 considered games.
SAS-Prompt: Large Language Models as Numerical Optimizers for Robot Self-Improvement
Apr 29, 2025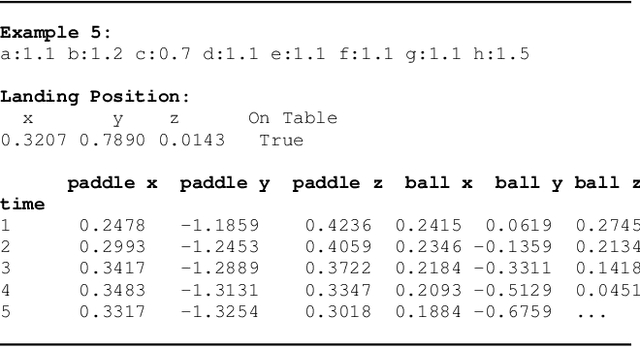

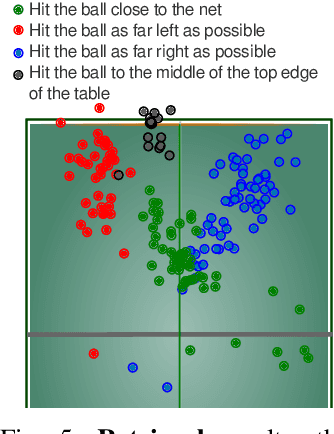

We demonstrate the ability of large language models (LLMs) to perform iterative self-improvement of robot policies. An important insight of this paper is that LLMs have a built-in ability to perform (stochastic) numerical optimization and that this property can be leveraged for explainable robot policy search. Based on this insight, we introduce the SAS Prompt (Summarize, Analyze, Synthesize) -- a single prompt that enables iterative learning and adaptation of robot behavior by combining the LLM's ability to retrieve, reason and optimize over previous robot traces in order to synthesize new, unseen behavior. Our approach can be regarded as an early example of a new family of explainable policy search methods that are entirely implemented within an LLM. We evaluate our approach both in simulation and on a real-robot table tennis task. Project website: sites.google.com/asu.edu/sas-llm/
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Achieving Human Level Competitive Robot Table Tennis
Aug 07, 2024



Achieving human-level speed and performance on real world tasks is a north star for the robotics research community. This work takes a step towards that goal and presents the first learned robot agent that reaches amateur human-level performance in competitive table tennis. Table tennis is a physically demanding sport which requires human players to undergo years of training to achieve an advanced level of proficiency. In this paper, we contribute (1) a hierarchical and modular policy architecture consisting of (i) low level controllers with their detailed skill descriptors which model the agent's capabilities and help to bridge the sim-to-real gap and (ii) a high level controller that chooses the low level skills, (2) techniques for enabling zero-shot sim-to-real including an iterative approach to defining the task distribution that is grounded in the real-world and defines an automatic curriculum, and (3) real time adaptation to unseen opponents. Policy performance was assessed through 29 robot vs. human matches of which the robot won 45% (13/29). All humans were unseen players and their skill level varied from beginner to tournament level. Whilst the robot lost all matches vs. the most advanced players it won 100% matches vs. beginners and 55% matches vs. intermediate players, demonstrating solidly amateur human-level performance. Videos of the matches can be viewed at https://sites.google.com/view/competitive-robot-table-tennis
Prosody for Intuitive Robotic Interface Design: It's Not What You Said, It's How You Said It
Mar 13, 2024

In this paper, we investigate the use of 'prosody' (the musical elements of speech) as a communicative signal for intuitive human-robot interaction interfaces. Our approach, rooted in Research through Design (RtD), examines the application of prosody in directing a quadruped robot navigation. We involved ten team members in an experiment to command a robot through an obstacle course using natural interaction. A human operator, serving as the robot's sensory and processing proxy, translated human communication into a basic set of navigation commands, effectively simulating an intuitive interface. During our analysis of interaction videos, when lexical and visual cues proved insufficient for accurate command interpretation, we turned to non-verbal auditory cues. Qualitative evidence suggests that participants intuitively relied on prosody to control robot navigation. We highlight specific distinct prosodic constructs that emerged from this preliminary exploration and discuss their pragmatic functions. This work contributes a discussion on the broader potential of prosody as a multifunctional communicative signal for designing future intuitive robotic interfaces, enabling lifelong learning and personalization in human-robot interaction.
Robotic Table Tennis: A Case Study into a High Speed Learning System
Sep 06, 2023



We present a deep-dive into a real-world robotic learning system that, in previous work, was shown to be capable of hundreds of table tennis rallies with a human and has the ability to precisely return the ball to desired targets. This system puts together a highly optimized perception subsystem, a high-speed low-latency robot controller, a simulation paradigm that can prevent damage in the real world and also train policies for zero-shot transfer, and automated real world environment resets that enable autonomous training and evaluation on physical robots. We complement a complete system description, including numerous design decisions that are typically not widely disseminated, with a collection of studies that clarify the importance of mitigating various sources of latency, accounting for training and deployment distribution shifts, robustness of the perception system, sensitivity to policy hyper-parameters, and choice of action space. A video demonstrating the components of the system and details of experimental results can be found at https://youtu.be/uFcnWjB42I0.
Barkour: Benchmarking Animal-level Agility with Quadruped Robots
May 24, 2023
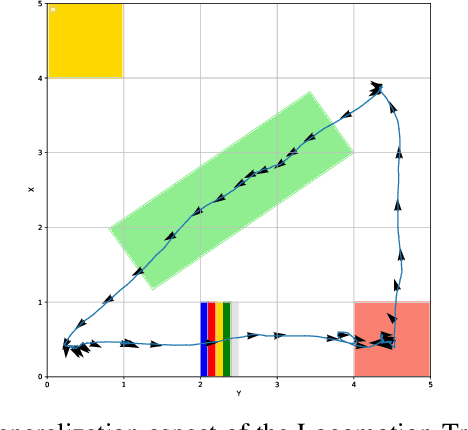
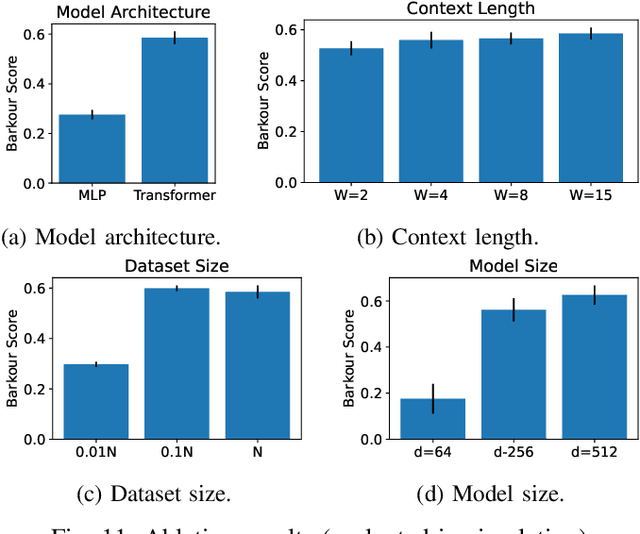

Animals have evolved various agile locomotion strategies, such as sprinting, leaping, and jumping. There is a growing interest in developing legged robots that move like their biological counterparts and show various agile skills to navigate complex environments quickly. Despite the interest, the field lacks systematic benchmarks to measure the performance of control policies and hardware in agility. We introduce the Barkour benchmark, an obstacle course to quantify agility for legged robots. Inspired by dog agility competitions, it consists of diverse obstacles and a time based scoring mechanism. This encourages researchers to develop controllers that not only move fast, but do so in a controllable and versatile way. To set strong baselines, we present two methods for tackling the benchmark. In the first approach, we train specialist locomotion skills using on-policy reinforcement learning methods and combine them with a high-level navigation controller. In the second approach, we distill the specialist skills into a Transformer-based generalist locomotion policy, named Locomotion-Transformer, that can handle various terrains and adjust the robot's gait based on the perceived environment and robot states. Using a custom-built quadruped robot, we demonstrate that our method can complete the course at half the speed of a dog. We hope that our work represents a step towards creating controllers that enable robots to reach animal-level agility.
Adversarial Motion Priors Make Good Substitutes for Complex Reward Functions
Mar 28, 2022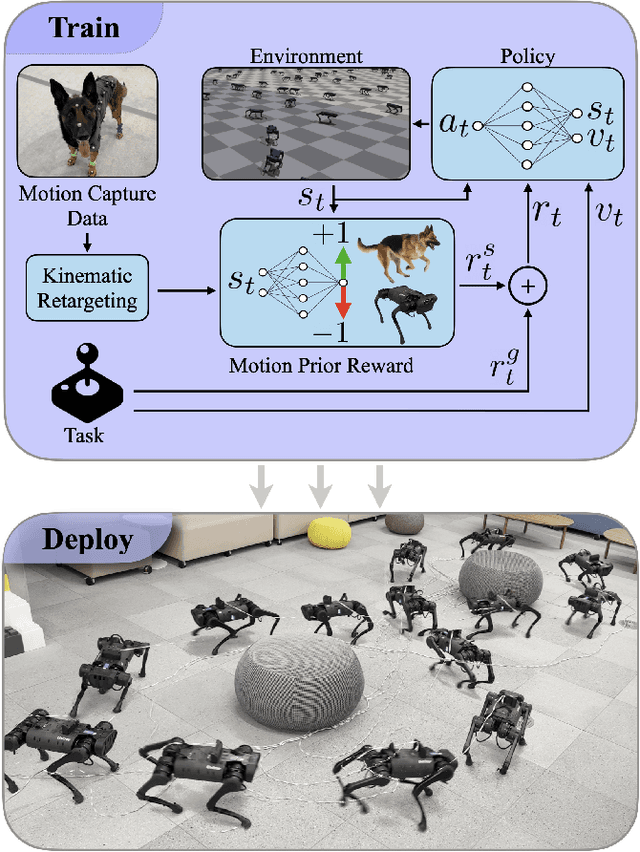
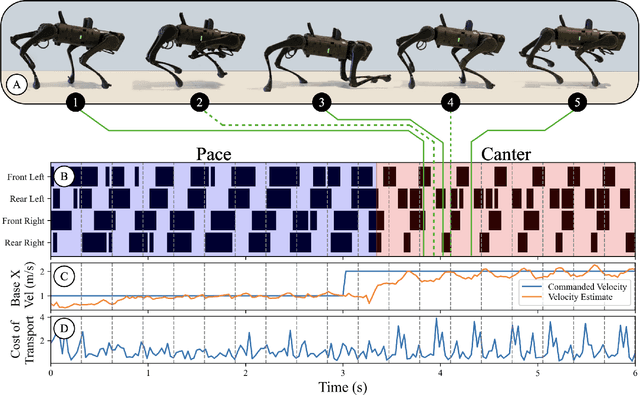


Training a high-dimensional simulated agent with an under-specified reward function often leads the agent to learn physically infeasible strategies that are ineffective when deployed in the real world. To mitigate these unnatural behaviors, reinforcement learning practitioners often utilize complex reward functions that encourage physically plausible behaviors. However, a tedious labor-intensive tuning process is often required to create hand-designed rewards which might not easily generalize across platforms and tasks. We propose substituting complex reward functions with "style rewards" learned from a dataset of motion capture demonstrations. A learned style reward can be combined with an arbitrary task reward to train policies that perform tasks using naturalistic strategies. These natural strategies can also facilitate transfer to the real world. We build upon Adversarial Motion Priors -- an approach from the computer graphics domain that encodes a style reward from a dataset of reference motions -- to demonstrate that an adversarial approach to training policies can produce behaviors that transfer to a real quadrupedal robot without requiring complex reward functions. We also demonstrate that an effective style reward can be learned from a few seconds of motion capture data gathered from a German Shepherd and leads to energy-efficient locomotion strategies with natural gait transitions.
Disentangled Planning and Control in Vision Based Robotics via Reward Machines
Dec 28, 2020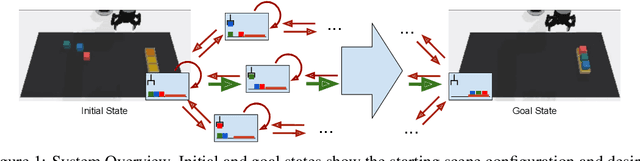
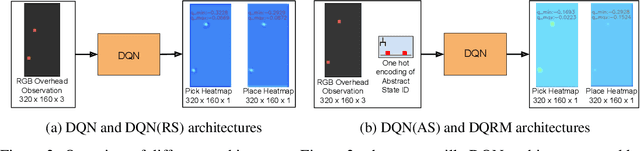
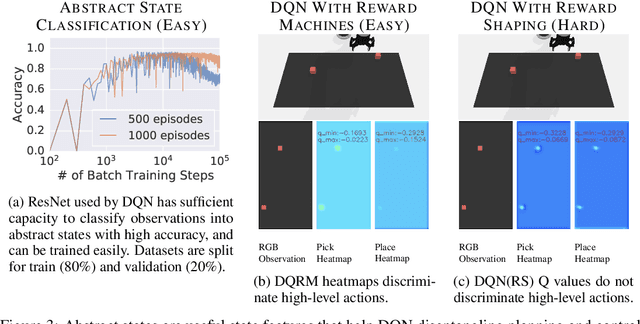
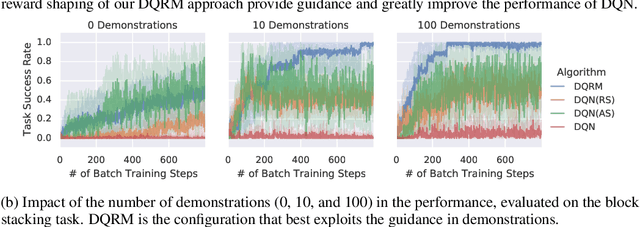
In this work we augment a Deep Q-Learning agent with a Reward Machine (DQRM) to increase speed of learning vision-based policies for robot tasks, and overcome some of the limitations of DQN that prevent it from converging to good-quality policies. A reward machine (RM) is a finite state machine that decomposes a task into a discrete planning graph and equips the agent with a reward function to guide it toward task completion. The reward machine can be used for both reward shaping, and informing the policy what abstract state it is currently at. An abstract state is a high level simplification of the current state, defined in terms of task relevant features. These two supervisory signals of reward shaping and knowledge of current abstract state coming from the reward machine complement each other and can both be used to improve policy performance as demonstrated on several vision based robotic pick and place tasks. Particularly for vision based robotics applications, it is often easier to build a reward machine than to try and get a policy to learn the task without this structure.
From Pixels to Legs: Hierarchical Learning of Quadruped Locomotion
Nov 23, 2020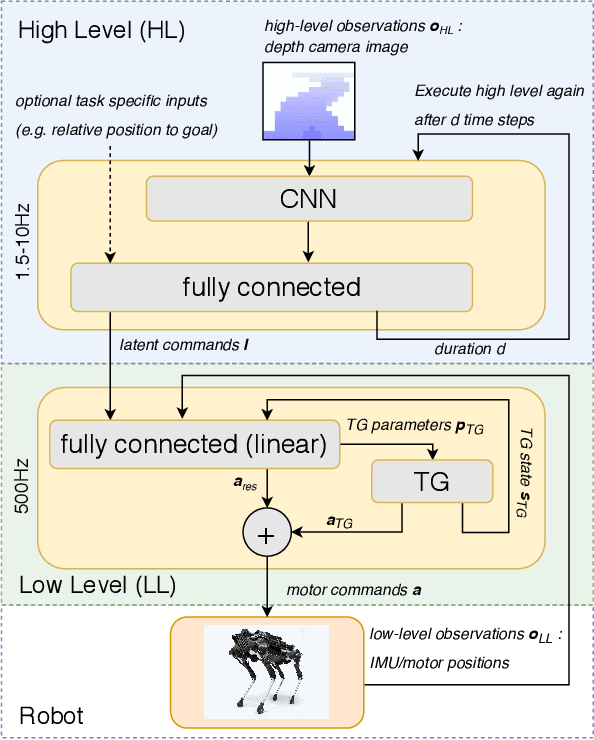

Legged robots navigating crowded scenes and complex terrains in the real world are required to execute dynamic leg movements while processing visual input for obstacle avoidance and path planning. We show that a quadruped robot can acquire both of these skills by means of hierarchical reinforcement learning (HRL). By virtue of their hierarchical structure, our policies learn to implicitly break down this joint problem by concurrently learning High Level (HL) and Low Level (LL) neural network policies. These two levels are connected by a low dimensional hidden layer, which we call latent command. HL receives a first-person camera view, whereas LL receives the latent command from HL and the robot's on-board sensors to control its actuators. We train policies to walk in two different environments: a curved cliff and a maze. We show that hierarchical policies can concurrently learn to locomote and navigate in these environments, and show they are more efficient than non-hierarchical neural network policies. This architecture also allows for knowledge reuse across tasks. LL networks trained on one task can be transferred to a new task in a new environment. Finally HL, which processes camera images, can be evaluated at much lower and varying frequencies compared to LL, thus reducing computation times and bandwidth requirements.