 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
DemoStart: Demonstration-led auto-curriculum applied to sim-to-real with multi-fingered robots
Sep 10, 2024

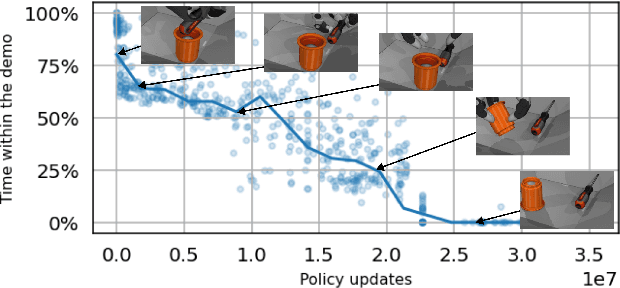
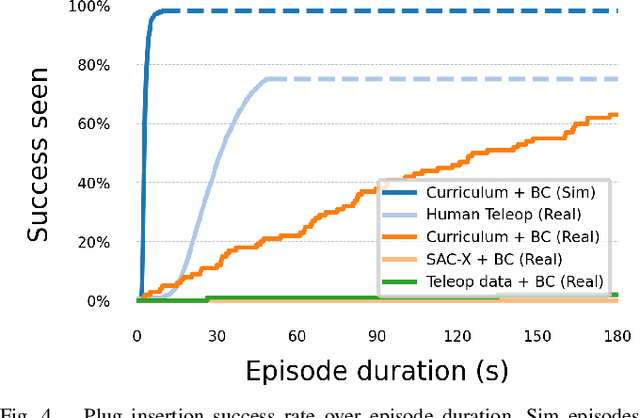
We present DemoStart, a novel auto-curriculum reinforcement learning method capable of learning complex manipulation behaviors on an arm equipped with a three-fingered robotic hand, from only a sparse reward and a handful of demonstrations in simulation. Learning from simulation drastically reduces the development cycle of behavior generation, and domain randomization techniques are leveraged to achieve successful zero-shot sim-to-real transfer. Transferred policies are learned directly from raw pixels from multiple cameras and robot proprioception. Our approach outperforms policies learned from demonstrations on the real robot and requires 100 times fewer demonstrations, collected in simulation. More details and videos in https://sites.google.com/view/demostart.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
simPLE: a visuotactile method learned in simulation to precisely pick, localize, regrasp, and place objects
Jul 24, 2023
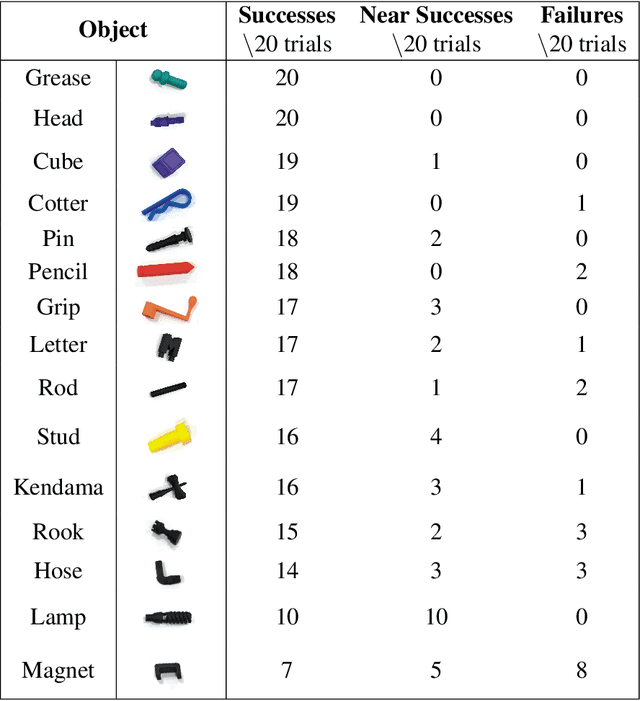
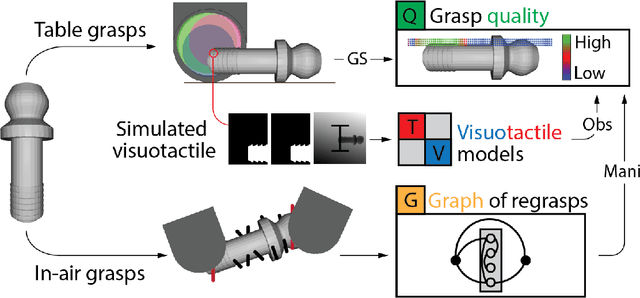
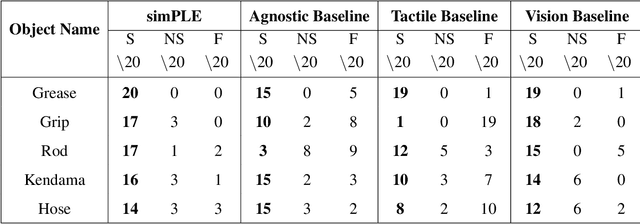
Existing robotic systems have a clear tension between generality and precision. Deployed solutions for robotic manipulation tend to fall into the paradigm of one robot solving a single task, lacking precise generalization, i.e., the ability to solve many tasks without compromising on precision. This paper explores solutions for precise and general pick-and-place. In precise pick-and-place, i.e. kitting, the robot transforms an unstructured arrangement of objects into an organized arrangement, which can facilitate further manipulation. We propose simPLE (simulation to Pick Localize and PLacE) as a solution to precise pick-and-place. simPLE learns to pick, regrasp and place objects precisely, given only the object CAD model and no prior experience. We develop three main components: task-aware grasping, visuotactile perception, and regrasp planning. Task-aware grasping computes affordances of grasps that are stable, observable, and favorable to placing. The visuotactile perception model relies on matching real observations against a set of simulated ones through supervised learning. Finally, we compute the desired robot motion by solving a shortest path problem on a graph of hand-to-hand regrasps. On a dual-arm robot equipped with visuotactile sensing, we demonstrate pick-and-place of 15 diverse objects with simPLE. The objects span a wide range of shapes and simPLE achieves successful placements into structured arrangements with 1mm clearance over 90% of the time for 6 objects, and over 80% of the time for 11 objects. Videos are available at http://mcube.mit.edu/research/simPLE.html .
RoboCat: A Self-Improving Foundation Agent for Robotic Manipulation
Jun 20, 2023



The ability to leverage heterogeneous robotic experience from different robots and tasks to quickly master novel skills and embodiments has the potential to transform robot learning. Inspired by recent advances in foundation models for vision and language, we propose a foundation agent for robotic manipulation. This agent, named RoboCat, is a visual goal-conditioned decision transformer capable of consuming multi-embodiment action-labelled visual experience. This data spans a large repertoire of motor control skills from simulated and real robotic arms with varying sets of observations and actions. With RoboCat, we demonstrate the ability to generalise to new tasks and robots, both zero-shot as well as through adaptation using only 100--1000 examples for the target task. We also show how a trained model itself can be used to generate data for subsequent training iterations, thus providing a basic building block for an autonomous improvement loop. We investigate the agent's capabilities, with large-scale evaluations both in simulation and on three different real robot embodiments. We find that as we grow and diversify its training data, RoboCat not only shows signs of cross-task transfer, but also becomes more efficient at adapting to new tasks.
FingerSLAM: Closed-loop Unknown Object Localization and Reconstruction from Visuo-tactile Feedback
Mar 14, 2023



In this paper, we address the problem of using visuo-tactile feedback for 6-DoF localization and 3D reconstruction of unknown in-hand objects. We propose FingerSLAM, a closed-loop factor graph-based pose estimator that combines local tactile sensing at finger-tip and global vision sensing from a wrist-mount camera. FingerSLAM is constructed with two constituent pose estimators: a multi-pass refined tactile-based pose estimator that captures movements from detailed local textures, and a single-pass vision-based pose estimator that predicts from a global view of the object. We also design a loop closure mechanism that actively matches current vision and tactile images to previously stored key-frames to reduce accumulated error. FingerSLAM incorporates the two sensing modalities of tactile and vision, as well as the loop closure mechanism with a factor graph-based optimization framework. Such a framework produces an optimized pose estimation solution that is more accurate than the standalone estimators. The estimated poses are then used to reconstruct the shape of the unknown object incrementally by stitching the local point clouds recovered from tactile images. We train our system on real-world data collected with 20 objects. We demonstrate reliable visuo-tactile pose estimation and shape reconstruction through quantitative and qualitative real-world evaluations on 6 objects that are unseen during training.
Tac2Pose: Tactile Object Pose Estimation from the First Touch
Apr 25, 2022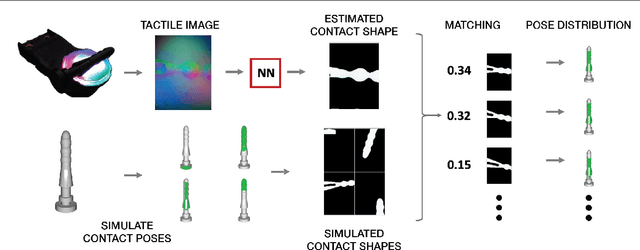
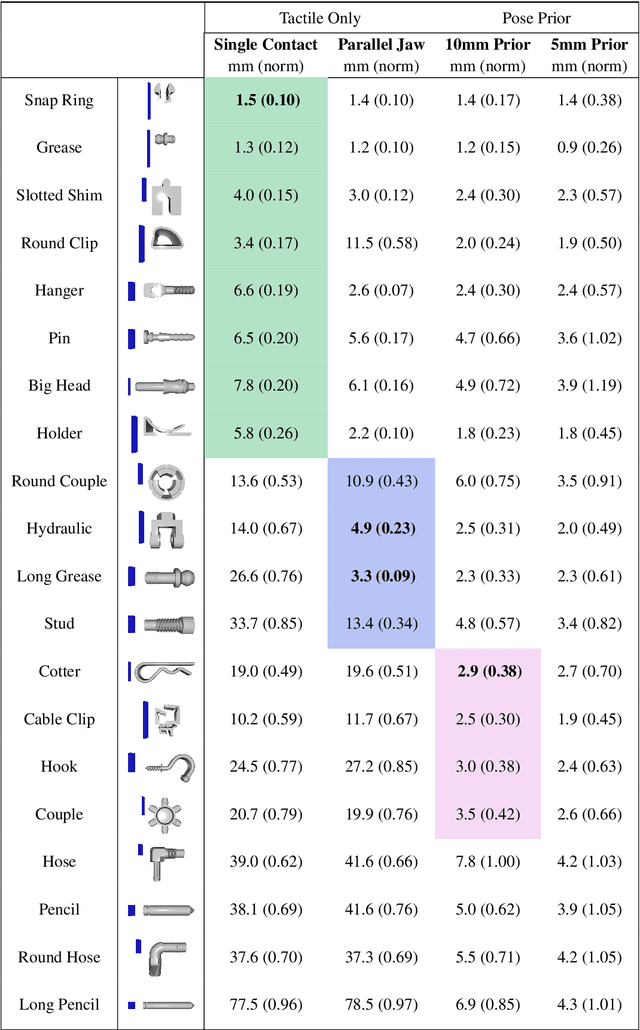
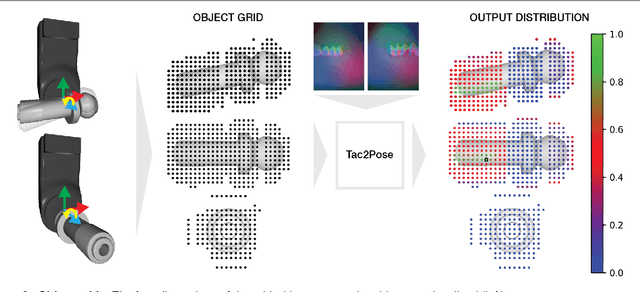
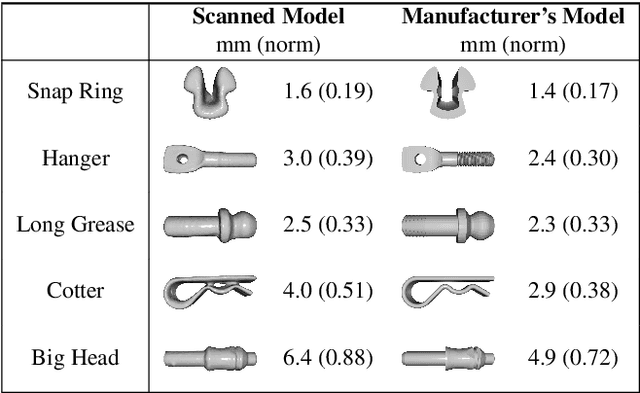
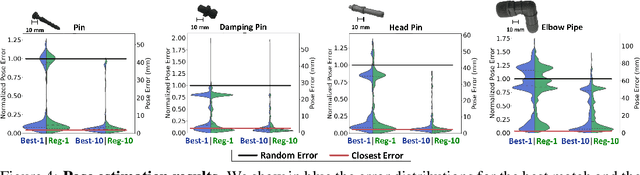
In this paper, we present Tac2Pose, an object-specific approach to tactile pose estimation from the first touch for known objects. Given the object geometry, we learn a tailored perception model in simulation that estimates a probability distribution over possible object poses given a tactile observation. To do so, we simulate the contact shapes that a dense set of object poses would produce on the sensor. Then, given a new contact shape obtained from the sensor, we match it against the pre-computed set using an object-specific embedding learned using contrastive learning. We obtain contact shapes from the sensor with an object-agnostic calibration step that maps RGB tactile observations to binary contact shapes. This mapping, which can be reused across object and sensor instances, is the only step trained with real sensor data. This results in a perception model that localizes objects from the first real tactile observation. Importantly, it produces pose distributions and can incorporate additional pose constraints coming from other perception systems, contacts, or priors. We provide quantitative results for 20 objects. Tac2Pose provides high accuracy pose estimations from distinctive tactile observations while regressing meaningful pose distributions to account for those contact shapes that could result from different object poses. We also test Tac2Pose on object models reconstructed from a 3D scanner, to evaluate the robustness to uncertainty in the object model. Finally, we demonstrate the advantages of Tac2Pose compared with three baseline methods for tactile pose estimation: directly regressing the object pose with a neural network, matching an observed contact to a set of possible contacts using a standard classification neural network, and direct pixel comparison of an observed contact with a set of possible contacts. Website: http://mcube.mit.edu/research/tac2pose.html
Tactile Object Pose Estimation from the First Touch with Geometric Contact Rendering
Dec 09, 2020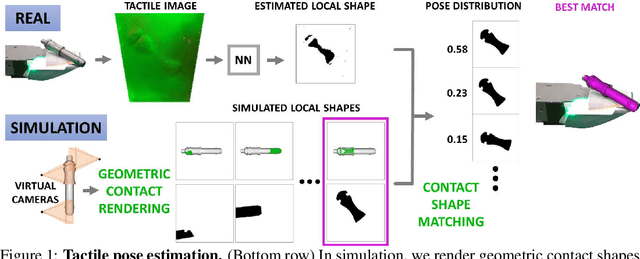


In this paper, we present an approach to tactile pose estimation from the first touch for known objects. First, we create an object-agnostic map from real tactile observations to contact shapes. Next, for a new object with known geometry, we learn a tailored perception model completely in simulation. To do so, we simulate the contact shapes that a dense set of object poses would produce on the sensor. Then, given a new contact shape obtained from the sensor output, we match it against the pre-computed set using the object-specific embedding learned purely in simulation using contrastive learning. This results in a perception model that can localize objects from a single tactile observation. It also allows reasoning over pose distributions and including additional pose constraints coming from other perception systems or multiple contacts. We provide quantitative results for four objects. Our approach provides high accuracy pose estimations from distinctive tactile observations while regressing pose distributions to account for those contact shapes that could result from different object poses. We further extend and test our approach in multi-contact scenarios where several tactile sensors are simultaneously in contact with the object. Website: http://mcube.mit.edu/research/tactile_loc_first_touch.html
Tactile SLAM: Real-time inference of shape and pose from planar pushing
Nov 13, 2020

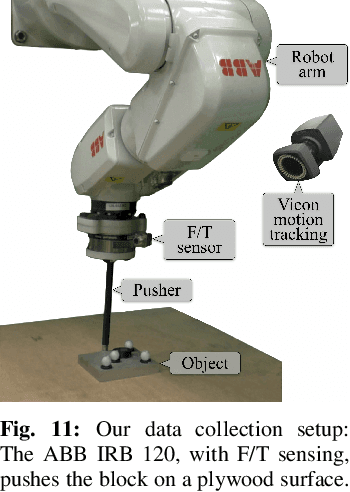
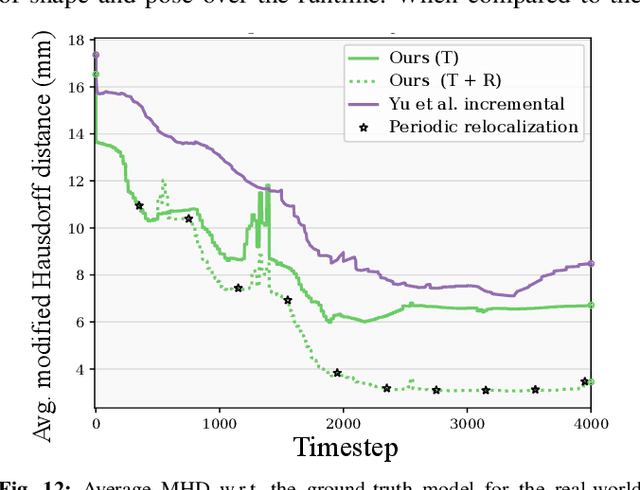
Tactile perception is central to robot manipulation in unstructured environments. However, it requires contact, and a mature implementation must infer object models while also accounting for the motion induced by the interaction. In this work, we present a method to estimate both object shape and pose in real-time from a stream of tactile measurements. This is applied towards tactile exploration of an unknown object by planar pushing. We consider this as an online SLAM problem with a nonparametric shape representation. Our formulation of tactile inference alternates between Gaussian process implicit surface regression and pose estimation on a factor graph. Through a combination of local Gaussian processes and fixed-lag smoothing, we infer object shape and pose in real-time. We evaluate our system across different objects in both simulated and real-world planar pushing tasks.
Tailoring: encoding inductive biases by optimizing unsupervised objectives at prediction time
Oct 14, 2020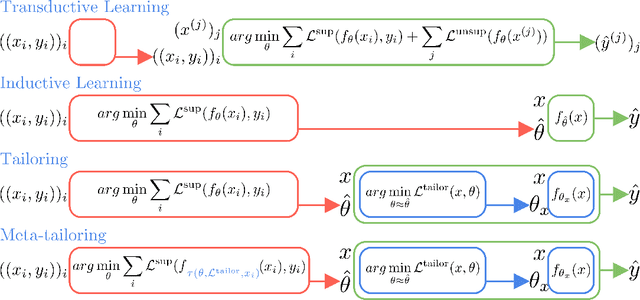
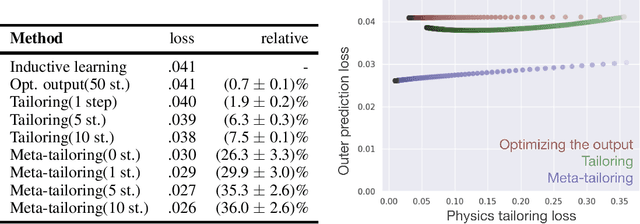
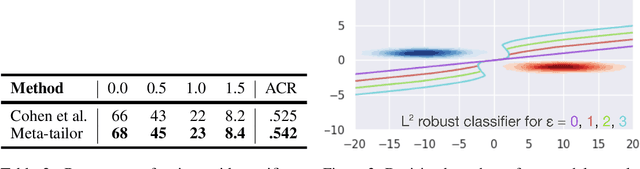
From CNNs to attention mechanisms, encoding inductive biases into neural networks has been a fruitful source of improvement in machine learning. Auxiliary losses are a general way of encoding biases in order to help networks learn better representations by adding extra terms to the loss function. However, since they are minimized on the training data, they suffer from the same generalization gap as regular task losses. Moreover, by changing the loss function, the network is optimizing a different objective than the one we care about. In this work we solve both problems: first, we take inspiration from \textit{transductive learning} and note that, after receiving an input but before making a prediction, we can fine-tune our models on any unsupervised objective. We call this process tailoring, because we customize the model to each input. Second, we formulate a nested optimization (similar to those in meta-learning) and train our models to perform well on the task loss after adapting to the tailoring loss. The advantages of tailoring and meta-tailoring are discussed theoretically and demonstrated empirically on several diverse examples: encoding inductive conservation laws from physics to improve predictions, improving local smoothness to increase robustness to adversarial examples, and using contrastive losses on the query image to improve generalization.