 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Novelty Bottleneck: A Framework for Understanding Human Effort Scaling in AI-Assisted Work
Mar 28, 2026We propose a stylized model of human-AI collaboration that isolates a mechanism we call the novelty bottleneck: the fraction of a task requiring human judgment creates an irreducible serial component analogous to Amdahl's Law in parallel computing. The model assumes that tasks decompose into atomic decisions, a fraction $ν$ of which are "novel" (not covered by the agent's prior), and that specification, verification, and error correction each scale with task size. From these assumptions, we derive several non-obvious consequences: (1) there is no smooth sublinear regime for human effort it transitions sharply from $O(E)$ to $O(1)$ with no intermediate scaling class; (2) better agents improve the coefficient on human effort but not the exponent; (3) for organizations of n humans with AI agents, optimal team size decreases with agent capability; (4) wall-clock time achieves $O(\sqrt{E})$ through team parallelism but total human effort remains $O(E)$; and (5) the resulting AI safety profile is asymmetric -- AI is bottlenecked on frontier research but unbottlenecked on exploiting existing knowledge. We show these predictions are consistent with empirical observations from AI coding benchmarks, scientific productivity data, and practitioner reports. Our contribution is not a proof that human effort must scale linearly, but a framework that identifies the novelty fraction as the key parameter governing AI-assisted productivity, and derives consequences that clarify -- rather than refute -- prevalent narratives about intelligence explosions and the "country of geniuses in a data center."
BPP: Long-Context Robot Imitation Learning by Focusing on Key History Frames
Feb 16, 2026Many robot tasks require attending to the history of past observations. For example, finding an item in a room requires remembering which places have already been searched. However, the best-performing robot policies typically condition only on the current observation, limiting their applicability to such tasks. Naively conditioning on past observations often fails due to spurious correlations: policies latch onto incidental features of training histories that do not generalize to out-of-distribution trajectories upon deployment. We analyze why policies latch onto these spurious correlations and find that this problem stems from limited coverage over the space of possible histories during training, which grows exponentially with horizon. Existing regularization techniques provide inconsistent benefits across tasks, as they do not fundamentally address this coverage problem. Motivated by these findings, we propose Big Picture Policies (BPP), an approach that conditions on a minimal set of meaningful keyframes detected by a vision-language model. By projecting diverse rollouts onto a compact set of task-relevant events, BPP substantially reduces distribution shift between training and deployment, without sacrificing expressivity. We evaluate BPP on four challenging real-world manipulation tasks and three simulation tasks, all requiring history conditioning. BPP achieves 70% higher success rates than the best comparison on real-world evaluations.
Chain-of-Modality: Learning Manipulation Programs from Multimodal Human Videos with Vision-Language-Models
Apr 17, 2025Learning to perform manipulation tasks from human videos is a promising approach for teaching robots. However, many manipulation tasks require changing control parameters during task execution, such as force, which visual data alone cannot capture. In this work, we leverage sensing devices such as armbands that measure human muscle activities and microphones that record sound, to capture the details in the human manipulation process, and enable robots to extract task plans and control parameters to perform the same task. To achieve this, we introduce Chain-of-Modality (CoM), a prompting strategy that enables Vision Language Models to reason about multimodal human demonstration data -- videos coupled with muscle or audio signals. By progressively integrating information from each modality, CoM refines a task plan and generates detailed control parameters, enabling robots to perform manipulation tasks based on a single multimodal human video prompt. Our experiments show that CoM delivers a threefold improvement in accuracy for extracting task plans and control parameters compared to baselines, with strong generalization to new task setups and objects in real-world robot experiments. Videos and code are available at https://chain-of-modality.github.io
Gemini Robotics: Bringing AI into the Physical World
Mar 25, 2025Recent advancements in large multimodal models have led to the emergence of remarkable generalist capabilities in digital domains, yet their translation to physical agents such as robots remains a significant challenge. This report introduces a new family of AI models purposefully designed for robotics and built upon the foundation of Gemini 2.0. We present Gemini Robotics, an advanced Vision-Language-Action (VLA) generalist model capable of directly controlling robots. Gemini Robotics executes smooth and reactive movements to tackle a wide range of complex manipulation tasks while also being robust to variations in object types and positions, handling unseen environments as well as following diverse, open vocabulary instructions. We show that with additional fine-tuning, Gemini Robotics can be specialized to new capabilities including solving long-horizon, highly dexterous tasks, learning new short-horizon tasks from as few as 100 demonstrations and adapting to completely novel robot embodiments. This is made possible because Gemini Robotics builds on top of the Gemini Robotics-ER model, the second model we introduce in this work. Gemini Robotics-ER (Embodied Reasoning) extends Gemini's multimodal reasoning capabilities into the physical world, with enhanced spatial and temporal understanding. This enables capabilities relevant to robotics including object detection, pointing, trajectory and grasp prediction, as well as multi-view correspondence and 3D bounding box predictions. We show how this novel combination can support a variety of robotics applications. We also discuss and address important safety considerations related to this new class of robotics foundation models. The Gemini Robotics family marks a substantial step towards developing general-purpose robots that realizes AI's potential in the physical world.
Vision Language Models are In-Context Value Learners
Nov 07, 2024
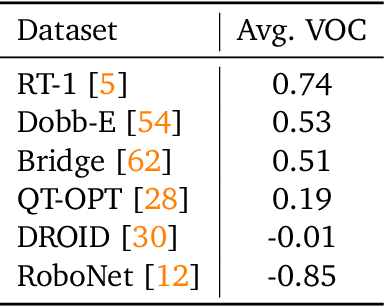
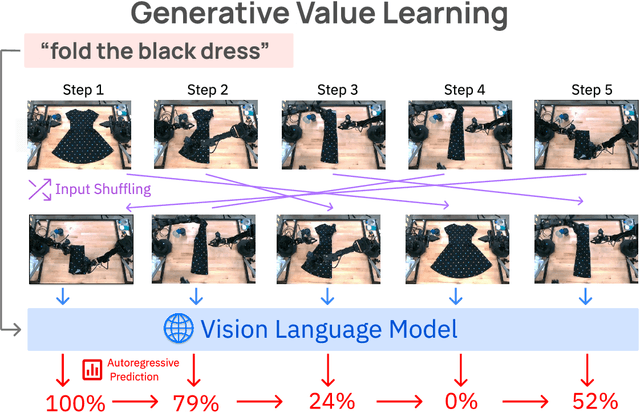
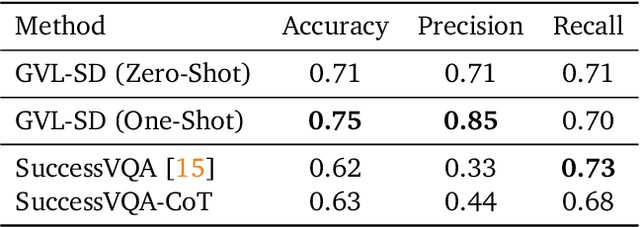
Predicting temporal progress from visual trajectories is important for intelligent robots that can learn, adapt, and improve. However, learning such progress estimator, or temporal value function, across different tasks and domains requires both a large amount of diverse data and methods which can scale and generalize. To address these challenges, we present Generative Value Learning (\GVL), a universal value function estimator that leverages the world knowledge embedded in vision-language models (VLMs) to predict task progress. Naively asking a VLM to predict values for a video sequence performs poorly due to the strong temporal correlation between successive frames. Instead, GVL poses value estimation as a temporal ordering problem over shuffled video frames; this seemingly more challenging task encourages VLMs to more fully exploit their underlying semantic and temporal grounding capabilities to differentiate frames based on their perceived task progress, consequently producing significantly better value predictions. Without any robot or task specific training, GVL can in-context zero-shot and few-shot predict effective values for more than 300 distinct real-world tasks across diverse robot platforms, including challenging bimanual manipulation tasks. Furthermore, we demonstrate that GVL permits flexible multi-modal in-context learning via examples from heterogeneous tasks and embodiments, such as human videos. The generality of GVL enables various downstream applications pertinent to visuomotor policy learning, including dataset filtering, success detection, and advantage-weighted regression -- all without any model training or finetuning.
Learning to Learn Faster from Human Feedback with Language Model Predictive Control
Feb 18, 2024



Large language models (LLMs) have been shown to exhibit a wide range of capabilities, such as writing robot code from language commands -- enabling non-experts to direct robot behaviors, modify them based on feedback, or compose them to perform new tasks. However, these capabilities (driven by in-context learning) are limited to short-term interactions, where users' feedback remains relevant for only as long as it fits within the context size of the LLM, and can be forgotten over longer interactions. In this work, we investigate fine-tuning the robot code-writing LLMs, to remember their in-context interactions and improve their teachability i.e., how efficiently they adapt to human inputs (measured by average number of corrections before the user considers the task successful). Our key observation is that when human-robot interactions are formulated as a partially observable Markov decision process (in which human language inputs are observations, and robot code outputs are actions), then training an LLM to complete previous interactions can be viewed as training a transition dynamics model -- that can be combined with classic robotics techniques such as model predictive control (MPC) to discover shorter paths to success. This gives rise to Language Model Predictive Control (LMPC), a framework that fine-tunes PaLM 2 to improve its teachability on 78 tasks across 5 robot embodiments -- improving non-expert teaching success rates of unseen tasks by 26.9% while reducing the average number of human corrections from 2.4 to 1.9. Experiments show that LMPC also produces strong meta-learners, improving the success rate of in-context learning new tasks on unseen robot embodiments and APIs by 31.5%. See videos, code, and demos at: https://robot-teaching.github.io/.
PIVOT: Iterative Visual Prompting Elicits Actionable Knowledge for VLMs
Feb 12, 2024



Vision language models (VLMs) have shown impressive capabilities across a variety of tasks, from logical reasoning to visual understanding. This opens the door to richer interaction with the world, for example robotic control. However, VLMs produce only textual outputs, while robotic control and other spatial tasks require outputting continuous coordinates, actions, or trajectories. How can we enable VLMs to handle such settings without fine-tuning on task-specific data? In this paper, we propose a novel visual prompting approach for VLMs that we call Prompting with Iterative Visual Optimization (PIVOT), which casts tasks as iterative visual question answering. In each iteration, the image is annotated with a visual representation of proposals that the VLM can refer to (e.g., candidate robot actions, localizations, or trajectories). The VLM then selects the best ones for the task. These proposals are iteratively refined, allowing the VLM to eventually zero in on the best available answer. We investigate PIVOT on real-world robotic navigation, real-world manipulation from images, instruction following in simulation, and additional spatial inference tasks such as localization. We find, perhaps surprisingly, that our approach enables zero-shot control of robotic systems without any robot training data, navigation in a variety of environments, and other capabilities. Although current performance is far from perfect, our work highlights potentials and limitations of this new regime and shows a promising approach for Internet-Scale VLMs in robotic and spatial reasoning domains. Website: pivot-prompt.github.io and HuggingFace: https://huggingface.co/spaces/pivot-prompt/pivot-prompt-demo.
Chain of Code: Reasoning with a Language Model-Augmented Code Emulator
Dec 08, 2023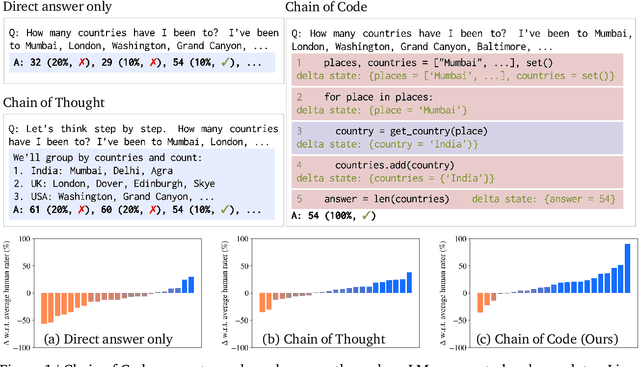



Code provides a general syntactic structure to build complex programs and perform precise computations when paired with a code interpreter - we hypothesize that language models (LMs) can leverage code-writing to improve Chain of Thought reasoning not only for logic and arithmetic tasks, but also for semantic ones (and in particular, those that are a mix of both). For example, consider prompting an LM to write code that counts the number of times it detects sarcasm in an essay: the LM may struggle to write an implementation for "detect_sarcasm(string)" that can be executed by the interpreter (handling the edge cases would be insurmountable). However, LMs may still produce a valid solution if they not only write code, but also selectively "emulate" the interpreter by generating the expected output of "detect_sarcasm(string)" and other lines of code that cannot be executed. In this work, we propose Chain of Code (CoC), a simple yet surprisingly effective extension that improves LM code-driven reasoning. The key idea is to encourage LMs to format semantic sub-tasks in a program as flexible pseudocode that the interpreter can explicitly catch undefined behaviors and hand off to simulate with an LM (as an "LMulator"). Experiments demonstrate that Chain of Code outperforms Chain of Thought and other baselines across a variety of benchmarks; on BIG-Bench Hard, Chain of Code achieves 84%, a gain of 12% over Chain of Thought. CoC scales well with large and small models alike, and broadens the scope of reasoning questions that LMs can correctly answer by "thinking in code". Project webpage: https://chain-of-code.github.io.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Code as Policies: Language Model Programs for Embodied Control
Sep 19, 2022

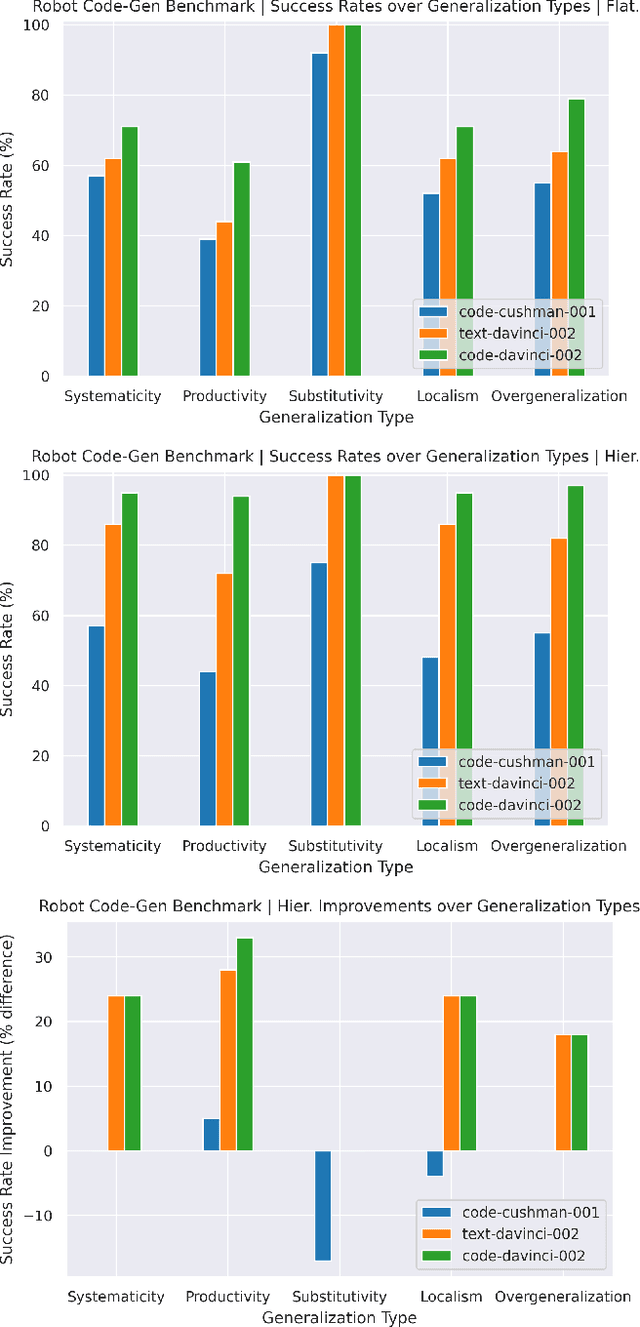
Large language models (LLMs) trained on code completion have been shown to be capable of synthesizing simple Python programs from docstrings [1]. We find that these code-writing LLMs can be re-purposed to write robot policy code, given natural language commands. Specifically, policy code can express functions or feedback loops that process perception outputs (e.g.,from object detectors [2], [3]) and parameterize control primitive APIs. When provided as input several example language commands (formatted as comments) followed by corresponding policy code (via few-shot prompting), LLMs can take in new commands and autonomously re-compose API calls to generate new policy code respectively. By chaining classic logic structures and referencing third-party libraries (e.g., NumPy, Shapely) to perform arithmetic, LLMs used in this way can write robot policies that (i) exhibit spatial-geometric reasoning, (ii) generalize to new instructions, and (iii) prescribe precise values (e.g., velocities) to ambiguous descriptions ("faster") depending on context (i.e., behavioral commonsense). This paper presents code as policies: a robot-centric formalization of language model generated programs (LMPs) that can represent reactive policies (e.g., impedance controllers), as well as waypoint-based policies (vision-based pick and place, trajectory-based control), demonstrated across multiple real robot platforms. Central to our approach is prompting hierarchical code-gen (recursively defining undefined functions), which can write more complex code and also improves state-of-the-art to solve 39.8% of problems on the HumanEval [1] benchmark. Code and videos are available at https://code-as-policies.github.io