 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeROI-Driven Foveated Attention for Unified Egocentric Representations in Vision-Language-Action Systems
Mar 21, 2026The development of embodied AI systems is increasingly constrained by the availability and structure of physical interaction data. Despite recent advances in vision-language-action (VLA) models, current pipelines suffer from high data collection cost, limited cross-embodiment alignment, and poor transfer from internet-scale visual data to robot control. We propose a region-of-interest (ROI) driven engineering workflow that introduces an egocentric, geometry-grounded data representation. By projecting end-effector poses via forward kinematics (FK) into a single external camera, we derive movement-aligned hand-centric ROIs without requiring wrist-mounted cameras or multi-view systems. Unlike directly downsampling the full frame, ROI is cropped from the original image before resizing, preserving high local information density for contact-critical regions while retaining global context. We present a reproducible pipeline covering calibration, synchronization, ROI generation, deterministic boundary handling, and metadata governance. The resulting representation is embodiment-aligned and viewpoint-normalized, enabling data reuse across heterogeneous robots. We argue that egocentric ROI serves as a practical data abstraction for scalable collection and cross-embodiment learning, bridging internet-scale perception and robot-specific control.
SaiVLA-0: Cerebrum--Pons--Cerebellum Tripartite Architecture for Compute-Aware Vision-Language-Action
Mar 09, 2026We revisit Vision-Language-Action through a neuroscience-inspired triad. Biologically, the Cerebrum provides stable high-level multimodal priors and remains frozen; the Pons Adapter integrates these cortical features with real-time proprioceptive inputs and compiles intent into execution-ready tokens; and the Cerebellum (ParaCAT) performs fast, parallel categorical decoding for online control, with hysteresis/EMA/temperature/entropy for stability. A fixed-ratio schedule and two-stage feature caching make the system compute-aware and reproducible. Inspired by active, foveated vision, our wrist ROIs are geometrically tied to the end-effector via calibrated projection, providing a movement-stabilized, high-resolution view that is sensitive to fine-grained pose changes and complements the global context of the main view. The design is modular: upgrading the Cerebrum only retrains the Pons; changing robots only trains the Cerebellum; cerebellum-only RL can further refine control without touching high-level semantics. As a concept-and-protocol paper with preliminary evidence, we outline a timing protocol under matched conditions (GPU, resolution, batch) to verify anticipated efficiency gains. We also report preliminary LIBERO evidence showing that split feature caching reduces training time (7.5h to 4.5h) and improves average success (86.5% to 92.5%) under official N1.5 head-only training, and that SaiVLA0 reaches 99.0% mean success.
PointWorld: Scaling 3D World Models for In-The-Wild Robotic Manipulation
Jan 07, 2026Humans anticipate, from a glance and a contemplated action of their bodies, how the 3D world will respond, a capability that is equally vital for robotic manipulation. We introduce PointWorld, a large pre-trained 3D world model that unifies state and action in a shared 3D space as 3D point flows: given one or few RGB-D images and a sequence of low-level robot action commands, PointWorld forecasts per-pixel displacements in 3D that respond to the given actions. By representing actions as 3D point flows instead of embodiment-specific action spaces (e.g., joint positions), this formulation directly conditions on physical geometries of robots while seamlessly integrating learning across embodiments. To train our 3D world model, we curate a large-scale dataset spanning real and simulated robotic manipulation in open-world environments, enabled by recent advances in 3D vision and simulated environments, totaling about 2M trajectories and 500 hours across a single-arm Franka and a bimanual humanoid. Through rigorous, large-scale empirical studies of backbones, action representations, learning objectives, partial observability, data mixtures, domain transfers, and scaling, we distill design principles for large-scale 3D world modeling. With a real-time (0.1s) inference speed, PointWorld can be efficiently integrated in the model-predictive control (MPC) framework for manipulation. We demonstrate that a single pre-trained checkpoint enables a real-world Franka robot to perform rigid-body pushing, deformable and articulated object manipulation, and tool use, without requiring any demonstrations or post-training and all from a single image captured in-the-wild. Project website at https://point-world.github.io/.
Dream2Flow: Bridging Video Generation and Open-World Manipulation with 3D Object Flow
Dec 31, 2025Generative video modeling has emerged as a compelling tool to zero-shot reason about plausible physical interactions for open-world manipulation. Yet, it remains a challenge to translate such human-led motions into the low-level actions demanded by robotic systems. We observe that given an initial image and task instruction, these models excel at synthesizing sensible object motions. Thus, we introduce Dream2Flow, a framework that bridges video generation and robotic control through 3D object flow as an intermediate representation. Our method reconstructs 3D object motions from generated videos and formulates manipulation as object trajectory tracking. By separating the state changes from the actuators that realize those changes, Dream2Flow overcomes the embodiment gap and enables zero-shot guidance from pre-trained video models to manipulate objects of diverse categories-including rigid, articulated, deformable, and granular. Through trajectory optimization or reinforcement learning, Dream2Flow converts reconstructed 3D object flow into executable low-level commands without task-specific demonstrations. Simulation and real-world experiments highlight 3D object flow as a general and scalable interface for adapting video generation models to open-world robotic manipulation. Videos and visualizations are available at https://dream2flow.github.io/.
UAD: Unsupervised Affordance Distillation for Generalization in Robotic Manipulation
Jun 10, 2025Understanding fine-grained object affordances is imperative for robots to manipulate objects in unstructured environments given open-ended task instructions. However, existing methods of visual affordance predictions often rely on manually annotated data or conditions only on a predefined set of tasks. We introduce UAD (Unsupervised Affordance Distillation), a method for distilling affordance knowledge from foundation models into a task-conditioned affordance model without any manual annotations. By leveraging the complementary strengths of large vision models and vision-language models, UAD automatically annotates a large-scale dataset with detailed $<$instruction, visual affordance$>$ pairs. Training only a lightweight task-conditioned decoder atop frozen features, UAD exhibits notable generalization to in-the-wild robotic scenes and to various human activities, despite only being trained on rendered objects in simulation. Using affordance provided by UAD as the observation space, we show an imitation learning policy that demonstrates promising generalization to unseen object instances, object categories, and even variations in task instructions after training on as few as 10 demonstrations. Project website: https://unsup-affordance.github.io/
A Real-to-Sim-to-Real Approach to Robotic Manipulation with VLM-Generated Iterative Keypoint Rewards
Feb 12, 2025Task specification for robotic manipulation in open-world environments is challenging, requiring flexible and adaptive objectives that align with human intentions and can evolve through iterative feedback. We introduce Iterative Keypoint Reward (IKER), a visually grounded, Python-based reward function that serves as a dynamic task specification. Our framework leverages VLMs to generate and refine these reward functions for multi-step manipulation tasks. Given RGB-D observations and free-form language instructions, we sample keypoints in the scene and generate a reward function conditioned on these keypoints. IKER operates on the spatial relationships between keypoints, leveraging commonsense priors about the desired behaviors, and enabling precise SE(3) control. We reconstruct real-world scenes in simulation and use the generated rewards to train reinforcement learning (RL) policies, which are then deployed into the real world-forming a real-to-sim-to-real loop. Our approach demonstrates notable capabilities across diverse scenarios, including both prehensile and non-prehensile tasks, showcasing multi-step task execution, spontaneous error recovery, and on-the-fly strategy adjustments. The results highlight IKER's effectiveness in enabling robots to perform multi-step tasks in dynamic environments through iterative reward shaping.
ReKep: Spatio-Temporal Reasoning of Relational Keypoint Constraints for Robotic Manipulation
Sep 03, 2024



Representing robotic manipulation tasks as constraints that associate the robot and the environment is a promising way to encode desired robot behaviors. However, it remains unclear how to formulate the constraints such that they are 1) versatile to diverse tasks, 2) free of manual labeling, and 3) optimizable by off-the-shelf solvers to produce robot actions in real-time. In this work, we introduce Relational Keypoint Constraints (ReKep), a visually-grounded representation for constraints in robotic manipulation. Specifically, ReKep is expressed as Python functions mapping a set of 3D keypoints in the environment to a numerical cost. We demonstrate that by representing a manipulation task as a sequence of Relational Keypoint Constraints, we can employ a hierarchical optimization procedure to solve for robot actions (represented by a sequence of end-effector poses in SE(3)) with a perception-action loop at a real-time frequency. Furthermore, in order to circumvent the need for manual specification of ReKep for each new task, we devise an automated procedure that leverages large vision models and vision-language models to produce ReKep from free-form language instructions and RGB-D observations. We present system implementations on a wheeled single-arm platform and a stationary dual-arm platform that can perform a large variety of manipulation tasks, featuring multi-stage, in-the-wild, bimanual, and reactive behaviors, all without task-specific data or environment models. Website at https://rekep-robot.github.io.
VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Jul 12, 2023Large language models (LLMs) are shown to possess a wealth of actionable knowledge that can be extracted for robot manipulation in the form of reasoning and planning. Despite the progress, most still rely on pre-defined motion primitives to carry out the physical interactions with the environment, which remains a major bottleneck. In this work, we aim to synthesize robot trajectories, i.e., a dense sequence of 6-DoF end-effector waypoints, for a large variety of manipulation tasks given an open-set of instructions and an open-set of objects. We achieve this by first observing that LLMs excel at inferring affordances and constraints given a free-form language instruction. More importantly, by leveraging their code-writing capabilities, they can interact with a visual-language model (VLM) to compose 3D value maps to ground the knowledge into the observation space of the agent. The composed value maps are then used in a model-based planning framework to zero-shot synthesize closed-loop robot trajectories with robustness to dynamic perturbations. We further demonstrate how the proposed framework can benefit from online experiences by efficiently learning a dynamics model for scenes that involve contact-rich interactions. We present a large-scale study of the proposed method in both simulated and real-robot environments, showcasing the ability to perform a large variety of everyday manipulation tasks specified in free-form natural language. Project website: https://voxposer.github.io
PaLM-E: An Embodied Multimodal Language Model
Mar 06, 2023

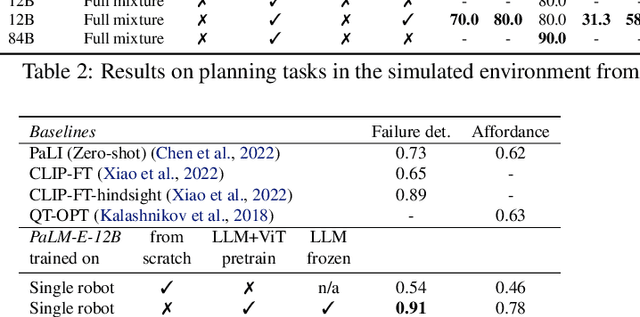

Large language models excel at a wide range of complex tasks. However, enabling general inference in the real world, e.g., for robotics problems, raises the challenge of grounding. We propose embodied language models to directly incorporate real-world continuous sensor modalities into language models and thereby establish the link between words and percepts. Input to our embodied language model are multi-modal sentences that interleave visual, continuous state estimation, and textual input encodings. We train these encodings end-to-end, in conjunction with a pre-trained large language model, for multiple embodied tasks including sequential robotic manipulation planning, visual question answering, and captioning. Our evaluations show that PaLM-E, a single large embodied multimodal model, can address a variety of embodied reasoning tasks, from a variety of observation modalities, on multiple embodiments, and further, exhibits positive transfer: the model benefits from diverse joint training across internet-scale language, vision, and visual-language domains. Our largest model, PaLM-E-562B with 562B parameters, in addition to being trained on robotics tasks, is a visual-language generalist with state-of-the-art performance on OK-VQA, and retains generalist language capabilities with increasing scale.
Grounded Decoding: Guiding Text Generation with Grounded Models for Robot Control
Mar 01, 2023



Recent progress in large language models (LLMs) has demonstrated the ability to learn and leverage Internet-scale knowledge through pre-training with autoregressive models. Unfortunately, applying such models to settings with embodied agents, such as robots, is challenging due to their lack of experience with the physical world, inability to parse non-language observations, and ignorance of rewards or safety constraints that robots may require. On the other hand, language-conditioned robotic policies that learn from interaction data can provide the necessary grounding that allows the agent to be correctly situated in the real world, but such policies are limited by the lack of high-level semantic understanding due to the limited breadth of the interaction data available for training them. Thus, if we want to make use of the semantic knowledge in a language model while still situating it in an embodied setting, we must construct an action sequence that is both likely according to the language model and also realizable according to grounded models of the environment. We frame this as a problem similar to probabilistic filtering: decode a sequence that both has high probability under the language model and high probability under a set of grounded model objectives. We demonstrate this guided decoding strategy is able to solve complex, long-horizon embodiment tasks in a robotic setting by leveraging the knowledge of both models. The project's website can be found at grounded-decoding.github.io.