 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUAD: Unsupervised Affordance Distillation for Generalization in Robotic Manipulation
Jun 10, 2025Understanding fine-grained object affordances is imperative for robots to manipulate objects in unstructured environments given open-ended task instructions. However, existing methods of visual affordance predictions often rely on manually annotated data or conditions only on a predefined set of tasks. We introduce UAD (Unsupervised Affordance Distillation), a method for distilling affordance knowledge from foundation models into a task-conditioned affordance model without any manual annotations. By leveraging the complementary strengths of large vision models and vision-language models, UAD automatically annotates a large-scale dataset with detailed $<$instruction, visual affordance$>$ pairs. Training only a lightweight task-conditioned decoder atop frozen features, UAD exhibits notable generalization to in-the-wild robotic scenes and to various human activities, despite only being trained on rendered objects in simulation. Using affordance provided by UAD as the observation space, we show an imitation learning policy that demonstrates promising generalization to unseen object instances, object categories, and even variations in task instructions after training on as few as 10 demonstrations. Project website: https://unsup-affordance.github.io/
BEHAVIOR Vision Suite: Customizable Dataset Generation via Simulation
May 15, 2024



The systematic evaluation and understanding of computer vision models under varying conditions require large amounts of data with comprehensive and customized labels, which real-world vision datasets rarely satisfy. While current synthetic data generators offer a promising alternative, particularly for embodied AI tasks, they often fall short for computer vision tasks due to low asset and rendering quality, limited diversity, and unrealistic physical properties. We introduce the BEHAVIOR Vision Suite (BVS), a set of tools and assets to generate fully customized synthetic data for systematic evaluation of computer vision models, based on the newly developed embodied AI benchmark, BEHAVIOR-1K. BVS supports a large number of adjustable parameters at the scene level (e.g., lighting, object placement), the object level (e.g., joint configuration, attributes such as "filled" and "folded"), and the camera level (e.g., field of view, focal length). Researchers can arbitrarily vary these parameters during data generation to perform controlled experiments. We showcase three example application scenarios: systematically evaluating the robustness of models across different continuous axes of domain shift, evaluating scene understanding models on the same set of images, and training and evaluating simulation-to-real transfer for a novel vision task: unary and binary state prediction. Project website: https://behavior-vision-suite.github.io/
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
Feb 09, 2023Generalizable manipulation skills, which can be composed to tackle long-horizon and complex daily chores, are one of the cornerstones of Embodied AI. However, existing benchmarks, mostly composed of a suite of simulatable environments, are insufficient to push cutting-edge research works because they lack object-level topological and geometric variations, are not based on fully dynamic simulation, or are short of native support for multiple types of manipulation tasks. To this end, we present ManiSkill2, the next generation of the SAPIEN ManiSkill benchmark, to address critical pain points often encountered by researchers when using benchmarks for generalizable manipulation skills. ManiSkill2 includes 20 manipulation task families with 2000+ object models and 4M+ demonstration frames, which cover stationary/mobile-base, single/dual-arm, and rigid/soft-body manipulation tasks with 2D/3D-input data simulated by fully dynamic engines. It defines a unified interface and evaluation protocol to support a wide range of algorithms (e.g., classic sense-plan-act, RL, IL), visual observations (point cloud, RGBD), and controllers (e.g., action type and parameterization). Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a regular workstation. It implements a render server infrastructure to allow sharing rendering resources across all environments, thereby significantly reducing memory usage. We open-source all codes of our benchmark (simulator, environments, and baselines) and host an online challenge open to interdisciplinary researchers.
Humble Teachers Teach Better Students for Semi-Supervised Object Detection
Jun 19, 2021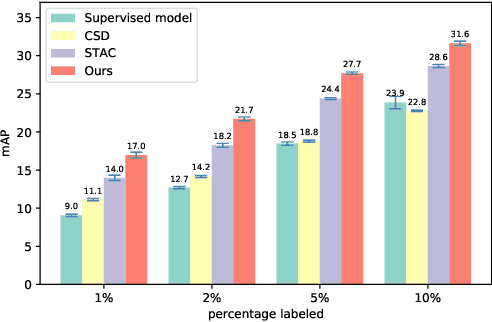
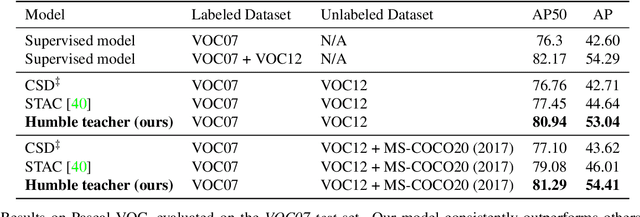

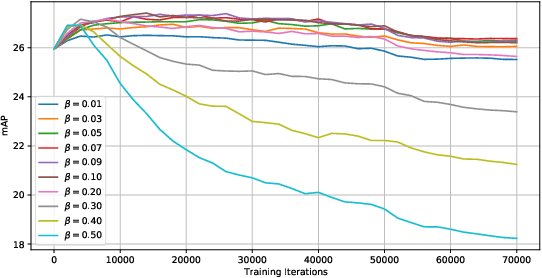
We propose a semi-supervised approach for contemporary object detectors following the teacher-student dual model framework. Our method is featured with 1) the exponential moving averaging strategy to update the teacher from the student online, 2) using plenty of region proposals and soft pseudo-labels as the student's training targets, and 3) a light-weighted detection-specific data ensemble for the teacher to generate more reliable pseudo-labels. Compared to the recent state-of-the-art -- STAC, which uses hard labels on sparsely selected hard pseudo samples, the teacher in our model exposes richer information to the student with soft-labels on many proposals. Our model achieves COCO-style AP of 53.04% on VOC07 val set, 8.4% better than STAC, when using VOC12 as unlabeled data. On MS-COCO, it outperforms prior work when only a small percentage of data is taken as labeled. It also reaches 53.8% AP on MS-COCO test-dev with 3.1% gain over the fully supervised ResNet-152 Cascaded R-CNN, by tapping into unlabeled data of a similar size to the labeled data.
Premise Selection for Theorem Proving by Deep Graph Embedding
Sep 28, 2017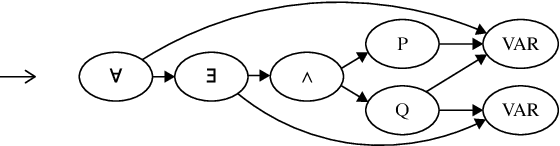

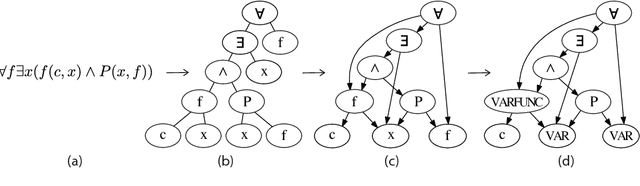

We propose a deep learning-based approach to the problem of premise selection: selecting mathematical statements relevant for proving a given conjecture. We represent a higher-order logic formula as a graph that is invariant to variable renaming but still fully preserves syntactic and semantic information. We then embed the graph into a vector via a novel embedding method that preserves the information of edge ordering. Our approach achieves state-of-the-art results on the HolStep dataset, improving the classification accuracy from 83% to 90.3%.