 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvances and Innovations in the Multi-Agent Robotic System (MARS) Challenge
Jan 26, 2026Recent advancements in multimodal large language models and vision-languageaction models have significantly driven progress in Embodied AI. As the field transitions toward more complex task scenarios, multi-agent system frameworks are becoming essential for achieving scalable, efficient, and collaborative solutions. This shift is fueled by three primary factors: increasing agent capabilities, enhancing system efficiency through task delegation, and enabling advanced human-agent interactions. To address the challenges posed by multi-agent collaboration, we propose the Multi-Agent Robotic System (MARS) Challenge, held at the NeurIPS 2025 Workshop on SpaVLE. The competition focuses on two critical areas: planning and control, where participants explore multi-agent embodied planning using vision-language models (VLMs) to coordinate tasks and policy execution to perform robotic manipulation in dynamic environments. By evaluating solutions submitted by participants, the challenge provides valuable insights into the design and coordination of embodied multi-agent systems, contributing to the future development of advanced collaborative AI systems.
Multi-Stage Manipulation with Demonstration-Augmented Reward, Policy, and World Model Learning
Mar 03, 2025



Long-horizon tasks in robotic manipulation present significant challenges in reinforcement learning (RL) due to the difficulty of designing dense reward functions and effectively exploring the expansive state-action space. However, despite a lack of dense rewards, these tasks often have a multi-stage structure, which can be leveraged to decompose the overall objective into manageable subgoals. In this work, we propose DEMO3, a framework that exploits this structure for efficient learning from visual inputs. Specifically, our approach incorporates multi-stage dense reward learning, a bi-phasic training scheme, and world model learning into a carefully designed demonstration-augmented RL framework that strongly mitigates the challenge of exploration in long-horizon tasks. Our evaluations demonstrate that our method improves data-efficiency by an average of 40% and by 70% on particularly difficult tasks compared to state-of-the-art approaches. We validate this across 16 sparse-reward tasks spanning four domains, including challenging humanoid visual control tasks using as few as five demonstrations.
Policy Decorator: Model-Agnostic Online Refinement for Large Policy Model
Dec 18, 2024



Recent advancements in robot learning have used imitation learning with large models and extensive demonstrations to develop effective policies. However, these models are often limited by the quantity, quality, and diversity of demonstrations. This paper explores improving offline-trained imitation learning models through online interactions with the environment. We introduce Policy Decorator, which uses a model-agnostic residual policy to refine large imitation learning models during online interactions. By implementing controlled exploration strategies, Policy Decorator enables stable, sample-efficient online learning. Our evaluation spans eight tasks across two benchmarks-ManiSkill and Adroit-and involves two state-of-the-art imitation learning models (Behavior Transformer and Diffusion Policy). The results show Policy Decorator effectively improves the offline-trained policies and preserves the smooth motion of imitation learning models, avoiding the erratic behaviors of pure RL policies. See our project page (https://policydecorator.github.io) for videos.
ManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
Reverse Forward Curriculum Learning for Extreme Sample and Demonstration Efficiency in Reinforcement Learning
May 06, 2024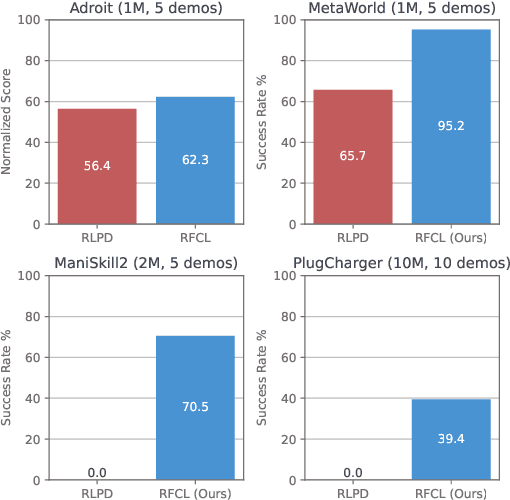

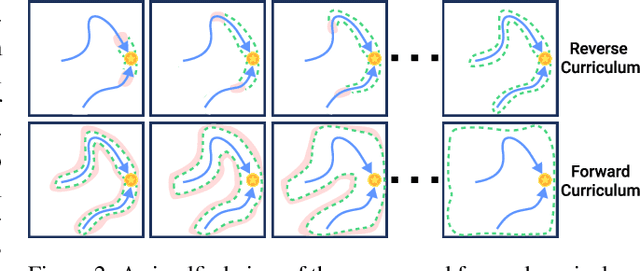

Reinforcement learning (RL) presents a promising framework to learn policies through environment interaction, but often requires an infeasible amount of interaction data to solve complex tasks from sparse rewards. One direction includes augmenting RL with offline data demonstrating desired tasks, but past work often require a lot of high-quality demonstration data that is difficult to obtain, especially for domains such as robotics. Our approach consists of a reverse curriculum followed by a forward curriculum. Unique to our approach compared to past work is the ability to efficiently leverage more than one demonstration via a per-demonstration reverse curriculum generated via state resets. The result of our reverse curriculum is an initial policy that performs well on a narrow initial state distribution and helps overcome difficult exploration problems. A forward curriculum is then used to accelerate the training of the initial policy to perform well on the full initial state distribution of the task and improve demonstration and sample efficiency. We show how the combination of a reverse curriculum and forward curriculum in our method, RFCL, enables significant improvements in demonstration and sample efficiency compared against various state-of-the-art learning-from-demonstration baselines, even solving previously unsolvable tasks that require high precision and control.
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
Feb 09, 2023Generalizable manipulation skills, which can be composed to tackle long-horizon and complex daily chores, are one of the cornerstones of Embodied AI. However, existing benchmarks, mostly composed of a suite of simulatable environments, are insufficient to push cutting-edge research works because they lack object-level topological and geometric variations, are not based on fully dynamic simulation, or are short of native support for multiple types of manipulation tasks. To this end, we present ManiSkill2, the next generation of the SAPIEN ManiSkill benchmark, to address critical pain points often encountered by researchers when using benchmarks for generalizable manipulation skills. ManiSkill2 includes 20 manipulation task families with 2000+ object models and 4M+ demonstration frames, which cover stationary/mobile-base, single/dual-arm, and rigid/soft-body manipulation tasks with 2D/3D-input data simulated by fully dynamic engines. It defines a unified interface and evaluation protocol to support a wide range of algorithms (e.g., classic sense-plan-act, RL, IL), visual observations (point cloud, RGBD), and controllers (e.g., action type and parameterization). Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a regular workstation. It implements a render server infrastructure to allow sharing rendering resources across all environments, thereby significantly reducing memory usage. We open-source all codes of our benchmark (simulator, environments, and baselines) and host an online challenge open to interdisciplinary researchers.
Emergent collective intelligence from massive-agent cooperation and competition
Jan 05, 2023



Inspired by organisms evolving through cooperation and competition between different populations on Earth, we study the emergence of artificial collective intelligence through massive-agent reinforcement learning. To this end, We propose a new massive-agent reinforcement learning environment, Lux, where dynamic and massive agents in two teams scramble for limited resources and fight off the darkness. In Lux, we build our agents through the standard reinforcement learning algorithm in curriculum learning phases and leverage centralized control via a pixel-to-pixel policy network. As agents co-evolve through self-play, we observe several stages of intelligence, from the acquisition of atomic skills to the development of group strategies. Since these learned group strategies arise from individual decisions without an explicit coordination mechanism, we claim that artificial collective intelligence emerges from massive-agent cooperation and competition. We further analyze the emergence of various learned strategies through metrics and ablation studies, aiming to provide insights for reinforcement learning implementations in massive-agent environments.
Abstract-to-Executable Trajectory Translation for One-Shot Task Generalization
Oct 14, 2022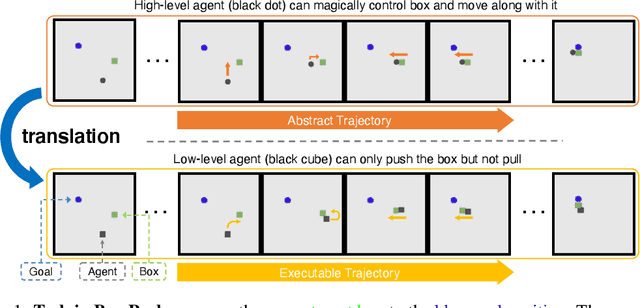
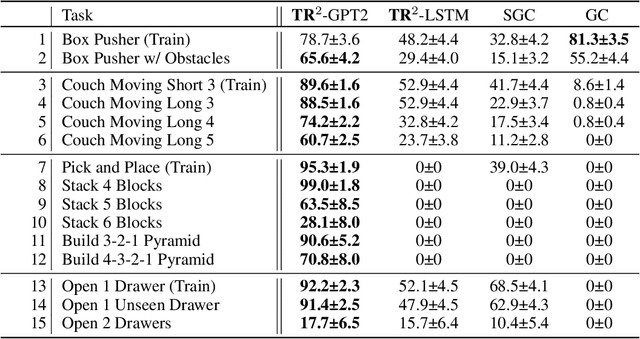
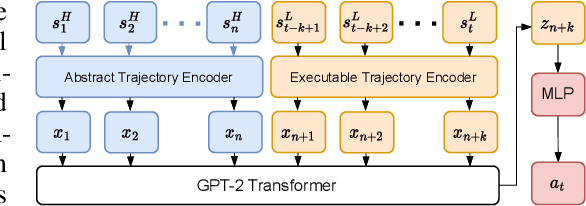
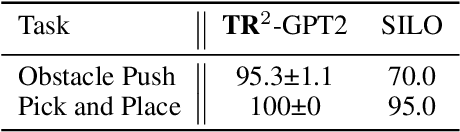
Training long-horizon robotic policies in complex physical environments is essential for many applications, such as robotic manipulation. However, learning a policy that can generalize to unseen tasks is challenging. In this work, we propose to achieve one-shot task generalization by decoupling plan generation and plan execution. Specifically, our method solves complex long-horizon tasks in three steps: build a paired abstract environment by simplifying geometry and physics, generate abstract trajectories, and solve the original task by an abstract-to-executable trajectory translator. In the abstract environment, complex dynamics such as physical manipulation are removed, making abstract trajectories easier to generate. However, this introduces a large domain gap between abstract trajectories and the actual executed trajectories as abstract trajectories lack low-level details and are not aligned frame-to-frame with the executed trajectory. In a manner reminiscent of language translation, our approach leverages a seq-to-seq model to overcome the large domain gap between the abstract and executable trajectories, enabling the low-level policy to follow the abstract trajectory. Experimental results on various unseen long-horizon tasks with different robot embodiments demonstrate the practicability of our methods to achieve one-shot task generalization.
ManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
Aug 09, 2021
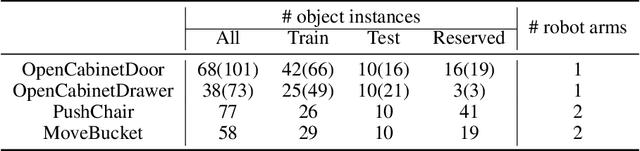
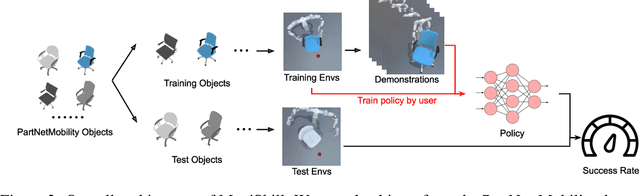

Learning generalizable manipulation skills is central for robots to achieve task automation in environments with endless scene and object variations. However, existing robot learning environments are limited in both scale and diversity of 3D assets (especially of articulated objects), making it difficult to train and evaluate the generalization ability of agents over novel objects. In this work, we focus on object-level generalization and propose SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill), a large-scale learning-from-demonstrations benchmark for articulated object manipulation with 3D visual input (point cloud and RGB-D image). ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects. We equip ManiSkill with a large number of high-quality demonstrations to facilitate learning-from-demonstrations approaches and perform evaluations on baseline algorithms. We believe that ManiSkill can encourage the robot learning community to explore more on learning generalizable object manipulation skills.