 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePast- and Future-Informed KV Cache Policy with Salience Estimation in Autoregressive Video Diffusion
Jan 29, 2026Video generation is pivotal to digital media creation, and recent advances in autoregressive video generation have markedly enhanced the efficiency of real-time video synthesis. However, existing approaches generally rely on heuristic KV Cache policies, which ignore differences in token importance in long-term video generation. This leads to the loss of critical spatiotemporal information and the accumulation of redundant, invalid cache, thereby degrading video generation quality and efficiency. To address this limitation, we first observe that token contributions to video generation are highly time-heterogeneous and accordingly propose a novel Past- and Future-Informed KV Cache Policy (PaFu-KV). Specifically, PaFu-KV introduces a lightweight Salience Estimation Head distilled from a bidirectional teacher to estimate salience scores, allowing the KV cache to retain informative tokens while discarding less relevant ones. This policy yields a better quality-efficiency trade-off by shrinking KV cache capacity and reducing memory footprint at inference time. Extensive experiments on benchmarks demonstrate that our method preserves high-fidelity video generation quality while enables accelerated inference, thereby enabling more efficient long-horizon video generation. Our code will be released upon paper acceptance.
Beyond Global Alignment: Fine-Grained Motion-Language Retrieval via Pyramidal Shapley-Taylor Learning
Jan 29, 2026As a foundational task in human-centric cross-modal intelligence, motion-language retrieval aims to bridge the semantic gap between natural language and human motion, enabling intuitive motion analysis, yet existing approaches predominantly focus on aligning entire motion sequences with global textual representations. This global-centric paradigm overlooks fine-grained interactions between local motion segments and individual body joints and text tokens, inevitably leading to suboptimal retrieval performance. To address this limitation, we draw inspiration from the pyramidal process of human motion perception (from joint dynamics to segment coherence, and finally to holistic comprehension) and propose a novel Pyramidal Shapley-Taylor (PST) learning framework for fine-grained motion-language retrieval. Specifically, the framework decomposes human motion into temporal segments and spatial body joints, and learns cross-modal correspondences through progressive joint-wise and segment-wise alignment in a pyramidal fashion, effectively capturing both local semantic details and hierarchical structural relationships. Extensive experiments on multiple public benchmark datasets demonstrate that our approach significantly outperforms state-of-the-art methods, achieving precise alignment between motion segments and body joints and their corresponding text tokens. The code of this work will be released upon acceptance.
AStF: Motion Style Transfer via Adaptive Statistics Fusor
Nov 06, 2025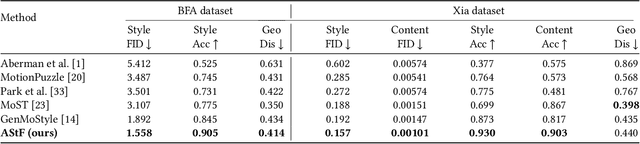
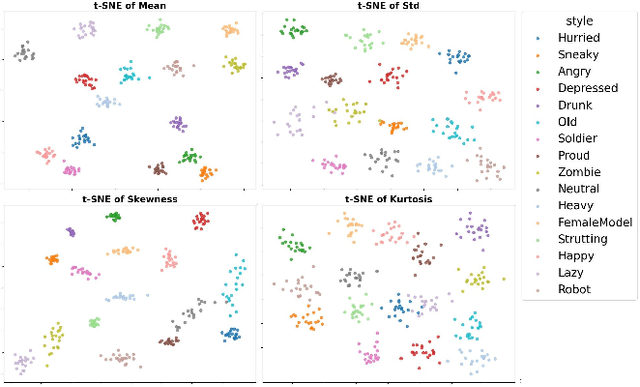
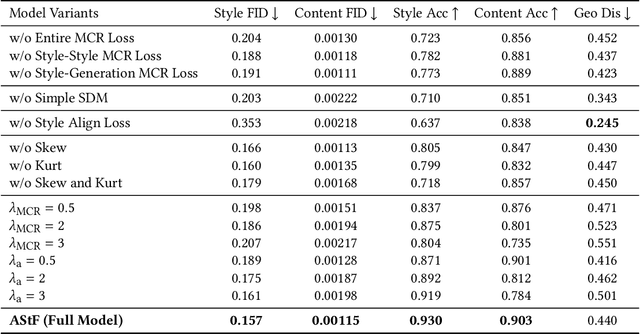
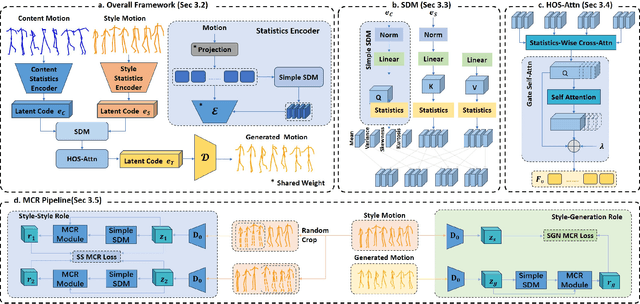
Human motion style transfer allows characters to appear less rigidity and more realism with specific style. Traditional arbitrary image style transfer typically process mean and variance which is proved effective. Meanwhile, similar methods have been adapted for motion style transfer. However, due to the fundamental differences between images and motion, relying on mean and variance is insufficient to fully capture the complex dynamic patterns and spatiotemporal coherence properties of motion data. Building upon this, our key insight is to bring two more coefficient, skewness and kurtosis, into the analysis of motion style. Specifically, we propose a novel Adaptive Statistics Fusor (AStF) which consists of Style Disentanglement Module (SDM) and High-Order Multi-Statistics Attention (HOS-Attn). We trained our AStF in conjunction with a Motion Consistency Regularization (MCR) discriminator. Experimental results show that, by providing a more comprehensive model of the spatiotemporal statistical patterns inherent in dynamic styles, our proposed AStF shows proficiency superiority in motion style transfers over state-of-the-arts. Our code and model are available at https://github.com/CHMimilanlan/AStF.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
Emergent collective intelligence from massive-agent cooperation and competition
Jan 05, 2023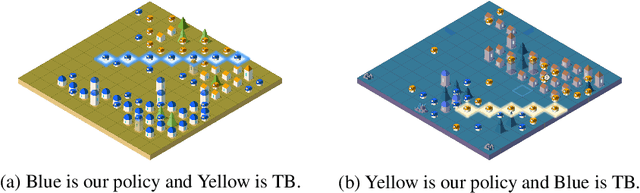



Inspired by organisms evolving through cooperation and competition between different populations on Earth, we study the emergence of artificial collective intelligence through massive-agent reinforcement learning. To this end, We propose a new massive-agent reinforcement learning environment, Lux, where dynamic and massive agents in two teams scramble for limited resources and fight off the darkness. In Lux, we build our agents through the standard reinforcement learning algorithm in curriculum learning phases and leverage centralized control via a pixel-to-pixel policy network. As agents co-evolve through self-play, we observe several stages of intelligence, from the acquisition of atomic skills to the development of group strategies. Since these learned group strategies arise from individual decisions without an explicit coordination mechanism, we claim that artificial collective intelligence emerges from massive-agent cooperation and competition. We further analyze the emergence of various learned strategies through metrics and ablation studies, aiming to provide insights for reinforcement learning implementations in massive-agent environments.