 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDualSchool: How Reliable are LLMs for Optimization Education?
May 27, 2025

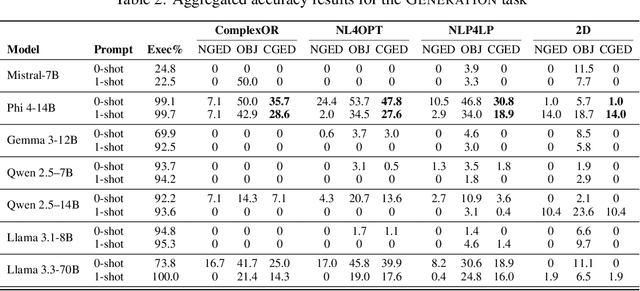

Consider the following task taught in introductory optimization courses which addresses challenges articulated by the community at the intersection of (generative) AI and OR: generate the dual of a linear program. LLMs, being trained at web-scale, have the conversion process and many instances of Primal to Dual Conversion (P2DC) at their disposal. Students may thus reasonably expect that LLMs would perform well on the P2DC task. To assess this expectation, this paper introduces DualSchool, a comprehensive framework for generating and verifying P2DC instances. The verification procedure of DualSchool uses the Canonical Graph Edit Distance, going well beyond existing evaluation methods for optimization models, which exhibit many false positives and negatives when applied to P2DC. Experiments performed by DualSchool reveal interesting findings. Although LLMs can recite the conversion procedure accurately, state-of-the-art open LLMs fail to consistently produce correct duals. This finding holds even for the smallest two-variable instances and for derivative tasks, such as correctness, verification, and error classification. The paper also discusses the implications for educators, students, and the development of large reasoning systems.
SPOT: Spatio-Temporal Pattern Mining and Optimization for Load Consolidation in Freight Transportation Networks
Apr 13, 2025



Freight consolidation has significant potential to reduce transportation costs and mitigate congestion and pollution. An effective load consolidation plan relies on carefully chosen consolidation points to ensure alignment with existing transportation management processes, such as driver scheduling, personnel planning, and terminal operations. This complexity represents a significant challenge when searching for optimal consolidation strategies. Traditional optimization-based methods provide exact solutions, but their computational complexity makes them impractical for large-scale instances and they fail to leverage historical data. Machine learning-based approaches address these issues but often ignore operational constraints, leading to infeasible consolidation plans. This work proposes SPOT, an end-to-end approach that integrates the benefits of machine learning (ML) and optimization for load consolidation. The ML component plays a key role in the planning phase by identifying the consolidation points through spatio-temporal clustering and constrained frequent itemset mining, while the optimization selects the most cost-effective feasible consolidation routes for a given operational day. Extensive experiments conducted on industrial load data demonstrate that SPOT significantly reduces travel distance and transportation costs (by about 50% on large terminals) compared to the existing industry-standard load planning strategy and a neighborhood-based heuristic. Moreover, the ML component provides valuable tactical-level insights by identifying frequently recurring consolidation opportunities that guide proactive planning. In addition, SPOT is computationally efficient and can be easily scaled to accommodate large transportation networks.
Emergent collective intelligence from massive-agent cooperation and competition
Jan 05, 2023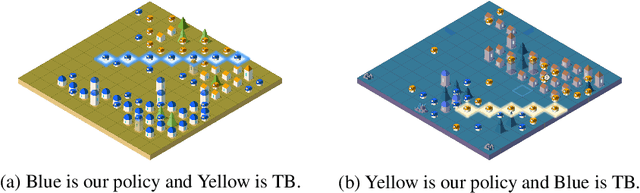



Inspired by organisms evolving through cooperation and competition between different populations on Earth, we study the emergence of artificial collective intelligence through massive-agent reinforcement learning. To this end, We propose a new massive-agent reinforcement learning environment, Lux, where dynamic and massive agents in two teams scramble for limited resources and fight off the darkness. In Lux, we build our agents through the standard reinforcement learning algorithm in curriculum learning phases and leverage centralized control via a pixel-to-pixel policy network. As agents co-evolve through self-play, we observe several stages of intelligence, from the acquisition of atomic skills to the development of group strategies. Since these learned group strategies arise from individual decisions without an explicit coordination mechanism, we claim that artificial collective intelligence emerges from massive-agent cooperation and competition. We further analyze the emergence of various learned strategies through metrics and ablation studies, aiming to provide insights for reinforcement learning implementations in massive-agent environments.