 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Rules Fall Short: Agent-Driven Discovery of Emerging Content Issues in Short Video Platforms
Jan 14, 2026Trends on short-video platforms evolve at a rapid pace, with new content issues emerging every day that fall outside the coverage of existing annotation policies. However, traditional human-driven discovery of emerging issues is too slow, which leads to delayed updates of annotation policies and poses a major challenge for effective content governance. In this work, we propose an automatic issue discovery method based on multimodal LLM agents. Our approach automatically recalls short videos containing potential new issues and applies a two-stage clustering strategy to group them, with each cluster corresponding to a newly discovered issue. The agent then generates updated annotation policies from these clusters, thereby extending coverage to these emerging issues. Our agent has been deployed in the real system. Both offline and online experiments demonstrate that this agent-based method significantly improves the effectiveness of emerging-issue discovery (with an F1 score improvement of over 20%) and enhances the performance of subsequent issue governance (reducing the view count of problematic videos by approximately 15%). More importantly, compared to manual issue discovery, it greatly reduces time costs and substantially accelerates the iteration of annotation policies.
USM: Unbiased Survey Modeling for Limiting Negative User Experiences in Recommendation Systems
Dec 14, 2024Negative feedback signals are crucial to guardrail content recommendations and improve user experience. When these signals are effectively integrated into recommendation systems, they play a vital role in preventing the promotion of harmful or undesirable content, thereby contributing to a healthier online environment. However, the challenges associated with negative signals are noteworthy. Due to the limited visibility of options for users to express negative feedback, these signals are often sparse compared to positive signals. This imbalance can lead to a skewed understanding of user preferences, resulting in recommendations that prioritize short-term engagement over long-term satisfaction. Moreover, an over-reliance on positive signals can create a filter bubble, where users are continuously exposed to content that aligns with their immediate preferences but may not be beneficial in the long run. This scenario can ultimately lead to user attrition as audiences become disillusioned with the quality of the content provided. Additionally, existing user signals frequently fail to meet specific customized requirements, such as understanding the underlying reasons for a user's likes or dislikes regarding a video. This lack of granularity hinders our ability to tailor content recommendations effectively, as we cannot identify the particular attributes of content that resonate with individual users.
Benchmarking Robustness and Generalization in Multi-Agent Systems: A Case Study on Neural MMO
Aug 30, 2023

We present the results of the second Neural MMO challenge, hosted at IJCAI 2022, which received 1600+ submissions. This competition targets robustness and generalization in multi-agent systems: participants train teams of agents to complete a multi-task objective against opponents not seen during training. The competition combines relatively complex environment design with large numbers of agents in the environment. The top submissions demonstrate strong success on this task using mostly standard reinforcement learning (RL) methods combined with domain-specific engineering. We summarize the competition design and results and suggest that, as an academic community, competitions may be a powerful approach to solving hard problems and establishing a solid benchmark for algorithms. We will open-source our benchmark including the environment wrapper, baselines, a visualization tool, and selected policies for further research.
Emergent collective intelligence from massive-agent cooperation and competition
Jan 05, 2023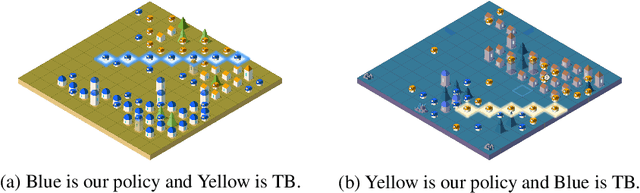



Inspired by organisms evolving through cooperation and competition between different populations on Earth, we study the emergence of artificial collective intelligence through massive-agent reinforcement learning. To this end, We propose a new massive-agent reinforcement learning environment, Lux, where dynamic and massive agents in two teams scramble for limited resources and fight off the darkness. In Lux, we build our agents through the standard reinforcement learning algorithm in curriculum learning phases and leverage centralized control via a pixel-to-pixel policy network. As agents co-evolve through self-play, we observe several stages of intelligence, from the acquisition of atomic skills to the development of group strategies. Since these learned group strategies arise from individual decisions without an explicit coordination mechanism, we claim that artificial collective intelligence emerges from massive-agent cooperation and competition. We further analyze the emergence of various learned strategies through metrics and ablation studies, aiming to provide insights for reinforcement learning implementations in massive-agent environments.
Seeking Common Ground While Reserving Differences: Multiple Anatomy Collaborative Framework for Undersampled MRI Reconstruction
Jun 16, 2022
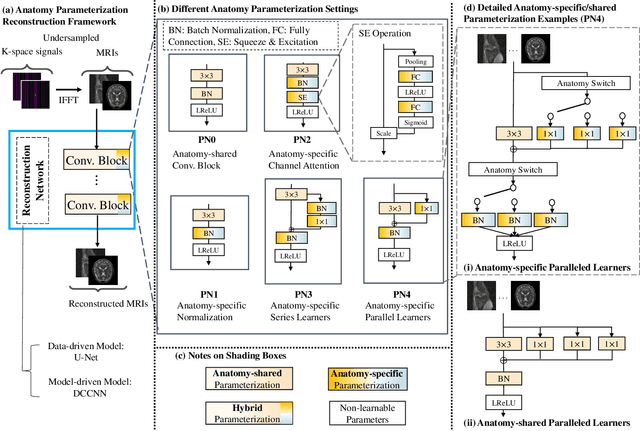
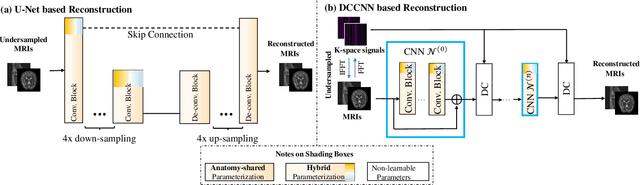
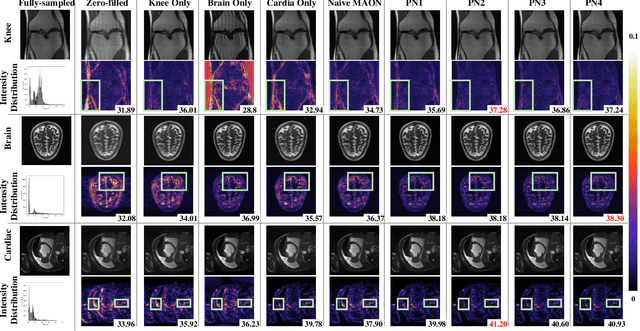
Recently, deep neural networks have greatly advanced undersampled Magnetic Resonance Image (MRI) reconstruction, wherein most studies follow the one-anatomy-one-network fashion, i.e., each expert network is trained and evaluated for a specific anatomy. Apart from inefficiency in training multiple independent models, such convention ignores the shared de-aliasing knowledge across various anatomies which can benefit each other. To explore the shared knowledge, one naive way is to combine all the data from various anatomies to train an all-round network. Unfortunately, despite the existence of the shared de-aliasing knowledge, we reveal that the exclusive knowledge across different anatomies can deteriorate specific reconstruction targets, yielding overall performance degradation. Observing this, in this study, we present a novel deep MRI reconstruction framework with both anatomy-shared and anatomy-specific parameterized learners, aiming to "seek common ground while reserving differences" across different anatomies.Particularly, the primary anatomy-shared learners are exposed to different anatomies to model flourishing shared knowledge, while the efficient anatomy-specific learners are trained with their target anatomy for exclusive knowledge. Four different implementations of anatomy-specific learners are presented and explored on the top of our framework in two MRI reconstruction networks. Comprehensive experiments on brain, knee and cardiac MRI datasets demonstrate that three of these learners are able to enhance reconstruction performance via multiple anatomy collaborative learning.