 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Rules Fall Short: Agent-Driven Discovery of Emerging Content Issues in Short Video Platforms
Jan 14, 2026Trends on short-video platforms evolve at a rapid pace, with new content issues emerging every day that fall outside the coverage of existing annotation policies. However, traditional human-driven discovery of emerging issues is too slow, which leads to delayed updates of annotation policies and poses a major challenge for effective content governance. In this work, we propose an automatic issue discovery method based on multimodal LLM agents. Our approach automatically recalls short videos containing potential new issues and applies a two-stage clustering strategy to group them, with each cluster corresponding to a newly discovered issue. The agent then generates updated annotation policies from these clusters, thereby extending coverage to these emerging issues. Our agent has been deployed in the real system. Both offline and online experiments demonstrate that this agent-based method significantly improves the effectiveness of emerging-issue discovery (with an F1 score improvement of over 20%) and enhances the performance of subsequent issue governance (reducing the view count of problematic videos by approximately 15%). More importantly, compared to manual issue discovery, it greatly reduces time costs and substantially accelerates the iteration of annotation policies.
Filter-And-Refine: A MLLM Based Cascade System for Industrial-Scale Video Content Moderation
Jul 23, 2025Effective content moderation is essential for video platforms to safeguard user experience and uphold community standards. While traditional video classification models effectively handle well-defined moderation tasks, they struggle with complicated scenarios such as implicit harmful content and contextual ambiguity. Multimodal large language models (MLLMs) offer a promising solution to these limitations with their superior cross-modal reasoning and contextual understanding. However, two key challenges hinder their industrial adoption. First, the high computational cost of MLLMs makes full-scale deployment impractical. Second, adapting generative models for discriminative classification remains an open research problem. In this paper, we first introduce an efficient method to transform a generative MLLM into a multimodal classifier using minimal discriminative training data. To enable industry-scale deployment, we then propose a router-ranking cascade system that integrates MLLMs with a lightweight router model. Offline experiments demonstrate that our MLLM-based approach improves F1 score by 66.50% over traditional classifiers while requiring only 2% of the fine-tuning data. Online evaluations show that our system increases automatic content moderation volume by 41%, while the cascading deployment reduces computational cost to only 1.5% of direct full-scale deployment.
AgentPS: Agentic Process Supervision for Multi-modal Content Quality Assurance through Multi-round QA
Dec 15, 2024



The advanced processing and reasoning capabilities of multimodal large language models (MLLMs) have driven substantial progress in vision-language (VL) understanding tasks. However, while effective for tasks governed by straightforward logic, MLLMs often encounter challenges when reasoning over complex, interdependent logic structures. To address this limitation, we introduce \textit{AgentPS}, a novel framework that integrates Agentic Process Supervision into MLLMs via multi-round question answering during fine-tuning. \textit{AgentPS} demonstrates significant performance improvements over baseline MLLMs on proprietary TikTok datasets, due to its integration of process supervision and structured sequential reasoning. Furthermore, we show that replacing human-annotated labels with LLM-generated labels retains much of the performance gain, highlighting the framework's practical scalability in industrial applications. These results position \textit{AgentPS} as a highly effective and efficient architecture for multimodal classification tasks. Its adaptability and scalability, especially when enhanced by automated annotation generation, make it a powerful tool for handling large-scale, real-world challenges.
USM: Unbiased Survey Modeling for Limiting Negative User Experiences in Recommendation Systems
Dec 14, 2024Negative feedback signals are crucial to guardrail content recommendations and improve user experience. When these signals are effectively integrated into recommendation systems, they play a vital role in preventing the promotion of harmful or undesirable content, thereby contributing to a healthier online environment. However, the challenges associated with negative signals are noteworthy. Due to the limited visibility of options for users to express negative feedback, these signals are often sparse compared to positive signals. This imbalance can lead to a skewed understanding of user preferences, resulting in recommendations that prioritize short-term engagement over long-term satisfaction. Moreover, an over-reliance on positive signals can create a filter bubble, where users are continuously exposed to content that aligns with their immediate preferences but may not be beneficial in the long run. This scenario can ultimately lead to user attrition as audiences become disillusioned with the quality of the content provided. Additionally, existing user signals frequently fail to meet specific customized requirements, such as understanding the underlying reasons for a user's likes or dislikes regarding a video. This lack of granularity hinders our ability to tailor content recommendations effectively, as we cannot identify the particular attributes of content that resonate with individual users.
COEF-VQ: Cost-Efficient Video Quality Understanding through a Cascaded Multimodal LLM Framework
Dec 11, 2024



Recently, with the emergence of recent Multimodal Large Language Model (MLLM) technology, it has become possible to exploit its video understanding capability on different classification tasks. In practice, we face the difficulty of huge requirements for GPU resource if we need to deploy MLLMs online. In this paper, we propose COEF-VQ, a novel cascaded MLLM framework for better video quality understanding on TikTok. To this end, we first propose a MLLM fusing all visual, textual and audio signals, and then develop a cascade framework with a lightweight model as pre-filtering stage and MLLM as fine-consideration stage, significantly reducing the need for GPU resource, while retaining the performance demonstrated solely by MLLM. To demonstrate the effectiveness of COEF-VQ, we deployed this new framework onto the video management platform (VMP) at TikTok, and performed a series of detailed experiments on two in-house tasks related to video quality understanding. We show that COEF-VQ leads to substantial performance gains with limit resource consumption in these two tasks.
Efficient Super Resolution Using Binarized Neural Network
Dec 16, 2018



Deep convolutional neural networks (DCNNs) have recently demonstrated high-quality results in single-image super-resolution (SR). DCNNs often suffer from over-parametrization and large amounts of redundancy, which results in inefficient inference and high memory usage, preventing massive applications on mobile devices. As a way to significantly reduce model size and computation time, binarized neural network has only been shown to excel on semantic-level tasks such as image classification and recognition. However, little effort of network quantization has been spent on image enhancement tasks like SR, as network quantization is usually assumed to sacrifice pixel-level accuracy. In this work, we explore an network-binarization approach for SR tasks without sacrificing much reconstruction accuracy. To achieve this, we binarize the convolutional filters in only residual blocks, and adopt a learnable weight for each binary filter. We evaluate this idea on several state-of-the-art DCNN-based architectures, and show that binarized SR networks achieve comparable qualitative and quantitative results as their real-weight counterparts. Moreover, the proposed binarized strategy could help reduce model size by 80% when applying on SRResNet, and could potentially speed up inference by 5 times.
Transferable Natural Language Interface to Structured Queries aided by Adversarial Generation
Dec 07, 2018



A natural language interface (NLI) to structured query is intriguing due to its wide industrial applications and high economical values. In this work, we tackle the problem of domain adaptation for NLI with limited data on target domain. Two important approaches are considered: (a) effective general-knowledge-learning on source domain semantic parsing, and (b) data augmentation on target domain. We present a Structured Query Inference Network (SQIN) to enhance learning for domain adaptation, by separating schema information from NL and decoding SQL in a more structural-aware manner; we also propose a GAN-based augmentation technique (AugmentGAN) to mitigate the issue of lacking target domain data. We report solid results on GeoQuery, Overnight, and WikiSQL to demonstrate state-of-the-art performances for both in-domain and domain-transfer tasks.
A Transfer-Learnable Natural Language Interface for Databases
Sep 07, 2018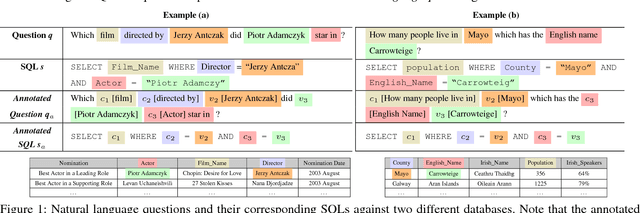
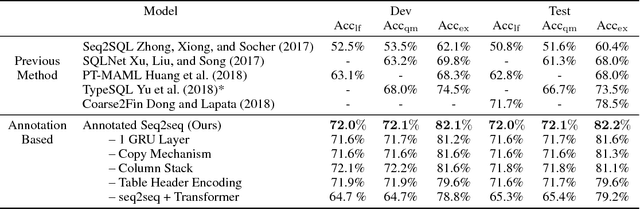
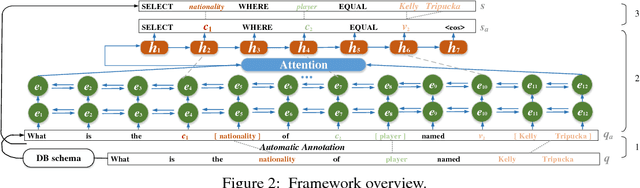
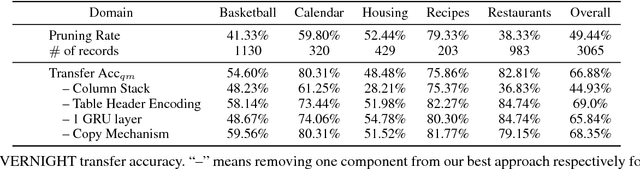
Relational database management systems (RDBMSs) are powerful because they are able to optimize and answer queries against any relational database. A natural language interface (NLI) for a database, on the other hand, is tailored to support that specific database. In this work, we introduce a general purpose transfer-learnable NLI with the goal of learning one model that can be used as NLI for any relational database. We adopt the data management principle of separating data and its schema, but with the additional support for the idiosyncrasy and complexity of natural languages. Specifically, we introduce an automatic annotation mechanism that separates the schema and the data, where the schema also covers knowledge about natural language. Furthermore, we propose a customized sequence model that translates annotated natural language queries to SQL statements. We show in experiments that our approach outperforms previous NLI methods on the WikiSQL dataset and the model we learned can be applied to another benchmark dataset OVERNIGHT without retraining.