 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInteractive Portrait Harmonization
Mar 15, 2022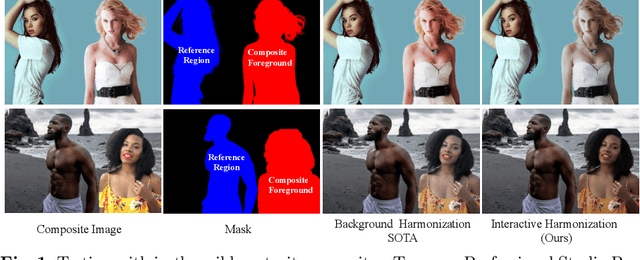
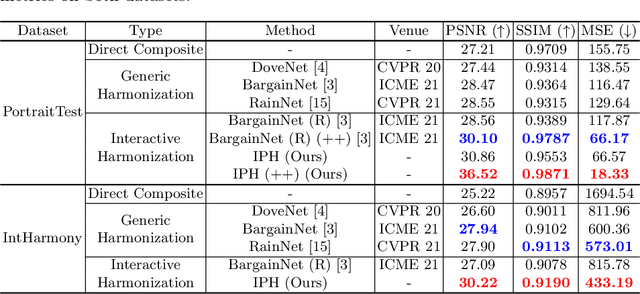

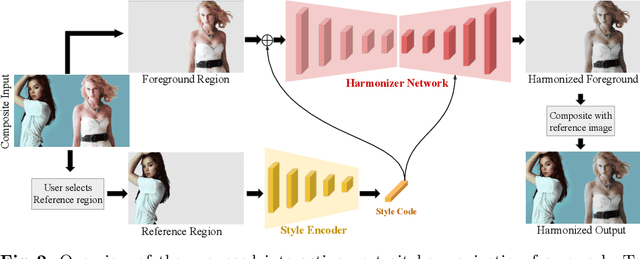
Current image harmonization methods consider the entire background as the guidance for harmonization. However, this may limit the capability for user to choose any specific object/person in the background to guide the harmonization. To enable flexible interaction between user and harmonization, we introduce interactive harmonization, a new setting where the harmonization is performed with respect to a selected \emph{region} in the reference image instead of the entire background. A new flexible framework that allows users to pick certain regions of the background image and use it to guide the harmonization is proposed. Inspired by professional portrait harmonization users, we also introduce a new luminance matching loss to optimally match the color/luminance conditions between the composite foreground and select reference region. This framework provides more control to the image harmonization pipeline achieving visually pleasing portrait edits. Furthermore, we also introduce a new dataset carefully curated for validating portrait harmonization. Extensive experiments on both synthetic and real-world datasets show that the proposed approach is efficient and robust compared to previous harmonization baselines, especially for portraits. Project Webpage at \href{https://jeya-maria-jose.github.io/IPH-web/}{https://jeya-maria-jose.github.io/IPH-web/}
Efficient Super Resolution Using Binarized Neural Network
Dec 16, 2018



Deep convolutional neural networks (DCNNs) have recently demonstrated high-quality results in single-image super-resolution (SR). DCNNs often suffer from over-parametrization and large amounts of redundancy, which results in inefficient inference and high memory usage, preventing massive applications on mobile devices. As a way to significantly reduce model size and computation time, binarized neural network has only been shown to excel on semantic-level tasks such as image classification and recognition. However, little effort of network quantization has been spent on image enhancement tasks like SR, as network quantization is usually assumed to sacrifice pixel-level accuracy. In this work, we explore an network-binarization approach for SR tasks without sacrificing much reconstruction accuracy. To achieve this, we binarize the convolutional filters in only residual blocks, and adopt a learnable weight for each binary filter. We evaluate this idea on several state-of-the-art DCNN-based architectures, and show that binarized SR networks achieve comparable qualitative and quantitative results as their real-weight counterparts. Moreover, the proposed binarized strategy could help reduce model size by 80% when applying on SRResNet, and could potentially speed up inference by 5 times.
Multi-Scale Video Frame-Synthesis Network with Transitive Consistency Loss
Mar 19, 2018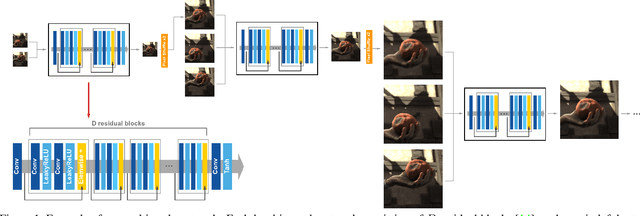
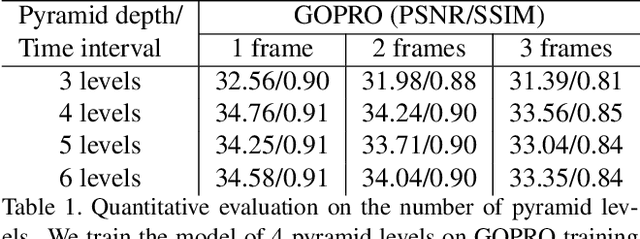


Traditional approaches to interpolate/extrapolate frames in a video sequence require accurate pixel correspondences between images, e.g., using optical flow. Their results stem on the accuracy of optical flow estimation, and could generate heavy artifacts when flow estimation failed. Recently methods using auto-encoder has shown impressive progress, however they are usually trained for specific interpolation/extrapolation settings and lack of flexibility and In order to reduce these limitations, we propose a unified network to parameterize the interest frame position and therefore infer interpolate/extrapolate frames within the same framework. To achieve this, we introduce a transitive consistency loss to better regularize the network. We adopt a multi-scale structure for the network so that the parameters can be shared across multi-layers. Our approach avoids expensive global optimization of optical flow methods, and is efficient and flexible for video interpolation/extrapolation applications. Experimental results have shown that our method performs favorably against state-of-the-art methods.