 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Scale Video Frame-Synthesis Network with Transitive Consistency Loss
Paper and Code
Mar 19, 2018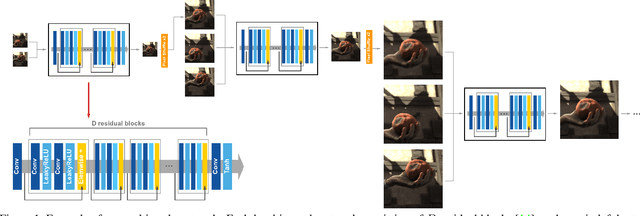


Traditional approaches to interpolate/extrapolate frames in a video sequence require accurate pixel correspondences between images, e.g., using optical flow. Their results stem on the accuracy of optical flow estimation, and could generate heavy artifacts when flow estimation failed. Recently methods using auto-encoder has shown impressive progress, however they are usually trained for specific interpolation/extrapolation settings and lack of flexibility and In order to reduce these limitations, we propose a unified network to parameterize the interest frame position and therefore infer interpolate/extrapolate frames within the same framework. To achieve this, we introduce a transitive consistency loss to better regularize the network. We adopt a multi-scale structure for the network so that the parameters can be shared across multi-layers. Our approach avoids expensive global optimization of optical flow methods, and is efficient and flexible for video interpolation/extrapolation applications. Experimental results have shown that our method performs favorably against state-of-the-art methods.