 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge4D reconstruction of alumina laser melt pools at 25 kHz via operando X-ray multi-projection imaging
Mar 15, 2026Advancing additive manufacturing, e.g., laser powder-bed fusion (LPBF), requires resolving rapid processes such as melt-pool dynamics and keyhole evolution in 4D (3D + time). Operando X-ray tomography is a state-of-the-art approach for 4D characterization, but its temporal resolution is fundamentally constrained by the sample rotation speed, limiting achievable 4D imaging rates and preventing the resolution of these fast phenomena. Here we present rotation-enabled X-ray Multi-Projection Imaging (rotation-XMPI), which captures three angularly resolved projections per time step and thereby decouples temporal resolution from the sample rotation speed. Combined with a self-supervised deep-learning reconstruction framework for multi-angle inputs, rotation-XMPI enables high-fidelity 4D imaging at unprecedented speed. We demonstrate the approach in an operando alumina laser-remelting experiment at MAX IV using three beamlets combined with 25 Hz sample rotation. Rotation-XMPI resolves melt-pool morphology and keyhole evolution; in contrast, conventional and limited-angle tomography remain rotation-limited, and motion blur prevents resolving these dynamics. Overall, rotation-XMPI delivers a 250-fold increase relative to state-of-the-art melt-pool imaging, effectively achieving 25,000 reconstructed volumes per second. This method establishes a practical route to scalable ultrafast 4D imaging for additive manufacturing and other materials processes.
Guided by the Plan: Enhancing Faithful Autoregressive Text-to-Audio Generation with Guided Decoding
Jan 18, 2026Autoregressive (AR) models excel at generating temporally coherent audio by producing tokens sequentially, yet they often falter in faithfully following complex textual prompts, especially those describing complex sound events. We uncover a surprising capability in AR audio generators: their early prefix tokens implicitly encode global semantic attributes of the final output, such as event count and sound-object category, revealing a form of implicit planning. Building on this insight, we propose Plan-Critic, a lightweight auxiliary model trained with a Generalized Advantage Estimation (GAE)-inspired objective to predict final instruction-following quality from partial generations. At inference time, Plan-Critic enables guided exploration: it evaluates candidate prefixes early, prunes low-fidelity trajectories, and reallocates computation to high-potential planning seeds. Our Plan-Critic-guided sampling achieves up to a 10-point improvement in CLAP score over the AR baseline-establishing a new state of the art in AR text-to-audio generation-while maintaining computational parity with standard best-of-N decoding. This work bridges the gap between causal generation and global semantic alignment, demonstrating that even strictly autoregressive models can plan ahead.
Exploring Scale Shift in Crowd Localization under the Context of Domain Generalization
Oct 22, 2025Crowd localization plays a crucial role in visual scene understanding towards predicting each pedestrian location in a crowd, thus being applicable to various downstream tasks. However, existing approaches suffer from significant performance degradation due to discrepancies in head scale distributions (scale shift) between training and testing data, a challenge known as domain generalization (DG). This paper aims to comprehend the nature of scale shift within the context of domain generalization for crowd localization models. To this end, we address four critical questions: (i) How does scale shift influence crowd localization in a DG scenario? (ii) How can we quantify this influence? (iii) What causes this influence? (iv) How to mitigate the influence? Initially, we conduct a systematic examination of how crowd localization performance varies with different levels of scale shift. Then, we establish a benchmark, ScaleBench, and reproduce 20 advanced DG algorithms to quantify the influence. Through extensive experiments, we demonstrate the limitations of existing algorithms and underscore the importance and complexity of scale shift, a topic that remains insufficiently explored. To deepen our understanding, we provide a rigorous theoretical analysis on scale shift. Building on these insights, we further propose an effective algorithm called Causal Feature Decomposition and Anisotropic Processing (Catto) to mitigate the influence of scale shift in DG settings. Later, we also provide extensive analytical experiments, revealing four significant insights for future research. Our results emphasize the importance of this novel and applicable research direction, which we term Scale Shift Domain Generalization.
Language Model Based Text-to-Audio Generation: Anti-Causally Aligned Collaborative Residual Transformers
Oct 06, 2025While language models (LMs) paired with residual vector quantization (RVQ) tokenizers have shown promise in text-to-audio (T2A) generation, they still lag behind diffusion-based models by a non-trivial margin. We identify a critical dilemma underpinning this gap: incorporating more RVQ layers improves audio reconstruction fidelity but exceeds the generation capacity of conventional LMs. To address this, we first analyze RVQ dynamics and uncover two key limitations: 1) orthogonality of features across RVQ layers hinders effective LMs training, and 2) descending semantic richness in tokens from deeper RVQ layers exacerbates exposure bias during autoregressive decoding. Based on these insights, we propose Siren, a novel LM-based framework that employs multiple isolated transformers with causal conditioning and anti-causal alignment via reinforcement learning. Extensive experiments demonstrate that Siren outperforms both existing LM-based and diffusion-based T2A systems, achieving state-of-the-art results. By bridging the representational strengths of LMs with the fidelity demands of audio synthesis, our approach repositions LMs as competitive contenders against diffusion models in T2A tasks. Moreover, by aligning audio representations with linguistic structures, Siren facilitates a promising pathway toward unified multi-modal generation frameworks.
Physics-informed 4D X-ray image reconstruction from ultra-sparse spatiotemporal data
Apr 04, 2025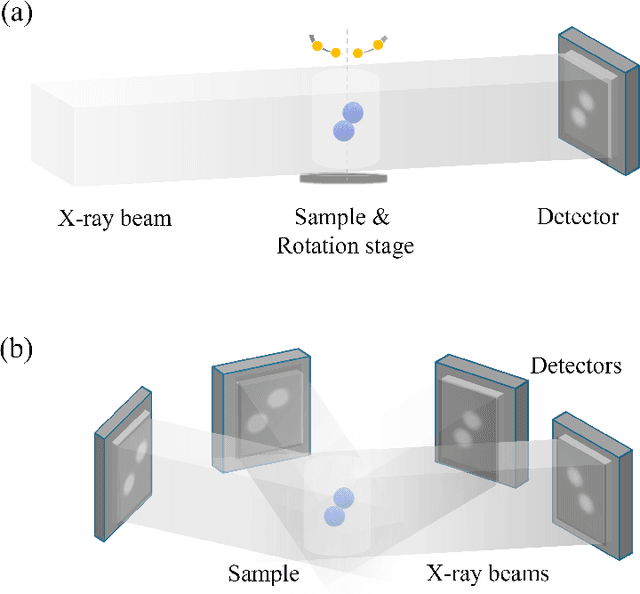

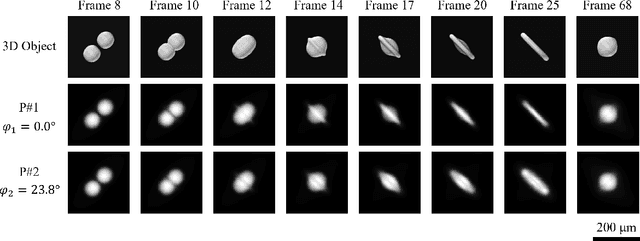
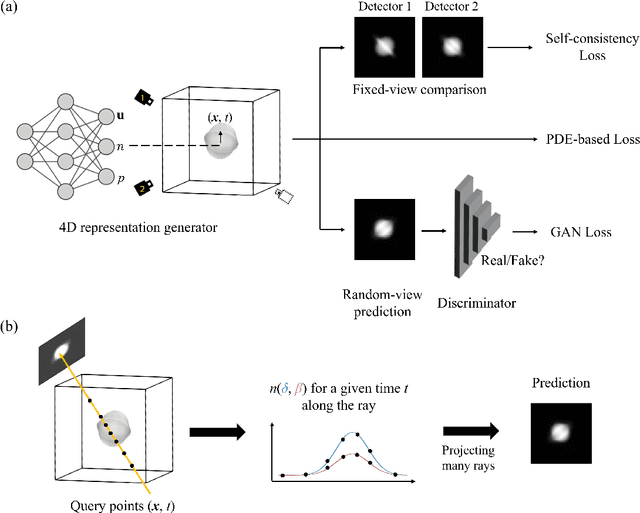
The unprecedented X-ray flux density provided by modern X-ray sources offers new spatiotemporal possibilities for X-ray imaging of fast dynamic processes. Approaches to exploit such possibilities often result in either i) a limited number of projections or spatial information due to limited scanning speed, as in time-resolved tomography, or ii) a limited number of time points, as in stroboscopic imaging, making the reconstruction problem ill-posed and unlikely to be solved by classical reconstruction approaches. 4D reconstruction from such data requires sample priors, which can be included via deep learning (DL). State-of-the-art 4D reconstruction methods for X-ray imaging combine the power of AI and the physics of X-ray propagation to tackle the challenge of sparse views. However, most approaches do not constrain the physics of the studied process, i.e., a full physical model. Here we present 4D physics-informed optimized neural implicit X-ray imaging (4D-PIONIX), a novel physics-informed 4D X-ray image reconstruction method combining the full physical model and a state-of-the-art DL-based reconstruction method for 4D X-ray imaging from sparse views. We demonstrate and evaluate the potential of our approach by retrieving 4D information from ultra-sparse spatiotemporal acquisitions of simulated binary droplet collisions, a relevant fluid dynamic process. We envision that this work will open new spatiotemporal possibilities for various 4D X-ray imaging modalities, such as time-resolved X-ray tomography and more novel sparse acquisition approaches like X-ray multi-projection imaging, which will pave the way for investigations of various rapid 4D dynamics, such as fluid dynamics and composite testing.
When 'YES' Meets 'BUT': Can Large Models Comprehend Contradictory Humor Through Comparative Reasoning?
Mar 29, 2025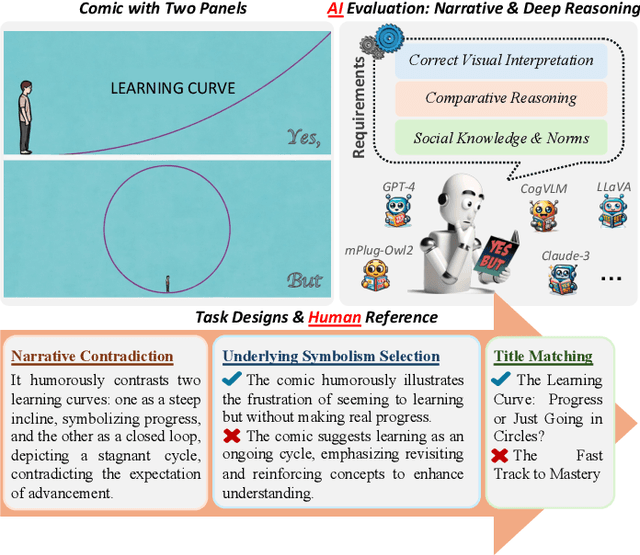



Understanding humor-particularly when it involves complex, contradictory narratives that require comparative reasoning-remains a significant challenge for large vision-language models (VLMs). This limitation hinders AI's ability to engage in human-like reasoning and cultural expression. In this paper, we investigate this challenge through an in-depth analysis of comics that juxtapose panels to create humor through contradictions. We introduce the YesBut (V2), a novel benchmark with 1,262 comic images from diverse multilingual and multicultural contexts, featuring comprehensive annotations that capture various aspects of narrative understanding. Using this benchmark, we systematically evaluate a wide range of VLMs through four complementary tasks spanning from surface content comprehension to deep narrative reasoning, with particular emphasis on comparative reasoning between contradictory elements. Our extensive experiments reveal that even the most advanced models significantly underperform compared to humans, with common failures in visual perception, key element identification, comparative analysis and hallucinations. We further investigate text-based training strategies and social knowledge augmentation methods to enhance model performance. Our findings not only highlight critical weaknesses in VLMs' understanding of cultural and creative expressions but also provide pathways toward developing context-aware models capable of deeper narrative understanding though comparative reasoning.
Synchronized Video-to-Audio Generation via Mel Quantization-Continuum Decomposition
Mar 10, 2025Video-to-audio generation is essential for synthesizing realistic audio tracks that synchronize effectively with silent videos. Following the perspective of extracting essential signals from videos that can precisely control the mature text-to-audio generative diffusion models, this paper presents how to balance the representation of mel-spectrograms in terms of completeness and complexity through a new approach called Mel Quantization-Continuum Decomposition (Mel-QCD). We decompose the mel-spectrogram into three distinct types of signals, employing quantization or continuity to them, we can effectively predict them from video by a devised video-to-all (V2X) predictor. Then, the predicted signals are recomposed and fed into a ControlNet, along with a textual inversion design, to control the audio generation process. Our proposed Mel-QCD method demonstrates state-of-the-art performance across eight metrics, evaluating dimensions such as quality, synchronization, and semantic consistency. Our codes and demos will be released at \href{Website}{https://wjc2830.github.io/MelQCD/}.
Language-Augmented Symbolic Planner for Open-World Task Planning
Jul 13, 2024



Enabling robotic agents to perform complex long-horizon tasks has been a long-standing goal in robotics and artificial intelligence (AI). Despite the potential shown by large language models (LLMs), their planning capabilities remain limited to short-horizon tasks and they are unable to replace the symbolic planning approach. Symbolic planners, on the other hand, may encounter execution errors due to their common assumption of complete domain knowledge which is hard to manually prepare for an open-world setting. In this paper, we introduce a Language-Augmented Symbolic Planner (LASP) that integrates pre-trained LLMs to enable conventional symbolic planners to operate in an open-world environment where only incomplete knowledge of action preconditions, objects, and properties is initially available. In case of execution errors, LASP can utilize the LLM to diagnose the cause of the error based on the observation and interact with the environment to incrementally build up its knowledge base necessary for accomplishing the given tasks. Experiments demonstrate that LASP is proficient in solving planning problems in the open-world setting, performing well even in situations where there are multiple gaps in the knowledge.
VIVA: A Benchmark for Vision-Grounded Decision-Making with Human Values
Jul 03, 2024



This paper introduces VIVA, a benchmark for VIsion-grounded decision-making driven by human VAlues. While most large vision-language models (VLMs) focus on physical-level skills, our work is the first to examine their multimodal capabilities in leveraging human values to make decisions under a vision-depicted situation. VIVA contains 1,062 images depicting diverse real-world situations and the manually annotated decisions grounded in them. Given an image there, the model should select the most appropriate action to address the situation and provide the relevant human values and reason underlying the decision. Extensive experiments based on VIVA show the limitation of VLMs in using human values to make multimodal decisions. Further analyses indicate the potential benefits of exploiting action consequences and predicted human values.
Unlocking Varied Perspectives: A Persona-Based Multi-Agent Framework with Debate-Driven Text Planning for Argument Generation
Jun 28, 2024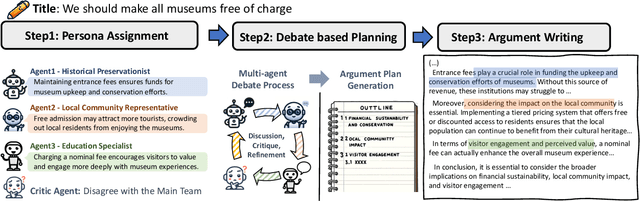
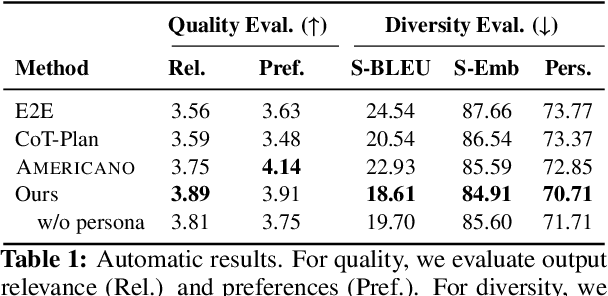
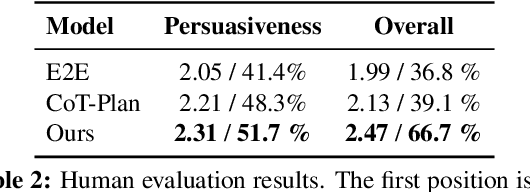
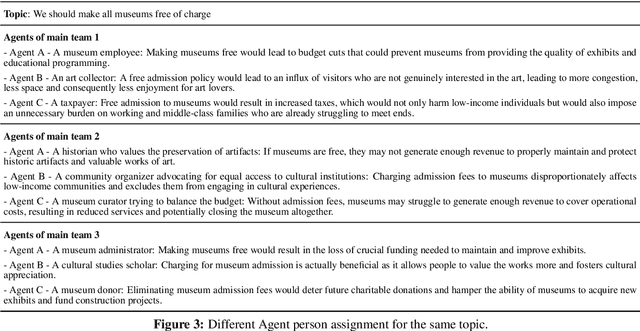
Writing persuasive arguments is a challenging task for both humans and machines. It entails incorporating high-level beliefs from various perspectives on the topic, along with deliberate reasoning and planning to construct a coherent narrative. Current language models often generate surface tokens autoregressively, lacking explicit integration of these underlying controls, resulting in limited output diversity and coherence. In this work, we propose a persona-based multi-agent framework for argument writing. Inspired by the human debate, we first assign each agent a persona representing its high-level beliefs from a unique perspective, and then design an agent interaction process so that the agents can collaboratively debate and discuss the idea to form an overall plan for argument writing. Such debate process enables fluid and nonlinear development of ideas. We evaluate our framework on argumentative essay writing. The results show that our framework can generate more diverse and persuasive arguments through both automatic and human evaluations.