 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided by the Plan: Enhancing Faithful Autoregressive Text-to-Audio Generation with Guided Decoding
Jan 18, 2026Autoregressive (AR) models excel at generating temporally coherent audio by producing tokens sequentially, yet they often falter in faithfully following complex textual prompts, especially those describing complex sound events. We uncover a surprising capability in AR audio generators: their early prefix tokens implicitly encode global semantic attributes of the final output, such as event count and sound-object category, revealing a form of implicit planning. Building on this insight, we propose Plan-Critic, a lightweight auxiliary model trained with a Generalized Advantage Estimation (GAE)-inspired objective to predict final instruction-following quality from partial generations. At inference time, Plan-Critic enables guided exploration: it evaluates candidate prefixes early, prunes low-fidelity trajectories, and reallocates computation to high-potential planning seeds. Our Plan-Critic-guided sampling achieves up to a 10-point improvement in CLAP score over the AR baseline-establishing a new state of the art in AR text-to-audio generation-while maintaining computational parity with standard best-of-N decoding. This work bridges the gap between causal generation and global semantic alignment, demonstrating that even strictly autoregressive models can plan ahead.
Think Before You Move: Latent Motion Reasoning for Text-to-Motion Generation
Dec 30, 2025Current state-of-the-art paradigms predominantly treat Text-to-Motion (T2M) generation as a direct translation problem, mapping symbolic language directly to continuous poses. While effective for simple actions, this System 1 approach faces a fundamental theoretical bottleneck we identify as the Semantic-Kinematic Impedance Mismatch: the inherent difficulty of grounding semantically dense, discrete linguistic intent into kinematically dense, high-frequency motion data in a single shot. In this paper, we argue that the solution lies in an architectural shift towards Latent System 2 Reasoning. Drawing inspiration from Hierarchical Motor Control in cognitive science, we propose Latent Motion Reasoning (LMR) that reformulates generation as a two-stage Think-then-Act decision process. Central to LMR is a novel Dual-Granularity Tokenizer that disentangles motion into two distinct manifolds: a compressed, semantically rich Reasoning Latent for planning global topology, and a high-frequency Execution Latent for preserving physical fidelity. By forcing the model to autoregressively reason (plan the coarse trajectory) before it moves (instantiates the frames), we effectively bridge the ineffability gap between language and physics. We demonstrate LMR's versatility by implementing it for two representative baselines: T2M-GPT (discrete) and MotionStreamer (continuous). Extensive experiments show that LMR yields non-trivial improvements in both semantic alignment and physical plausibility, validating that the optimal substrate for motion planning is not natural language, but a learned, motion-aligned concept space. Codes and demos can be found in \hyperlink{https://chenhaoqcdyq.github.io/LMR/}{https://chenhaoqcdyq.github.io/LMR/}
An Anatomy of Vision-Language-Action Models: From Modules to Milestones and Challenges
Dec 19, 2025Vision-Language-Action (VLA) models are driving a revolution in robotics, enabling machines to understand instructions and interact with the physical world. This field is exploding with new models and datasets, making it both exciting and challenging to keep pace with. This survey offers a clear and structured guide to the VLA landscape. We design it to follow the natural learning path of a researcher: we start with the basic Modules of any VLA model, trace the history through key Milestones, and then dive deep into the core Challenges that define recent research frontier. Our main contribution is a detailed breakdown of the five biggest challenges in: (1) Representation, (2) Execution, (3) Generalization, (4) Safety, and (5) Dataset and Evaluation. This structure mirrors the developmental roadmap of a generalist agent: establishing the fundamental perception-action loop, scaling capabilities across diverse embodiments and environments, and finally ensuring trustworthy deployment-all supported by the essential data infrastructure. For each of them, we review existing approaches and highlight future opportunities. We position this paper as both a foundational guide for newcomers and a strategic roadmap for experienced researchers, with the dual aim of accelerating learning and inspiring new ideas in embodied intelligence. A live version of this survey, with continuous updates, is maintained on our \href{https://suyuz1.github.io/VLA-Survey-Anatomy/}{project page}.
Exploring Scale Shift in Crowd Localization under the Context of Domain Generalization
Oct 22, 2025Crowd localization plays a crucial role in visual scene understanding towards predicting each pedestrian location in a crowd, thus being applicable to various downstream tasks. However, existing approaches suffer from significant performance degradation due to discrepancies in head scale distributions (scale shift) between training and testing data, a challenge known as domain generalization (DG). This paper aims to comprehend the nature of scale shift within the context of domain generalization for crowd localization models. To this end, we address four critical questions: (i) How does scale shift influence crowd localization in a DG scenario? (ii) How can we quantify this influence? (iii) What causes this influence? (iv) How to mitigate the influence? Initially, we conduct a systematic examination of how crowd localization performance varies with different levels of scale shift. Then, we establish a benchmark, ScaleBench, and reproduce 20 advanced DG algorithms to quantify the influence. Through extensive experiments, we demonstrate the limitations of existing algorithms and underscore the importance and complexity of scale shift, a topic that remains insufficiently explored. To deepen our understanding, we provide a rigorous theoretical analysis on scale shift. Building on these insights, we further propose an effective algorithm called Causal Feature Decomposition and Anisotropic Processing (Catto) to mitigate the influence of scale shift in DG settings. Later, we also provide extensive analytical experiments, revealing four significant insights for future research. Our results emphasize the importance of this novel and applicable research direction, which we term Scale Shift Domain Generalization.
Language Model Based Text-to-Audio Generation: Anti-Causally Aligned Collaborative Residual Transformers
Oct 06, 2025While language models (LMs) paired with residual vector quantization (RVQ) tokenizers have shown promise in text-to-audio (T2A) generation, they still lag behind diffusion-based models by a non-trivial margin. We identify a critical dilemma underpinning this gap: incorporating more RVQ layers improves audio reconstruction fidelity but exceeds the generation capacity of conventional LMs. To address this, we first analyze RVQ dynamics and uncover two key limitations: 1) orthogonality of features across RVQ layers hinders effective LMs training, and 2) descending semantic richness in tokens from deeper RVQ layers exacerbates exposure bias during autoregressive decoding. Based on these insights, we propose Siren, a novel LM-based framework that employs multiple isolated transformers with causal conditioning and anti-causal alignment via reinforcement learning. Extensive experiments demonstrate that Siren outperforms both existing LM-based and diffusion-based T2A systems, achieving state-of-the-art results. By bridging the representational strengths of LMs with the fidelity demands of audio synthesis, our approach repositions LMs as competitive contenders against diffusion models in T2A tasks. Moreover, by aligning audio representations with linguistic structures, Siren facilitates a promising pathway toward unified multi-modal generation frameworks.
Towards Robust Learning to Optimize with Theoretical Guarantees
Jun 17, 2025Learning to optimize (L2O) is an emerging technique to solve mathematical optimization problems with learning-based methods. Although with great success in many real-world scenarios such as wireless communications, computer networks, and electronic design, existing L2O works lack theoretical demonstration of their performance and robustness in out-of-distribution (OOD) scenarios. We address this gap by providing comprehensive proofs. First, we prove a sufficient condition for a robust L2O model with homogeneous convergence rates over all In-Distribution (InD) instances. We assume an L2O model achieves robustness for an InD scenario. Based on our proposed methodology of aligning OOD problems to InD problems, we also demonstrate that the L2O model's convergence rate in OOD scenarios will deteriorate by an equation of the L2O model's input features. Moreover, we propose an L2O model with a concise gradient-only feature construction and a novel gradient-based history modeling method. Numerical simulation demonstrates that our proposed model outperforms the state-of-the-art baseline in both InD and OOD scenarios and achieves up to 10 $\times$ convergence speedup. The code of our method can be found from https://github.com/NetX-lab/GoMathL2O-Official.
* Published in CVPR 2024, 55 pages, 17 figures, this version fixed some typo
Adaptive Federated LoRA in Heterogeneous Wireless Networks with Independent Sampling
May 29, 2025Federated LoRA has emerged as a promising technique for efficiently fine-tuning large language models (LLMs) on distributed devices by reducing the number of trainable parameters. However, existing approaches often inadequately overlook the theoretical and practical implications of system and data heterogeneity, thereby failing to optimize the overall training efficiency, particularly in terms of wall-clock time. In this paper, we propose an adaptive federated LoRA strategy with independent client sampling to minimize the convergence wall-clock time of federated fine-tuning under both computation and communication heterogeneity. We first derive a new convergence bound for federated LoRA with arbitrary and independent client sampling, notably without requiring the stringent bounded gradient assumption. Then, we introduce an adaptive bandwidth allocation scheme that accounts for heterogeneous client resources and system bandwidth constraints. Based on the derived theory, we formulate and solve a non-convex optimization problem to jointly determine the LoRA sketching ratios and sampling probabilities, aiming to minimize wall-clock convergence time. An efficient and low-complexity algorithm is developed to approximate the solution. Finally, extensive experiments demonstrate that our approach significantly reduces wall-clock training time compared to state-of-the-art methods across various models and datasets.
Synchronized Video-to-Audio Generation via Mel Quantization-Continuum Decomposition
Mar 10, 2025Video-to-audio generation is essential for synthesizing realistic audio tracks that synchronize effectively with silent videos. Following the perspective of extracting essential signals from videos that can precisely control the mature text-to-audio generative diffusion models, this paper presents how to balance the representation of mel-spectrograms in terms of completeness and complexity through a new approach called Mel Quantization-Continuum Decomposition (Mel-QCD). We decompose the mel-spectrogram into three distinct types of signals, employing quantization or continuity to them, we can effectively predict them from video by a devised video-to-all (V2X) predictor. Then, the predicted signals are recomposed and fed into a ControlNet, along with a textual inversion design, to control the audio generation process. Our proposed Mel-QCD method demonstrates state-of-the-art performance across eight metrics, evaluating dimensions such as quality, synchronization, and semantic consistency. Our codes and demos will be released at \href{Website}{https://wjc2830.github.io/MelQCD/}.
ReFocus: Reinforcing Mid-Frequency and Key-Frequency Modeling for Multivariate Time Series Forecasting
Feb 24, 2025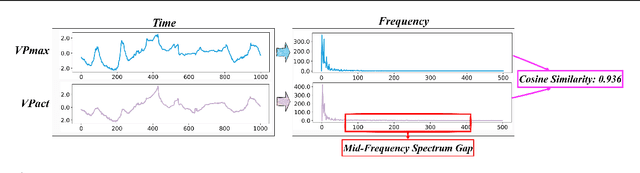


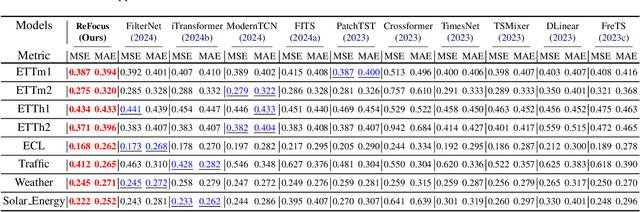
Recent advancements have progressively incorporated frequency-based techniques into deep learning models, leading to notable improvements in accuracy and efficiency for time series analysis tasks. However, the Mid-Frequency Spectrum Gap in the real-world time series, where the energy is concentrated at the low-frequency region while the middle-frequency band is negligible, hinders the ability of existing deep learning models to extract the crucial frequency information. Additionally, the shared Key-Frequency in multivariate time series, where different time series share indistinguishable frequency patterns, is rarely exploited by existing literature. This work introduces a novel module, Adaptive Mid-Frequency Energy Optimizer, based on convolution and residual learning, to emphasize the significance of mid-frequency bands. We also propose an Energy-based Key-Frequency Picking Block to capture shared Key-Frequency, which achieves superior inter-series modeling performance with fewer parameters. A novel Key-Frequency Enhanced Training strategy is employed to further enhance Key-Frequency modeling, where spectral information from other channels is randomly introduced into each channel. Our approach advanced multivariate time series forecasting on the challenging Traffic, ECL, and Solar benchmarks, reducing MSE by 4%, 6%, and 5% compared to the previous SOTA iTransformer. Code is available at this GitHub Repository: https://github.com/Levi-Ackman/ReFocus.
Doubly-Bounded Queue for Constrained Online Learning: Keeping Pace with Dynamics of Both Loss and Constraint
Dec 14, 2024



We consider online convex optimization with time-varying constraints and conduct performance analysis using two stringent metrics: dynamic regret with respect to the online solution benchmark, and hard constraint violation that does not allow any compensated violation over time. We propose an efficient algorithm called Constrained Online Learning with Doubly-bounded Queue (COLDQ), which introduces a novel virtual queue that is both lower and upper bounded, allowing tight control of the constraint violation without the need for the Slater condition. We prove via a new Lyapunov drift analysis that COLDQ achieves $O(T^\frac{1+V_x}{2})$ dynamic regret and $O(T^{V_g})$ hard constraint violation, where $V_x$ and $V_g$ capture the dynamics of the loss and constraint functions. For the first time, the two bounds smoothly approach to the best-known $O(T^\frac{1}{2})$ regret and $O(1)$ violation, as the dynamics of the losses and constraints diminish. For strongly convex loss functions, COLDQ matches the best-known $O(\log{T})$ static regret while maintaining the $O(T^{V_g})$ hard constraint violation. We further introduce an expert-tracking variation of COLDQ, which achieves the same performance bounds without any prior knowledge of the system dynamics. Simulation results demonstrate that COLDQ outperforms the state-of-the-art approaches.