 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLanguage Model Based Text-to-Audio Generation: Anti-Causally Aligned Collaborative Residual Transformers
Oct 06, 2025While language models (LMs) paired with residual vector quantization (RVQ) tokenizers have shown promise in text-to-audio (T2A) generation, they still lag behind diffusion-based models by a non-trivial margin. We identify a critical dilemma underpinning this gap: incorporating more RVQ layers improves audio reconstruction fidelity but exceeds the generation capacity of conventional LMs. To address this, we first analyze RVQ dynamics and uncover two key limitations: 1) orthogonality of features across RVQ layers hinders effective LMs training, and 2) descending semantic richness in tokens from deeper RVQ layers exacerbates exposure bias during autoregressive decoding. Based on these insights, we propose Siren, a novel LM-based framework that employs multiple isolated transformers with causal conditioning and anti-causal alignment via reinforcement learning. Extensive experiments demonstrate that Siren outperforms both existing LM-based and diffusion-based T2A systems, achieving state-of-the-art results. By bridging the representational strengths of LMs with the fidelity demands of audio synthesis, our approach repositions LMs as competitive contenders against diffusion models in T2A tasks. Moreover, by aligning audio representations with linguistic structures, Siren facilitates a promising pathway toward unified multi-modal generation frameworks.
ReFocus: Reinforcing Mid-Frequency and Key-Frequency Modeling for Multivariate Time Series Forecasting
Feb 24, 2025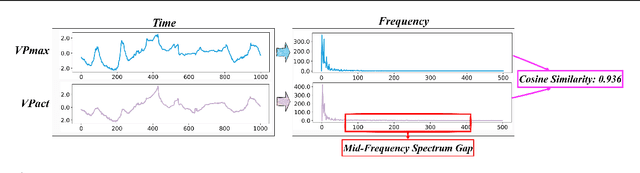


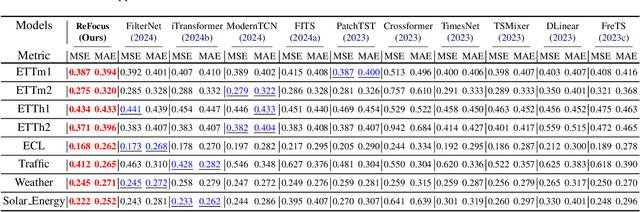
Recent advancements have progressively incorporated frequency-based techniques into deep learning models, leading to notable improvements in accuracy and efficiency for time series analysis tasks. However, the Mid-Frequency Spectrum Gap in the real-world time series, where the energy is concentrated at the low-frequency region while the middle-frequency band is negligible, hinders the ability of existing deep learning models to extract the crucial frequency information. Additionally, the shared Key-Frequency in multivariate time series, where different time series share indistinguishable frequency patterns, is rarely exploited by existing literature. This work introduces a novel module, Adaptive Mid-Frequency Energy Optimizer, based on convolution and residual learning, to emphasize the significance of mid-frequency bands. We also propose an Energy-based Key-Frequency Picking Block to capture shared Key-Frequency, which achieves superior inter-series modeling performance with fewer parameters. A novel Key-Frequency Enhanced Training strategy is employed to further enhance Key-Frequency modeling, where spectral information from other channels is randomly introduced into each channel. Our approach advanced multivariate time series forecasting on the challenging Traffic, ECL, and Solar benchmarks, reducing MSE by 4%, 6%, and 5% compared to the previous SOTA iTransformer. Code is available at this GitHub Repository: https://github.com/Levi-Ackman/ReFocus.
LiNo: Advancing Recursive Residual Decomposition of Linear and Nonlinear Patterns for Robust Time Series Forecasting
Oct 22, 2024
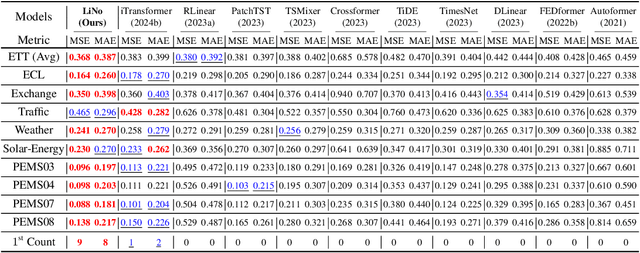

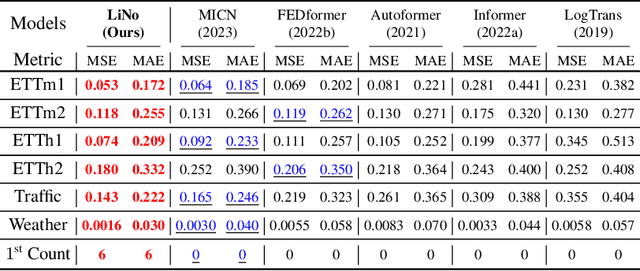
Forecasting models are pivotal in a data-driven world with vast volumes of time series data that appear as a compound of vast Linear and Nonlinear patterns. Recent deep time series forecasting models struggle to utilize seasonal and trend decomposition to separate the entangled components. Such a strategy only explicitly extracts simple linear patterns like trends, leaving the other linear modes and vast unexplored nonlinear patterns to the residual. Their flawed linear and nonlinear feature extraction models and shallow-level decomposition limit their adaptation to the diverse patterns present in real-world scenarios. Given this, we innovate Recursive Residual Decomposition by introducing explicit extraction of both linear and nonlinear patterns. This deeper-level decomposition framework, which is named LiNo, captures linear patterns using a Li block which can be a moving average kernel, and models nonlinear patterns using a No block which can be a Transformer encoder. The extraction of these two patterns is performed alternatively and recursively. To achieve the full potential of LiNo, we develop the current simple linear pattern extractor to a general learnable autoregressive model, and design a novel No block that can handle all essential nonlinear patterns. Remarkably, the proposed LiNo achieves state-of-the-art on thirteen real-world benchmarks under univariate and multivariate forecasting scenarios. Experiments show that current forecasting models can deliver more robust and precise results through this advanced Recursive Residual Decomposition. We hope this work could offer insight into designing more effective forecasting models. Code is available at this Repository: https://github.com/Levi-Ackman/LiNo.
Revitalizing Multivariate Time Series Forecasting: Learnable Decomposition with Inter-Series Dependencies and Intra-Series Variations Modeling
Feb 20, 2024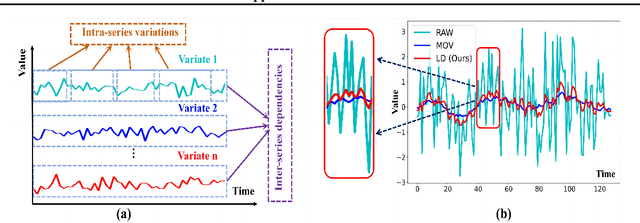


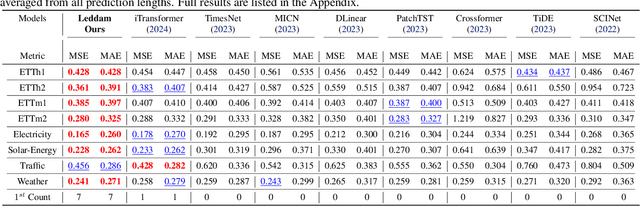
Predicting multivariate time series is crucial, demanding precise modeling of intricate patterns, including inter-series dependencies and intra-series variations. Distinctive trend characteristics in each time series pose challenges, and existing methods, relying on basic moving average kernels, may struggle with the non-linear structure and complex trends in real-world data. Given that, we introduce a learnable decomposition strategy to capture dynamic trend information more reasonably. Additionally, we propose a dual attention module tailored to capture inter-series dependencies and intra-series variations simultaneously for better time series forecasting, which is implemented by channel-wise self-attention and autoregressive self-attention. To evaluate the effectiveness of our method, we conducted experiments across eight open-source datasets and compared it with the state-of-the-art methods. Through the comparison results, our Leddam (LEarnable Decomposition and Dual Attention Module) not only demonstrates significant advancements in predictive performance, but also the proposed decomposition strategy can be plugged into other methods with a large performance-boosting, from 11.87% to 48.56% MSE error degradation.
Leveraging Herpangina Data to Enhance Hospital-level Prediction of Hand-Foot-and-Mouth Disease Admissions Using UPTST
Sep 26, 2023



Outbreaks of hand-foot-and-mouth disease(HFMD) have been associated with significant morbidity and, in severe cases, mortality. Accurate forecasting of daily admissions of pediatric HFMD patients is therefore crucial for aiding the hospital in preparing for potential outbreaks and mitigating nosocomial transmissions. To address this pressing need, we propose a novel transformer-based model with a U-net shape, utilizing the patching strategy and the joint prediction strategy that capitalizes on insights from herpangina, a disease closely correlated with HFMD. This model also integrates representation learning by introducing reconstruction loss as an auxiliary loss. The results show that our U-net Patching Time Series Transformer (UPTST) model outperforms existing approaches in both long- and short-arm prediction accuracy of HFMD at hospital-level. Furthermore, the exploratory extension experiments show that the model's capabilities extend beyond prediction of infectious disease, suggesting broader applicability in various domains.