 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRePO-VLA: Recovery-Driven Policy Optimization for Vision-Language-Action Models
May 10, 2026Vision-Language-Action (VLA) models remain brittle in long-horizon, contact-rich manipulation because success-only imitation provides little supervision for execution drift, while failed rollouts are often discarded. We introduce RePO-VLA, a recovery-driven policy optimization framework that assigns distinct roles to success, recovery, and failure trajectories. RePO-VLA first applies Recovery-Aware Initialization (RAI), slicing recovery segments and resetting history so corrective actions depend on the current adverse state rather than the preceding failure. It then learns a Progress-Aware Semantic Value Function (PAS-VF), aligning spatiotemporal trajectory features with instructions and successful references. The resulting labels salvage useful failure prefixes via reliability decay, while low-value labels mark drift and terminal breakdowns, teaching differences among nominal, failed, and corrective actions. The data engine turns adverse states into planner-generated or human-collected corrective rollouts, teaching recovery to the success manifold. Value-Conditioned Refinement (VCR) trains the policy to prefer high-progress actions. At deployment, a fixed high value ($v=1.0$) biases actions toward the learned success manifold without online failure detectors or heuristic retries. We introduce FRBench, with standardized error injection and recovery-focused evaluation. Across simulated and real-world bimanual tasks, RePO-VLA improves robustness, raising adversarial success from 20% to 75% on average and up to 80% in scaled real-world trials.
A1: A Fully Transparent Open-Source, Adaptive and Efficient Truncated Vision-Language-Action Model
Apr 07, 2026Vision--Language--Action (VLA) models have emerged as a powerful paradigm for open-world robot manipulation, but their practical deployment is often constrained by \emph{cost}: billion-scale VLM backbones and iterative diffusion/flow-based action heads incur high latency and compute, making real-time control expensive on commodity hardware. We present A1, a fully open-source and transparent VLA framework designed for low-cost, high-throughput inference without sacrificing manipulation success; Our approach leverages pretrained VLMs that provide implicit affordance priors for action generation. We release the full training stack (training code, data/data-processing pipeline, intermediate checkpoints, and evaluation scripts) to enable end-to-end reproducibility. Beyond optimizing the VLM alone, A1 targets the full inference pipeline by introducing a budget-aware adaptive inference scheme that jointly accelerates the backbone and the \emph{action head}. Specifically, we monitor action consistency across intermediate VLM layers to trigger early termination, and propose Inter-Layer Truncated Flow Matching that warm-starts denoising across layers, enabling accurate actions with substantially fewer effective denoising iterations. Across simulation benchmarks (LIBERO, VLABench) and real robots (Franka, AgiBot), A1 achieves state-of-the-art success rates while significantly reducing inference cost (e.g., up to 72% lower per-episode latency for flow-matching inference and up to 76.6% backbone computation reduction with minor performance degradation). On RoboChallenge, A1 achieves an average success rate of 29.00%, outperforming baselines including pi0(28.33%), X-VLA (21.33%), and RDT-1B (15.00%).
NAU-QMUL: Utilizing BERT and CLIP for Multi-modal AI-Generated Image Detection
Feb 27, 2026With the aim of detecting AI-generated images and identifying the specific models responsible for their generation, we propose a multi-modal multi-task model. The model leverages pre-trained BERT and CLIP Vision encoders for text and image feature extraction, respectively, and employs cross-modal feature fusion with a tailored multi-task loss function. Additionally, a pseudo-labeling-based data augmentation strategy was utilized to expand the training dataset with high-confidence samples. The model achieved fifth place in both Tasks A and B of the `CT2: AI-Generated Image Detection' competition, with F1 scores of 83.16\% and 48.88\%, respectively. These findings highlight the effectiveness of the proposed architecture and its potential for advancing AI-generated content detection in real-world scenarios. The source code for our method is published on https://github.com/xxxxxxxxy/AIGeneratedImageDetection.
LCGC: Learning from Consistency Gradient Conflicting for Class-Imbalanced Semi-Supervised Debiasing
Apr 09, 2025Classifiers often learn to be biased corresponding to the class-imbalanced dataset, especially under the semi-supervised learning (SSL) set. While previous work tries to appropriately re-balance the classifiers by subtracting a class-irrelevant image's logit, but lacks a firm theoretical basis. We theoretically analyze why exploiting a baseline image can refine pseudo-labels and prove that the black image is the best choice. We also indicated that as the training process deepens, the pseudo-labels before and after refinement become closer. Based on this observation, we propose a debiasing scheme dubbed LCGC, which Learning from Consistency Gradient Conflicting, by encouraging biased class predictions during training. We intentionally update the pseudo-labels whose gradient conflicts with the debiased logits, representing the optimization direction offered by the over-imbalanced classifier predictions. Then, we debiased the predictions by subtracting the baseline image logits during testing. Extensive experiments demonstrate that LCGC can significantly improve the prediction accuracy of existing CISSL models on public benchmarks.
ReFocus: Reinforcing Mid-Frequency and Key-Frequency Modeling for Multivariate Time Series Forecasting
Feb 24, 2025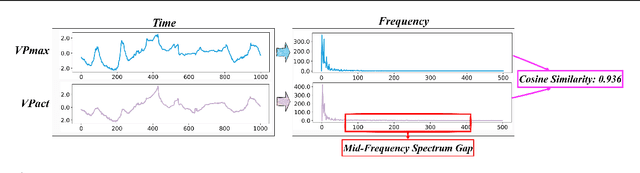


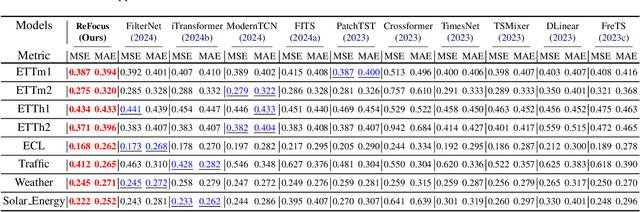
Recent advancements have progressively incorporated frequency-based techniques into deep learning models, leading to notable improvements in accuracy and efficiency for time series analysis tasks. However, the Mid-Frequency Spectrum Gap in the real-world time series, where the energy is concentrated at the low-frequency region while the middle-frequency band is negligible, hinders the ability of existing deep learning models to extract the crucial frequency information. Additionally, the shared Key-Frequency in multivariate time series, where different time series share indistinguishable frequency patterns, is rarely exploited by existing literature. This work introduces a novel module, Adaptive Mid-Frequency Energy Optimizer, based on convolution and residual learning, to emphasize the significance of mid-frequency bands. We also propose an Energy-based Key-Frequency Picking Block to capture shared Key-Frequency, which achieves superior inter-series modeling performance with fewer parameters. A novel Key-Frequency Enhanced Training strategy is employed to further enhance Key-Frequency modeling, where spectral information from other channels is randomly introduced into each channel. Our approach advanced multivariate time series forecasting on the challenging Traffic, ECL, and Solar benchmarks, reducing MSE by 4%, 6%, and 5% compared to the previous SOTA iTransformer. Code is available at this GitHub Repository: https://github.com/Levi-Ackman/ReFocus.
Image-to-Force Estimation for Soft Tissue Interaction in Robotic-Assisted Surgery Using Structured Light
Jan 15, 2025For Minimally Invasive Surgical (MIS) robots, accurate haptic interaction force feedback is essential for ensuring the safety of interacting with soft tissue. However, most existing MIS robotic systems cannot facilitate direct measurement of the interaction force with hardware sensors due to space limitations. This letter introduces an effective vision-based scheme that utilizes a One-Shot structured light projection with a designed pattern on soft tissue coupled with haptic information processing through a trained image-to-force neural network. The images captured from the endoscopic stereo camera are analyzed to reconstruct high-resolution 3D point clouds for soft tissue deformation. Based on this, a modified PointNet-based force estimation method is proposed, which excels in representing the complex mechanical properties of soft tissue. Numerical force interaction experiments are conducted on three silicon materials with different stiffness. The results validate the effectiveness of the proposed scheme.
LOCAL: Learning with Orientation Matrix to Infer Causal Structure from Time Series Data
Oct 28, 2024


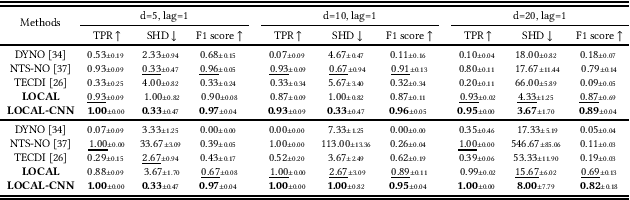
Discovering the underlying Directed Acyclic Graph (DAG) from time series observational data is highly challenging due to the dynamic nature and complex nonlinear interactions between variables. Existing methods often struggle with inefficiency and the handling of high-dimensional data. To address these research gap, we propose LOCAL, a highly efficient, easy-to-implement, and constraint-free method for recovering dynamic causal structures. LOCAL is the first attempt to formulate a quasi-maximum likelihood-based score function for learning the dynamic DAG equivalent to the ground truth. On this basis, we propose two adaptive modules for enhancing the algebraic characterization of acyclicity with new capabilities: Asymptotic Causal Mask Learning (ACML) and Dynamic Graph Parameter Learning (DGPL). ACML generates causal masks using learnable priority vectors and the Gumbel-Sigmoid function, ensuring the creation of DAGs while optimizing computational efficiency. DGPL transforms causal learning into decomposed matrix products, capturing the dynamic causal structure of high-dimensional data and enhancing interpretability. Extensive experiments on synthetic and real-world datasets demonstrate that LOCAL significantly outperforms existing methods, and highlight LOCAL's potential as a robust and efficient method for dynamic causal discovery. Our code will be available soon.
LiNo: Advancing Recursive Residual Decomposition of Linear and Nonlinear Patterns for Robust Time Series Forecasting
Oct 22, 2024
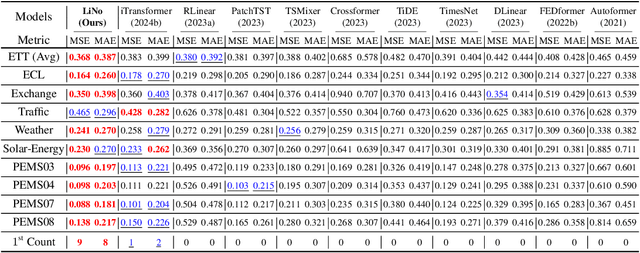

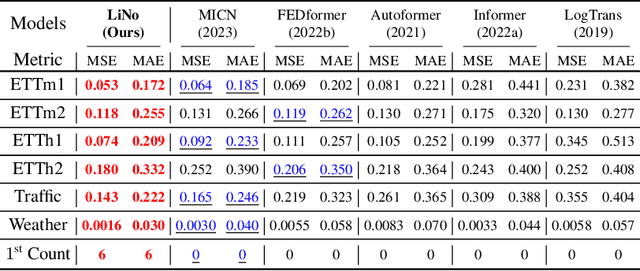
Forecasting models are pivotal in a data-driven world with vast volumes of time series data that appear as a compound of vast Linear and Nonlinear patterns. Recent deep time series forecasting models struggle to utilize seasonal and trend decomposition to separate the entangled components. Such a strategy only explicitly extracts simple linear patterns like trends, leaving the other linear modes and vast unexplored nonlinear patterns to the residual. Their flawed linear and nonlinear feature extraction models and shallow-level decomposition limit their adaptation to the diverse patterns present in real-world scenarios. Given this, we innovate Recursive Residual Decomposition by introducing explicit extraction of both linear and nonlinear patterns. This deeper-level decomposition framework, which is named LiNo, captures linear patterns using a Li block which can be a moving average kernel, and models nonlinear patterns using a No block which can be a Transformer encoder. The extraction of these two patterns is performed alternatively and recursively. To achieve the full potential of LiNo, we develop the current simple linear pattern extractor to a general learnable autoregressive model, and design a novel No block that can handle all essential nonlinear patterns. Remarkably, the proposed LiNo achieves state-of-the-art on thirteen real-world benchmarks under univariate and multivariate forecasting scenarios. Experiments show that current forecasting models can deliver more robust and precise results through this advanced Recursive Residual Decomposition. We hope this work could offer insight into designing more effective forecasting models. Code is available at this Repository: https://github.com/Levi-Ackman/LiNo.
Camouflaged_Object_Tracking__A_Benchmark
Aug 25, 2024



Visual tracking has seen remarkable advancements, largely driven by the availability of large-scale training datasets that have enabled the development of highly accurate and robust algorithms. While significant progress has been made in tracking general objects, research on more challenging scenarios, such as tracking camouflaged objects, remains limited. Camouflaged objects, which blend seamlessly with their surroundings or other objects, present unique challenges for detection and tracking in complex environments. This challenge is particularly critical in applications such as military, security, agriculture, and marine monitoring, where precise tracking of camouflaged objects is essential. To address this gap, we introduce the Camouflaged Object Tracking Dataset (COTD), a specialized benchmark designed specifically for evaluating camouflaged object tracking methods. The COTD dataset comprises 200 sequences and approximately 80,000 frames, each annotated with detailed bounding boxes. Our evaluation of 20 existing tracking algorithms reveals significant deficiencies in their performance with camouflaged objects. To address these issues, we propose a novel tracking framework, HiPTrack-MLS, which demonstrates promising results in improving tracking performance for camouflaged objects. COTD and code are avialable at https://github.com/openat25/HIPTrack-MLS.
Low-Light Object Tracking: A Benchmark
Aug 21, 2024In recent years, the field of visual tracking has made significant progress with the application of large-scale training datasets. These datasets have supported the development of sophisticated algorithms, enhancing the accuracy and stability of visual object tracking. However, most research has primarily focused on favorable illumination circumstances, neglecting the challenges of tracking in low-ligh environments. In low-light scenes, lighting may change dramatically, targets may lack distinct texture features, and in some scenarios, targets may not be directly observable. These factors can lead to a severe decline in tracking performance. To address this issue, we introduce LLOT, a benchmark specifically designed for Low-Light Object Tracking. LLOT comprises 269 challenging sequences with a total of over 132K frames, each carefully annotated with bounding boxes. This specially designed dataset aims to promote innovation and advancement in object tracking techniques for low-light conditions, addressing challenges not adequately covered by existing benchmarks. To assess the performance of existing methods on LLOT, we conducted extensive tests on 39 state-of-the-art tracking algorithms. The results highlight a considerable gap in low-light tracking performance. In response, we propose H-DCPT, a novel tracker that incorporates historical and darkness clue prompts to set a stronger baseline. H-DCPT outperformed all 39 evaluated methods in our experiments, demonstrating significant improvements. We hope that our benchmark and H-DCPT will stimulate the development of novel and accurate methods for tracking objects in low-light conditions. The LLOT and code are available at https://github.com/OpenCodeGithub/H-DCPT.