 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFully Spiking Neural Networks with Target Awareness for Energy-Efficient UAV Tracking
Mar 29, 2026Spiking Neural Networks (SNNs), characterized by their event-driven computation and low power consumption, have shown great potential for energy-efficient visual tracking on unmanned aerial vehicles (UAVs). However, existing efficient SNN-based trackers heavily rely on costly event cameras, limiting their deployment on UAVs. To address this limitation, we propose STATrack, an efficient fully spiking neural network framework for UAV visual tracking using RGB inputs only. To the best of our knowledge, this work is the first to investigate spiking neural networks for UAV visual tracking tasks. To mitigate the weakening of target features by background tokens, we propose adaptively maximizing the mutual information between templates and features. Extensive experiments on four widely used UAV tracking benchmarks demonstrate that STATrack achieves competitive tracking performance while maintaining low energy consumption.
CapeNext: Rethinking and refining dynamic support information for category-agnostic pose estimation
Nov 17, 2025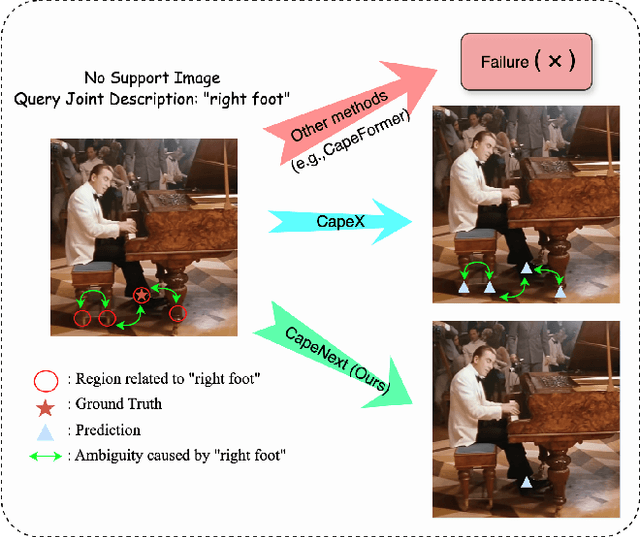
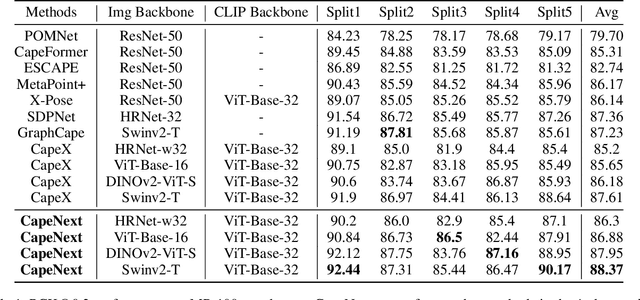
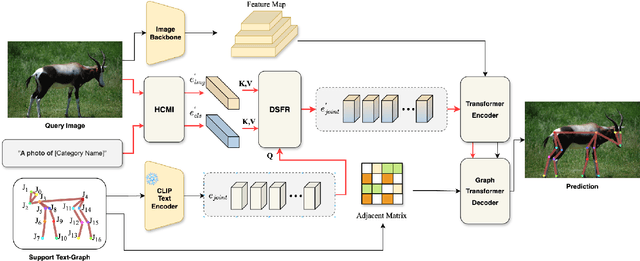
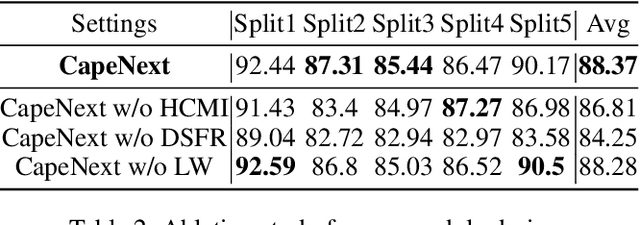
Recent research in Category-Agnostic Pose Estimation (CAPE) has adopted fixed textual keypoint description as semantic prior for two-stage pose matching frameworks. While this paradigm enhances robustness and flexibility by disentangling the dependency of support images, our critical analysis reveals two inherent limitations of static joint embedding: (1) polysemy-induced cross-category ambiguity during the matching process(e.g., the concept "leg" exhibiting divergent visual manifestations across humans and furniture), and (2) insufficient discriminability for fine-grained intra-category variations (e.g., posture and fur discrepancies between a sleeping white cat and a standing black cat). To overcome these challenges, we propose a new framework that innovatively integrates hierarchical cross-modal interaction with dual-stream feature refinement, enhancing the joint embedding with both class-level and instance-specific cues from textual description and specific images. Experiments on the MP-100 dataset demonstrate that, regardless of the network backbone, CapeNext consistently outperforms state-of-the-art CAPE methods by a large margin.
SMTrack: End-to-End Trained Spiking Neural Networks for Multi-Object Tracking in RGB Videos
Aug 20, 2025Brain-inspired Spiking Neural Networks (SNNs) exhibit significant potential for low-power computation, yet their application in visual tasks remains largely confined to image classification, object detection, and event-based tracking. In contrast, real-world vision systems still widely use conventional RGB video streams, where the potential of directly-trained SNNs for complex temporal tasks such as multi-object tracking (MOT) remains underexplored. To address this challenge, we propose SMTrack-the first directly trained deep SNN framework for end-to-end multi-object tracking on standard RGB videos. SMTrack introduces an adaptive and scale-aware Normalized Wasserstein Distance loss (Asa-NWDLoss) to improve detection and localization performance under varying object scales and densities. Specifically, the method computes the average object size within each training batch and dynamically adjusts the normalization factor, thereby enhancing sensitivity to small objects. For the association stage, we incorporate the TrackTrack identity module to maintain robust and consistent object trajectories. Extensive evaluations on BEE24, MOT17, MOT20, and DanceTrack show that SMTrack achieves performance on par with leading ANN-based MOT methods, advancing robust and accurate SNN-based tracking in complex scenarios.
Learning Occlusion-Robust Vision Transformers for Real-Time UAV Tracking
Apr 12, 2025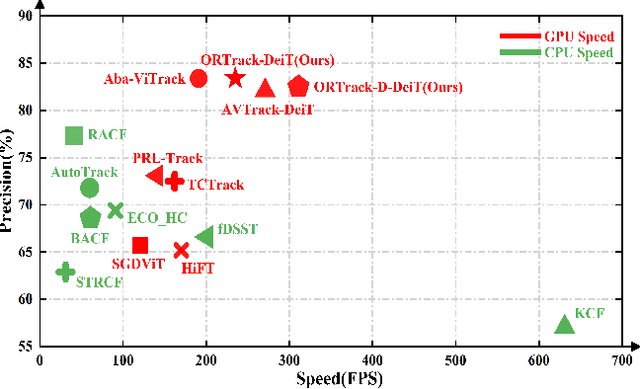
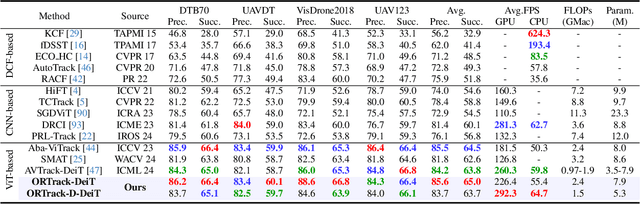
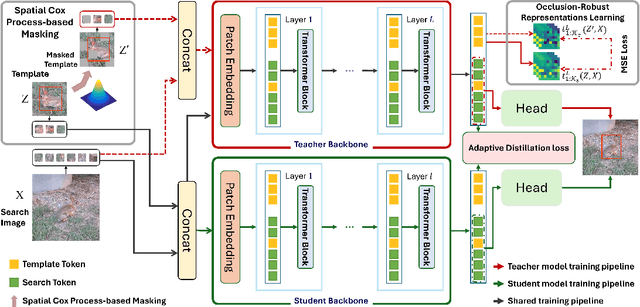

Single-stream architectures using Vision Transformer (ViT) backbones show great potential for real-time UAV tracking recently. However, frequent occlusions from obstacles like buildings and trees expose a major drawback: these models often lack strategies to handle occlusions effectively. New methods are needed to enhance the occlusion resilience of single-stream ViT models in aerial tracking. In this work, we propose to learn Occlusion-Robust Representations (ORR) based on ViTs for UAV tracking by enforcing an invariance of the feature representation of a target with respect to random masking operations modeled by a spatial Cox process. Hopefully, this random masking approximately simulates target occlusions, thereby enabling us to learn ViTs that are robust to target occlusion for UAV tracking. This framework is termed ORTrack. Additionally, to facilitate real-time applications, we propose an Adaptive Feature-Based Knowledge Distillation (AFKD) method to create a more compact tracker, which adaptively mimics the behavior of the teacher model ORTrack according to the task's difficulty. This student model, dubbed ORTrack-D, retains much of ORTrack's performance while offering higher efficiency. Extensive experiments on multiple benchmarks validate the effectiveness of our method, demonstrating its state-of-the-art performance. Codes is available at https://github.com/wuyou3474/ORTrack.
Learning Adaptive and View-Invariant Vision Transformer with Multi-Teacher Knowledge Distillation for Real-Time UAV Tracking
Dec 28, 2024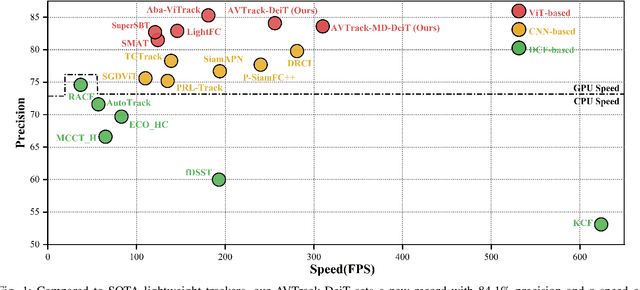
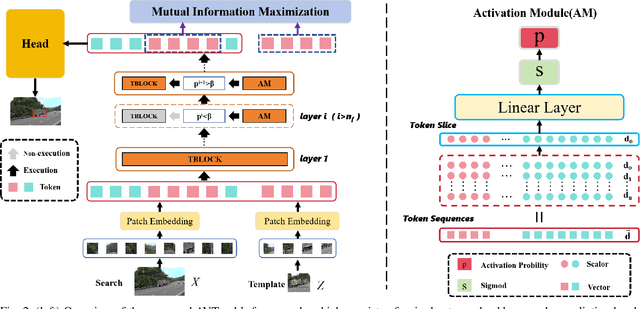
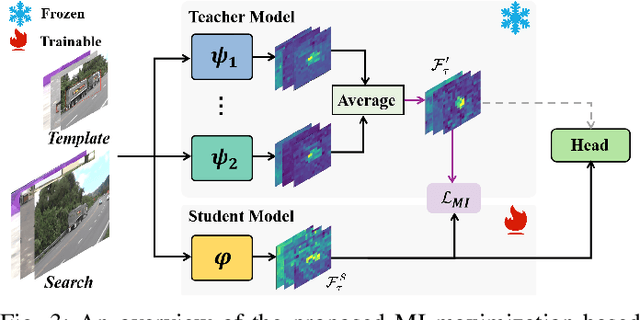
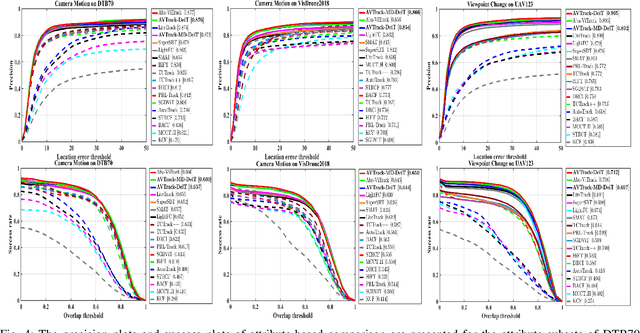
Visual tracking has made significant strides due to the adoption of transformer-based models. Most state-of-the-art trackers struggle to meet real-time processing demands on mobile platforms with constrained computing resources, particularly for real-time unmanned aerial vehicle (UAV) tracking. To achieve a better balance between performance and efficiency, we introduce AVTrack, an adaptive computation framework designed to selectively activate transformer blocks for real-time UAV tracking. The proposed Activation Module (AM) dynamically optimizes the ViT architecture by selectively engaging relevant components, thereby enhancing inference efficiency without significant compromise to tracking performance. Furthermore, to tackle the challenges posed by extreme changes in viewing angles often encountered in UAV tracking, the proposed method enhances ViTs' effectiveness by learning view-invariant representations through mutual information (MI) maximization. Two effective design principles are proposed in the AVTrack. Building on it, we propose an improved tracker, dubbed AVTrack-MD, which introduces the novel MI maximization-based multi-teacher knowledge distillation (MD) framework. It harnesses the benefits of multiple teachers, specifically the off-the-shelf tracking models from the AVTrack, by integrating and refining their outputs, thereby guiding the learning process of the compact student network. Specifically, we maximize the MI between the softened feature representations from the multi-teacher models and the student model, leading to improved generalization and performance of the student model, particularly in noisy conditions. Extensive experiments on multiple UAV tracking benchmarks demonstrate that AVTrack-MD not only achieves performance comparable to the AVTrack baseline but also reduces model complexity, resulting in a significant 17\% increase in average tracking speed.
MambaNUT: Nighttime UAV Tracking via Mamba and Adaptive Curriculum Learning
Dec 01, 2024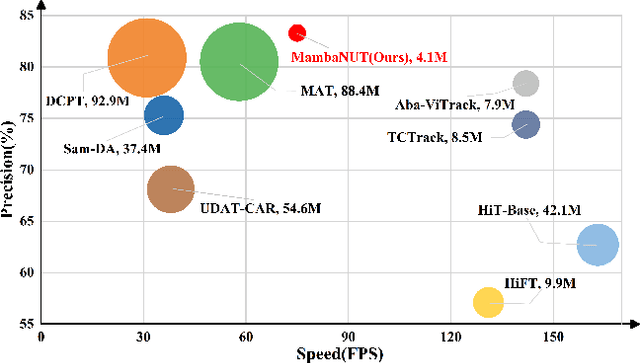
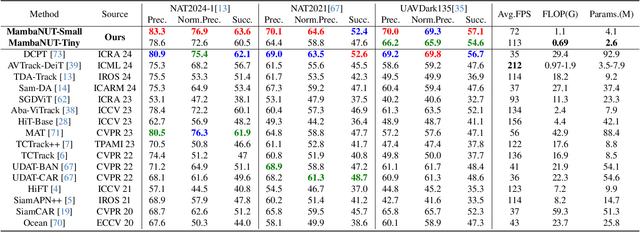
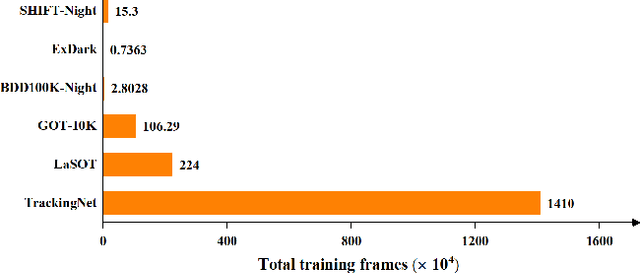

Harnessing low-light enhancement and domain adaptation, nighttime UAV tracking has made substantial strides. However, over-reliance on image enhancement, scarcity of high-quality nighttime data, and neglecting the relationship between daytime and nighttime trackers, which hinders the development of an end-to-end trainable framework. Moreover, current CNN-based trackers have limited receptive fields, leading to suboptimal performance, while ViT-based trackers demand heavy computational resources due to their reliance on the self-attention mechanism. In this paper, we propose a novel pure Mamba-based tracking framework (\textbf{MambaNUT}) that employs a state space model with linear complexity as its backbone, incorporating a single-stream architecture that integrates feature learning and template-search coupling within Vision Mamba. We introduce an adaptive curriculum learning (ACL) approach that dynamically adjusts sampling strategies and loss weights, thereby improving the model's ability of generalization. Our ACL is composed of two levels of curriculum schedulers: (1) sampling scheduler that transforms the data distribution from imbalanced to balanced, as well as from easier (daytime) to harder (nighttime) samples; (2) loss scheduler that dynamically assigns weights based on data frequency and the IOU. Exhaustive experiments on multiple nighttime UAV tracking benchmarks demonstrate that the proposed MambaNUT achieves state-of-the-art performance while requiring lower computational costs. The code will be available.
Camouflaged_Object_Tracking__A_Benchmark
Aug 25, 2024



Visual tracking has seen remarkable advancements, largely driven by the availability of large-scale training datasets that have enabled the development of highly accurate and robust algorithms. While significant progress has been made in tracking general objects, research on more challenging scenarios, such as tracking camouflaged objects, remains limited. Camouflaged objects, which blend seamlessly with their surroundings or other objects, present unique challenges for detection and tracking in complex environments. This challenge is particularly critical in applications such as military, security, agriculture, and marine monitoring, where precise tracking of camouflaged objects is essential. To address this gap, we introduce the Camouflaged Object Tracking Dataset (COTD), a specialized benchmark designed specifically for evaluating camouflaged object tracking methods. The COTD dataset comprises 200 sequences and approximately 80,000 frames, each annotated with detailed bounding boxes. Our evaluation of 20 existing tracking algorithms reveals significant deficiencies in their performance with camouflaged objects. To address these issues, we propose a novel tracking framework, HiPTrack-MLS, which demonstrates promising results in improving tracking performance for camouflaged objects. COTD and code are avialable at https://github.com/openat25/HIPTrack-MLS.
Low-Light Object Tracking: A Benchmark
Aug 21, 2024In recent years, the field of visual tracking has made significant progress with the application of large-scale training datasets. These datasets have supported the development of sophisticated algorithms, enhancing the accuracy and stability of visual object tracking. However, most research has primarily focused on favorable illumination circumstances, neglecting the challenges of tracking in low-ligh environments. In low-light scenes, lighting may change dramatically, targets may lack distinct texture features, and in some scenarios, targets may not be directly observable. These factors can lead to a severe decline in tracking performance. To address this issue, we introduce LLOT, a benchmark specifically designed for Low-Light Object Tracking. LLOT comprises 269 challenging sequences with a total of over 132K frames, each carefully annotated with bounding boxes. This specially designed dataset aims to promote innovation and advancement in object tracking techniques for low-light conditions, addressing challenges not adequately covered by existing benchmarks. To assess the performance of existing methods on LLOT, we conducted extensive tests on 39 state-of-the-art tracking algorithms. The results highlight a considerable gap in low-light tracking performance. In response, we propose H-DCPT, a novel tracker that incorporates historical and darkness clue prompts to set a stronger baseline. H-DCPT outperformed all 39 evaluated methods in our experiments, demonstrating significant improvements. We hope that our benchmark and H-DCPT will stimulate the development of novel and accurate methods for tracking objects in low-light conditions. The LLOT and code are available at https://github.com/OpenCodeGithub/H-DCPT.
Towards Reflected Object Detection: A Benchmark
Jul 08, 2024



Object detection has greatly improved over the past decade thanks to advances in deep learning and large-scale datasets. However, detecting objects reflected in surfaces remains an underexplored area. Reflective surfaces are ubiquitous in daily life, appearing in homes, offices, public spaces, and natural environments. Accurate detection and interpretation of reflected objects are essential for various applications. This paper addresses this gap by introducing a extensive benchmark specifically designed for Reflected Object Detection. Our Reflected Object Detection Dataset (RODD) features a diverse collection of images showcasing reflected objects in various contexts, providing standard annotations for both real and reflected objects. This distinguishes it from traditional object detection benchmarks. RODD encompasses 10 categories and includes 21,059 images of real and reflected objects across different backgrounds, complete with standard bounding box annotations and the classification of objects as real or reflected. Additionally, we present baseline results by adapting five state-of-the-art object detection models to address this challenging task. Experimental results underscore the limitations of existing methods when applied to reflected object detection, highlighting the need for specialized approaches. By releasing RODD, we aim to support and advance future research on detecting reflected objects. Dataset and code are available at: https: //github.com/Tqybu-hans/RODD.
Tracking Reflected Objects: A Benchmark
Jul 07, 2024

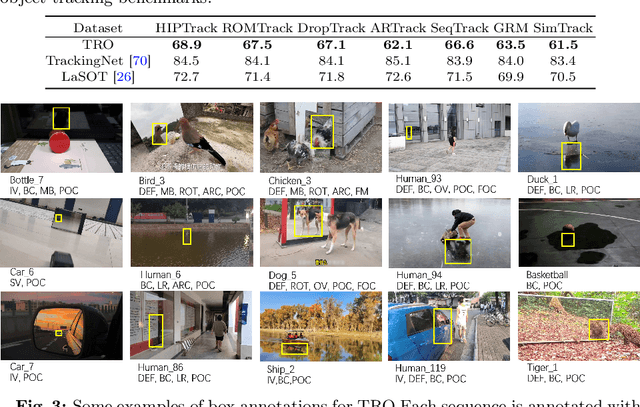
Visual tracking has advanced significantly in recent years, mainly due to the availability of large-scale training datasets. These datasets have enabled the development of numerous algorithms that can track objects with high accuracy and robustness.However, the majority of current research has been directed towards tracking generic objects, with less emphasis on more specialized and challenging scenarios. One such challenging scenario involves tracking reflected objects. Reflections can significantly distort the appearance of objects, creating ambiguous visual cues that complicate the tracking process. This issue is particularly pertinent in applications such as autonomous driving, security, smart homes, and industrial production, where accurately tracking objects reflected in surfaces like mirrors or glass is crucial. To address this gap, we introduce TRO, a benchmark specifically for Tracking Reflected Objects. TRO includes 200 sequences with around 70,000 frames, each carefully annotated with bounding boxes. This dataset aims to encourage the development of new, accurate methods for tracking reflected objects, which present unique challenges not sufficiently covered by existing benchmarks. We evaluated 20 state-of-the-art trackers and found that they struggle with the complexities of reflections. To provide a stronger baseline, we propose a new tracker, HiP-HaTrack, which uses hierarchical features to improve performance, significantly outperforming existing algorithms. We believe our benchmark, evaluation, and HiP-HaTrack will inspire further research and applications in tracking reflected objects. The TRO and code are available at https://github.com/OpenCodeGithub/HIP-HaTrack.