 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCALAR: Scientific Citation-based Live Assessment of Long-context Academic Reasoning
Feb 19, 2025Evaluating large language models' (LLMs) long-context understanding capabilities remains challenging. We present SCALAR (Scientific Citation-based Live Assessment of Long-context Academic Reasoning), a novel benchmark that leverages academic papers and their citation networks. SCALAR features automatic generation of high-quality ground truth labels without human annotation, controllable difficulty levels, and a dynamic updating mechanism that prevents data contamination. Using ICLR 2025 papers, we evaluate 8 state-of-the-art LLMs, revealing key insights about their capabilities and limitations in processing long scientific documents across different context lengths and reasoning types. Our benchmark provides a reliable and sustainable way to track progress in long-context understanding as LLM capabilities evolve.
Tracking Reflected Objects: A Benchmark
Jul 07, 2024

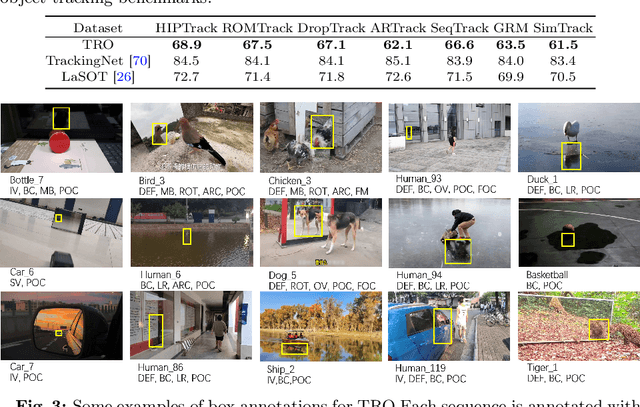
Visual tracking has advanced significantly in recent years, mainly due to the availability of large-scale training datasets. These datasets have enabled the development of numerous algorithms that can track objects with high accuracy and robustness.However, the majority of current research has been directed towards tracking generic objects, with less emphasis on more specialized and challenging scenarios. One such challenging scenario involves tracking reflected objects. Reflections can significantly distort the appearance of objects, creating ambiguous visual cues that complicate the tracking process. This issue is particularly pertinent in applications such as autonomous driving, security, smart homes, and industrial production, where accurately tracking objects reflected in surfaces like mirrors or glass is crucial. To address this gap, we introduce TRO, a benchmark specifically for Tracking Reflected Objects. TRO includes 200 sequences with around 70,000 frames, each carefully annotated with bounding boxes. This dataset aims to encourage the development of new, accurate methods for tracking reflected objects, which present unique challenges not sufficiently covered by existing benchmarks. We evaluated 20 state-of-the-art trackers and found that they struggle with the complexities of reflections. To provide a stronger baseline, we propose a new tracker, HiP-HaTrack, which uses hierarchical features to improve performance, significantly outperforming existing algorithms. We believe our benchmark, evaluation, and HiP-HaTrack will inspire further research and applications in tracking reflected objects. The TRO and code are available at https://github.com/OpenCodeGithub/HIP-HaTrack.
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Mar 31, 2024



Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safety issues as various vulnerabilities are exposed. Faced with the problem, the field of red teaming is experiencing fast-paced growth, which highlights the need for a comprehensive organization covering the entire pipeline and addressing emerging topics for the community. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the searcher framework that unifies various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around multilingual models, overkill of harmless queries, and safety of downstream applications. We hope this survey can provide a systematic perspective on the field and unlock new areas of research.
A Chinese Dataset for Evaluating the Safeguards in Large Language Models
Feb 19, 2024



Many studies have demonstrated that large language models (LLMs) can produce harmful responses, exposing users to unexpected risks when LLMs are deployed. Previous studies have proposed comprehensive taxonomies of the risks posed by LLMs, as well as corresponding prompts that can be used to examine the safety mechanisms of LLMs. However, the focus has been almost exclusively on English, and little has been explored for other languages. Here we aim to bridge this gap. We first introduce a dataset for the safety evaluation of Chinese LLMs, and then extend it to two other scenarios that can be used to better identify false negative and false positive examples in terms of risky prompt rejections. We further present a set of fine-grained safety assessment criteria for each risk type, facilitating both manual annotation and automatic evaluation in terms of LLM response harmfulness. Our experiments on five LLMs show that region-specific risks are the prevalent type of risk, presenting the major issue with all Chinese LLMs we experimented with. Warning: this paper contains example data that may be offensive, harmful, or biased.