 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFLUKE: A Linguistically-Driven and Task-Agnostic Framework for Robustness Evaluation
Apr 24, 2025



We present FLUKE (Framework for LingUistically-driven and tasK-agnostic robustness Evaluation), a task-agnostic framework for assessing model robustness through systematic minimal variations of test data. FLUKE introduces controlled variations across linguistic levels - from orthography to dialect and style varieties - and leverages large language models (LLMs) with human validation to generate modifications. We demonstrate FLUKE's utility by evaluating both fine-tuned models and LLMs across four diverse NLP tasks, and reveal that (1) the impact of linguistic variations is highly task-dependent, with some tests being critical for certain tasks but irrelevant for others; (2) while LLMs have better overall robustness compared to fine-tuned models, they still exhibit significant brittleness to certain linguistic variations; (3) all models show substantial vulnerability to negation modifications across most tasks. These findings highlight the importance of systematic robustness testing for understanding model behaviors.
RuozhiBench: Evaluating LLMs with Logical Fallacies and Misleading Premises
Feb 18, 2025Recent advances in large language models (LLMs) have shown that they can answer questions requiring complex reasoning. However, their ability to identify and respond to text containing logical fallacies or deliberately misleading premises remains less studied. To address this gap, we introduce RuozhiBench, a bilingual dataset comprising 677 carefully curated questions that contain various forms of deceptive reasoning, meticulously crafted through extensive human effort and expert review. In a comprehensive evaluation of 17 LLMs from 5 Series over RuozhiBench using both open-ended and two-choice formats, we conduct extensive analyses on evaluation protocols and result patterns. Despite their high scores on conventional benchmarks, these models showed limited ability to detect and reason correctly about logical fallacies, with even the best-performing model, Claude-3-haiku, achieving only 62% accuracy compared to the human of more than 90%.
Libra-Leaderboard: Towards Responsible AI through a Balanced Leaderboard of Safety and Capability
Dec 24, 2024



To address this gap, we introduce Libra-Leaderboard, a comprehensive framework designed to rank LLMs through a balanced evaluation of performance and safety. Combining a dynamic leaderboard with an interactive LLM arena, Libra-Leaderboard encourages the joint optimization of capability and safety. Unlike traditional approaches that average performance and safety metrics, Libra-Leaderboard uses a distance-to-optimal-score method to calculate the overall rankings. This approach incentivizes models to achieve a balance rather than excelling in one dimension at the expense of some other ones. In the first release, Libra-Leaderboard evaluates 26 mainstream LLMs from 14 leading organizations, identifying critical safety challenges even in state-of-the-art models.
Loki: An Open-Source Tool for Fact Verification
Oct 02, 2024



We introduce Loki, an open-source tool designed to address the growing problem of misinformation. Loki adopts a human-centered approach, striking a balance between the quality of fact-checking and the cost of human involvement. It decomposes the fact-checking task into a five-step pipeline: breaking down long texts into individual claims, assessing their check-worthiness, generating queries, retrieving evidence, and verifying the claims. Instead of fully automating the claim verification process, Loki provides essential information at each step to assist human judgment, especially for general users such as journalists and content moderators. Moreover, it has been optimized for latency, robustness, and cost efficiency at a commercially usable level. Loki is released under an MIT license and is available on GitHub. We also provide a video presenting the system and its capabilities.
Against The Achilles' Heel: A Survey on Red Teaming for Generative Models
Mar 31, 2024



Generative models are rapidly gaining popularity and being integrated into everyday applications, raising concerns over their safety issues as various vulnerabilities are exposed. Faced with the problem, the field of red teaming is experiencing fast-paced growth, which highlights the need for a comprehensive organization covering the entire pipeline and addressing emerging topics for the community. Our extensive survey, which examines over 120 papers, introduces a taxonomy of fine-grained attack strategies grounded in the inherent capabilities of language models. Additionally, we have developed the searcher framework that unifies various automatic red teaming approaches. Moreover, our survey covers novel areas including multimodal attacks and defenses, risks around multilingual models, overkill of harmless queries, and safety of downstream applications. We hope this survey can provide a systematic perspective on the field and unlock new areas of research.
A Chinese Dataset for Evaluating the Safeguards in Large Language Models
Feb 19, 2024



Many studies have demonstrated that large language models (LLMs) can produce harmful responses, exposing users to unexpected risks when LLMs are deployed. Previous studies have proposed comprehensive taxonomies of the risks posed by LLMs, as well as corresponding prompts that can be used to examine the safety mechanisms of LLMs. However, the focus has been almost exclusively on English, and little has been explored for other languages. Here we aim to bridge this gap. We first introduce a dataset for the safety evaluation of Chinese LLMs, and then extend it to two other scenarios that can be used to better identify false negative and false positive examples in terms of risky prompt rejections. We further present a set of fine-grained safety assessment criteria for each risk type, facilitating both manual annotation and automatic evaluation in terms of LLM response harmfulness. Our experiments on five LLMs show that region-specific risks are the prevalent type of risk, presenting the major issue with all Chinese LLMs we experimented with. Warning: this paper contains example data that may be offensive, harmful, or biased.
COVID-SEE: Scientific Evidence Explorer for COVID-19 Related Research
Aug 18, 2020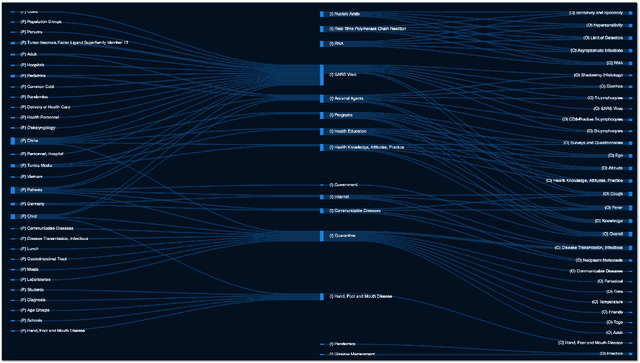

We present COVID-SEE, a system for medical literature discovery based on the concept of information exploration, which builds on several distinct text analysis and natural language processing methods to structure and organise information in publications, and augments search by providing a visual overview supporting exploration of a collection to identify key articles of interest. We developed this system over COVID-19 literature to help medical professionals and researchers explore the literature evidence, and improve findability of relevant information. COVID-SEE is available at http://covid-see.com.
Improving Chemical Named Entity Recognition in Patents with Contextualized Word Embeddings
Jul 05, 2019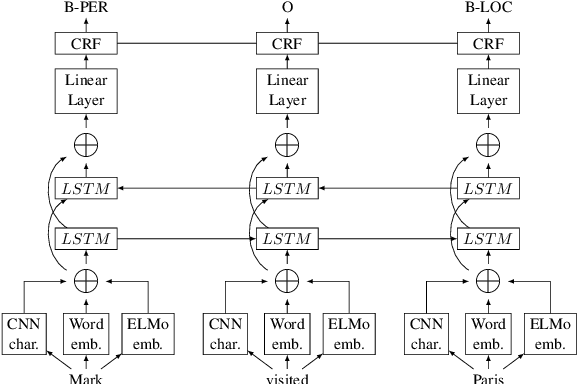
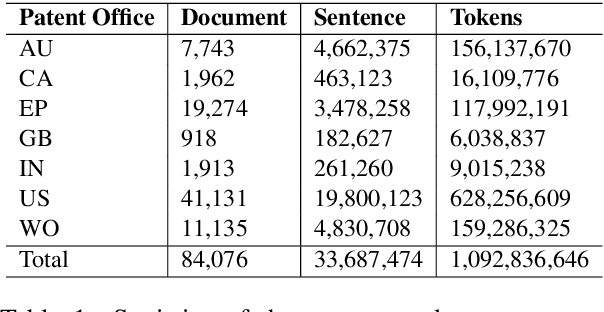

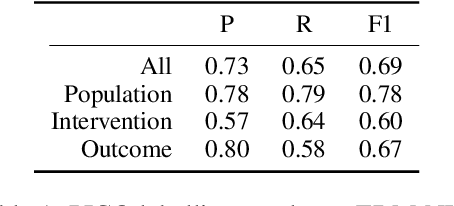
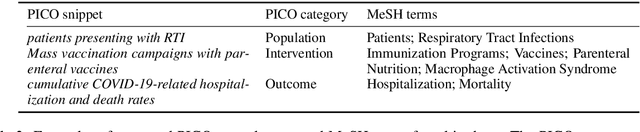
Chemical patents are an important resource for chemical information. However, few chemical Named Entity Recognition (NER) systems have been evaluated on patent documents, due in part to their structural and linguistic complexity. In this paper, we explore the NER performance of a BiLSTM-CRF model utilising pre-trained word embeddings, character-level word representations and contextualized ELMo word representations for chemical patents. We compare word embeddings pre-trained on biomedical and chemical patent corpora. The effect of tokenizers optimized for the chemical domain on NER performance in chemical patents is also explored. The results on two patent corpora show that contextualized word representations generated from ELMo substantially improve chemical NER performance w.r.t. the current state-of-the-art. We also show that domain-specific resources such as word embeddings trained on chemical patents and chemical-specific tokenizers have a positive impact on NER performance.
A bag-of-concepts model improves relation extraction in a narrow knowledge domain with limited data
Apr 24, 2019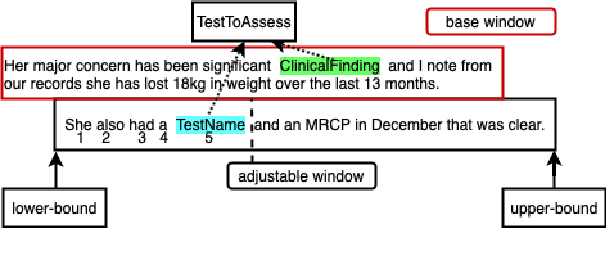
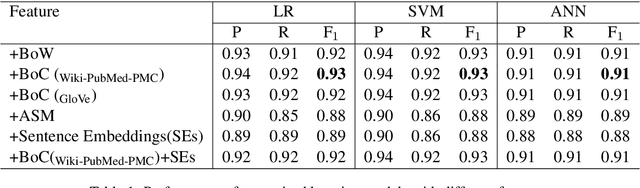
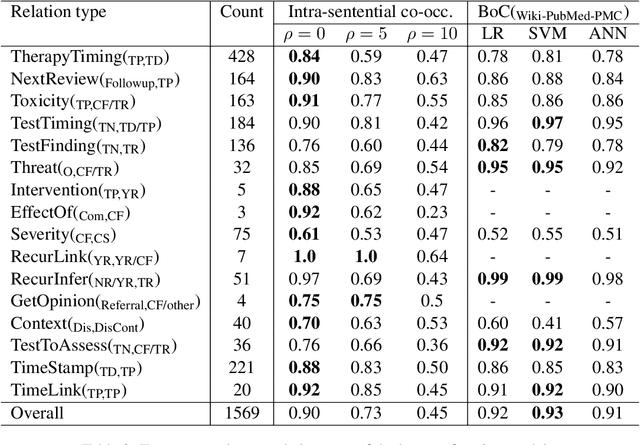
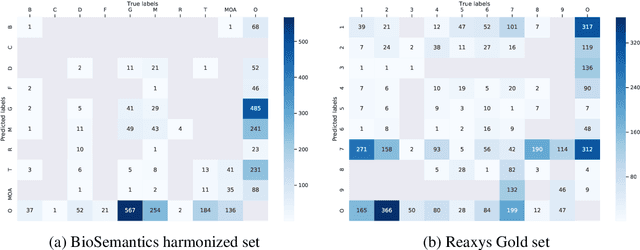
This paper focuses on a traditional relation extraction task in the context of limited annotated data and a narrow knowledge domain. We explore this task with a clinical corpus consisting of 200 breast cancer follow-up treatment letters in which 16 distinct types of relations are annotated. We experiment with an approach to extracting typed relations called window-bounded co-occurrence (WBC), which uses an adjustable context window around entity mentions of a relevant type, and compare its performance with a more typical intra-sentential co-occurrence baseline. We further introduce a new bag-of-concepts (BoC) approach to feature engineering based on the state-of-the-art word embeddings and word synonyms. We demonstrate the competitiveness of BoC by comparing with methods of higher complexity, and explore its effectiveness on this small dataset.
* To appear in Proceedings of the Student Research Workshop at the North American Association for Computational Linguistics (NAACL) meeting 2019
Comparing CNN and LSTM character-level embeddings in BiLSTM-CRF models for chemical and disease named entity recognition
Aug 25, 2018
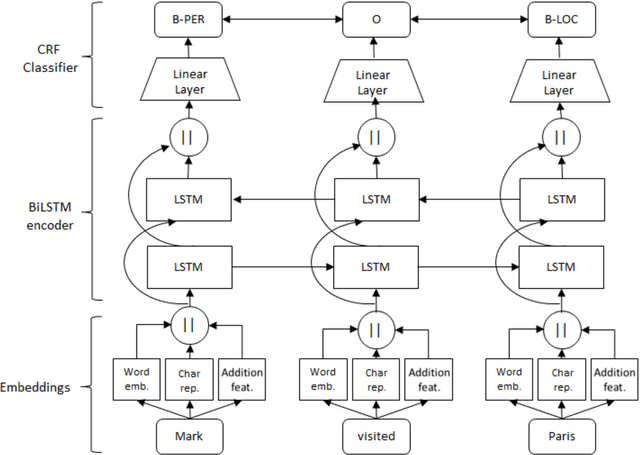


We compare the use of LSTM-based and CNN-based character-level word embeddings in BiLSTM-CRF models to approach chemical and disease named entity recognition (NER) tasks. Empirical results over the BioCreative V CDR corpus show that the use of either type of character-level word embeddings in conjunction with the BiLSTM-CRF models leads to comparable state-of-the-art performance. However, the models using CNN-based character-level word embeddings have a computational performance advantage, increasing training time over word-based models by 25% while the LSTM-based character-level word embeddings more than double the required training time.