 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRADS: Reinforcement Learning-Based Sample Selection Improves Transfer Learning in Low-resource and Imbalanced Clinical Settings
Apr 22, 2026A common strategy in transfer learning is few shot fine-tuning, but its success is highly dependent on the quality of samples selected as training examples. Active learning methods such as uncertainty sampling and diversity sampling can select useful samples. However, under extremely low-resource and class-imbalanced conditions, they often favor outliers rather than truly informative samples, resulting in degraded performance. In this paper, we introduce RADS (Reinforcement Adaptive Domain Sampling), a robust sample selection strategy using reinforcement learning (RL) to identify the most informative samples. Experimental evaluations on several real world clinical datasets show our sample selection strategy enhances model transferability while maintaining robust performance under extreme class imbalance compared to traditional methods.
How Robust Are Large Language Models for Clinical Numeracy? An Empirical Study on Numerical Reasoning Abilities in Clinical Contexts
Apr 13, 2026Large Language Models (LLMs) are increasingly being explored for clinical question answering and decision support, yet safe deployment critically requires reliable handling of patient measurements in heterogeneous clinical notes. Existing evaluations of LLMs for clinical numerical reasoning provide limited operation-level coverage, restricted primarily to arithmetic computation, and rarely assess the robustness of numerical understanding across clinical note formats. We introduce ClinicNumRobBench, a benchmark of 1,624 context-question instances with ground-truth answers that evaluates four main types of clinical numeracy: value retrieval, arithmetic computation, relational comparison, and aggregation. To stress-test robustness, ClinicNumRobBench presents longitudinal MIMIC-IV vital-sign records in three semantically equivalent representations, including a real-world note-style variant derived from the Open Patients dataset, and instantiates queries using 42 question templates. Experiments on 14 LLMs show that value retrieval is generally strong, with most models exceeding 85% accuracy, while relational comparison and aggregation remain challenging, with some models scoring below 15%. Fine-tuning on medical data can reduce numeracy relative to base models by over 30%, and performance drops under note-style variation indicate LLM sensitivity to format. ClinicNumRobBench offers a rigorous testbed for clinically reliable numerical reasoning. Code and data URL are available on https://github.com/MinhVuong2000/ClinicNumRobBench.
Graph Transformers: A Survey
Jul 13, 2024
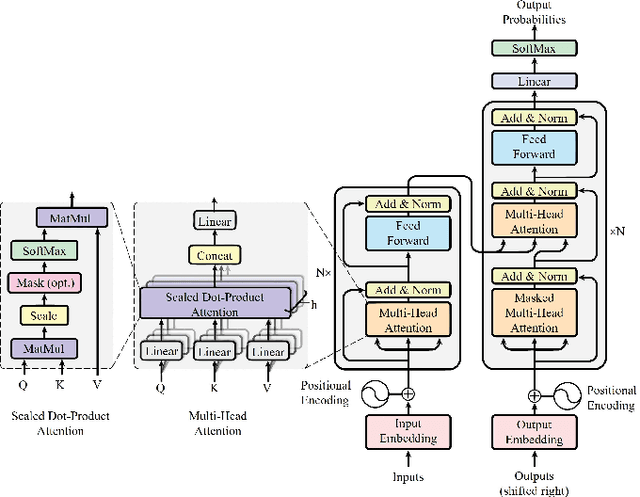
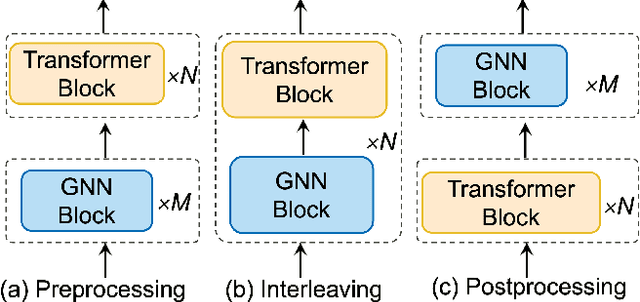
Graph transformers are a recent advancement in machine learning, offering a new class of neural network models for graph-structured data. The synergy between transformers and graph learning demonstrates strong performance and versatility across various graph-related tasks. This survey provides an in-depth review of recent progress and challenges in graph transformer research. We begin with foundational concepts of graphs and transformers. We then explore design perspectives of graph transformers, focusing on how they integrate graph inductive biases and graph attention mechanisms into the transformer architecture. Furthermore, we propose a taxonomy classifying graph transformers based on depth, scalability, and pre-training strategies, summarizing key principles for effective development of graph transformer models. Beyond technical analysis, we discuss the applications of graph transformer models for node-level, edge-level, and graph-level tasks, exploring their potential in other application scenarios as well. Finally, we identify remaining challenges in the field, such as scalability and efficiency, generalization and robustness, interpretability and explainability, dynamic and complex graphs, as well as data quality and diversity, charting future directions for graph transformer research.
Revisiting subword tokenization: A case study on affixal negation in large language models
Apr 04, 2024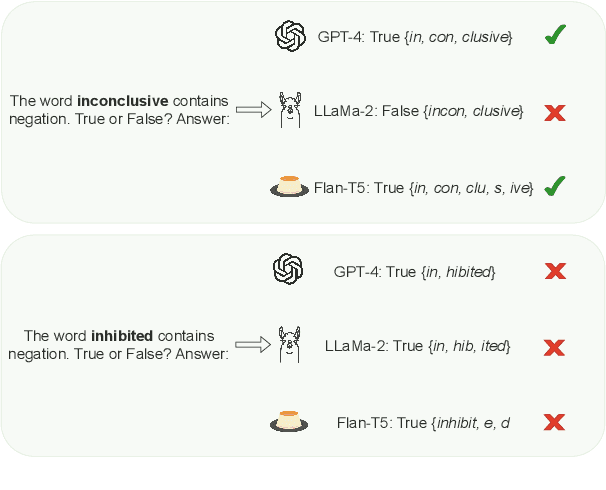
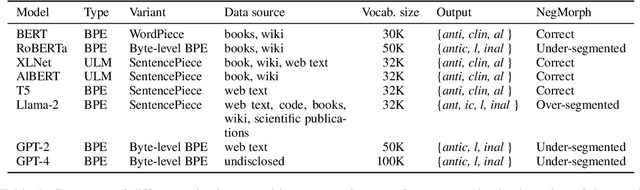
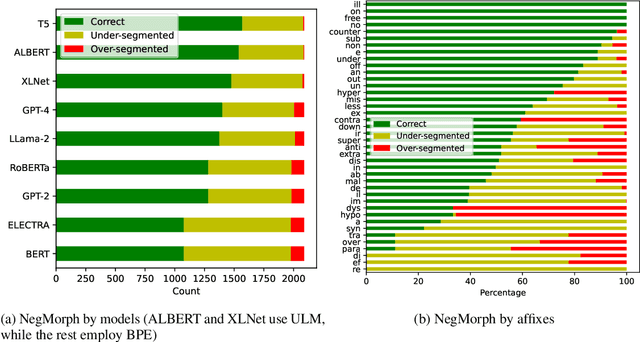
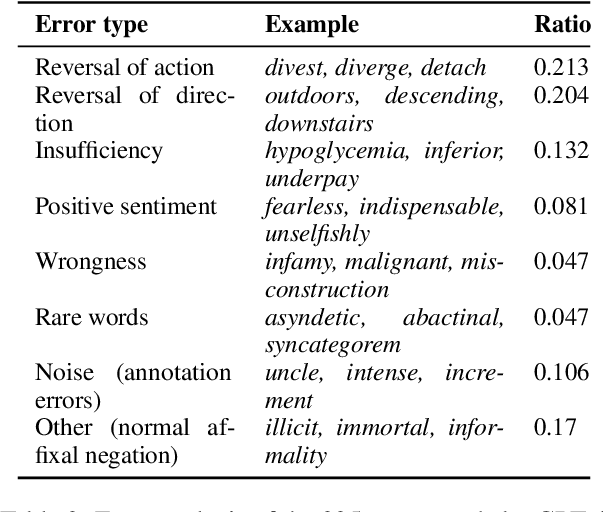
In this work, we measure the impact of affixal negation on modern English large language models (LLMs). In affixal negation, the negated meaning is expressed through a negative morpheme, which is potentially challenging for LLMs as their tokenizers are often not morphologically plausible. We conduct extensive experiments using LLMs with different subword tokenization methods, which lead to several insights on the interaction between tokenization performance and negation sensitivity. Despite some interesting mismatches between tokenization accuracy and negation detection performance, we show that models can, on the whole, reliably recognize the meaning of affixal negation.
Deep Outdated Fact Detection in Knowledge Graphs
Feb 06, 2024Knowledge graphs (KGs) have garnered significant attention for their vast potential across diverse domains. However, the issue of outdated facts poses a challenge to KGs, affecting their overall quality as real-world information evolves. Existing solutions for outdated fact detection often rely on manual recognition. In response, this paper presents DEAN (Deep outdatEd fAct detectioN), a novel deep learning-based framework designed to identify outdated facts within KGs. DEAN distinguishes itself by capturing implicit structural information among facts through comprehensive modeling of both entities and relations. To effectively uncover latent out-of-date information, DEAN employs a contrastive approach based on a pre-defined Relations-to-Nodes (R2N) graph, weighted by the number of entities. Experimental results demonstrate the effectiveness and superiority of DEAN over state-of-the-art baseline methods.
* 10 pages, 6 figures
EMBRE: Entity-aware Masking for Biomedical Relation Extraction
Jan 15, 2024Information extraction techniques, including named entity recognition (NER) and relation extraction (RE), are crucial in many domains to support making sense of vast amounts of unstructured text data by identifying and connecting relevant information. Such techniques can assist researchers in extracting valuable insights. In this paper, we introduce the Entity-aware Masking for Biomedical Relation Extraction (EMBRE) method for biomedical relation extraction, as applied in the context of the BioRED challenge Task 1, in which human-annotated entities are provided as input. Specifically, we integrate entity knowledge into a deep neural network by pretraining the backbone model with an entity masking objective. We randomly mask named entities for each instance and let the model identify the masked entity along with its type. In this way, the model is capable of learning more specific knowledge and more robust representations. Then, we utilize the pre-trained model as our backbone to encode language representations and feed these representations into two multilayer perceptron (MLPs) to predict the logits for relation and novelty, respectively. The experimental results demonstrate that our proposed method can improve the performances of entity pair, relation and novelty extraction over our baseline.
Principles from Clinical Research for NLP Model Generalization
Nov 09, 2023The NLP community typically relies on performance of a model on a held-out test set to assess generalization. Performance drops observed in datasets outside of official test sets are generally attributed to "out-of-distribution'' effects. Here, we explore the foundations of generalizability and study the various factors that affect it, articulating generalizability lessons from clinical studies. In clinical research generalizability depends on (a) internal validity of experiments to ensure controlled measurement of cause and effect, and (b) external validity or transportability of the results to the wider population. We present the need to ensure internal validity when building machine learning models in natural language processing, especially where results may be impacted by spurious correlations in the data. We demonstrate how spurious factors, such as the distance between entities in relation extraction tasks, can affect model internal validity and in turn adversely impact generalization. We also offer guidance on how to analyze generalization failures.
Effects of Human Adversarial and Affable Samples on BERT Generalizability
Oct 17, 2023



BERT-based models have had strong performance on leaderboards, yet have been demonstrably worse in real-world settings requiring generalization. Limited quantities of training data is considered a key impediment to achieving generalizability in machine learning. In this paper, we examine the impact of training data quality, not quantity, on a model's generalizability. We consider two characteristics of training data: the portion of human-adversarial (h-adversarial), i.e., sample pairs with seemingly minor differences but different ground-truth labels, and human-affable (h-affable) training samples, i.e., sample pairs with minor differences but the same ground-truth label. We find that for a fixed size of training samples, as a rule of thumb, having 10-30% h-adversarial instances improves the precision, and therefore F1, by up to 20 points in the tasks of text classification and relation extraction. Increasing h-adversarials beyond this range can result in performance plateaus or even degradation. In contrast, h-affables may not contribute to a model's generalizability and may even degrade generalization performance.
Collective Human Opinions in Semantic Textual Similarity
Aug 08, 2023Despite the subjective nature of semantic textual similarity (STS) and pervasive disagreements in STS annotation, existing benchmarks have used averaged human ratings as the gold standard. Averaging masks the true distribution of human opinions on examples of low agreement, and prevents models from capturing the semantic vagueness that the individual ratings represent. In this work, we introduce USTS, the first Uncertainty-aware STS dataset with ~15,000 Chinese sentence pairs and 150,000 labels, to study collective human opinions in STS. Analysis reveals that neither a scalar nor a single Gaussian fits a set of observed judgements adequately. We further show that current STS models cannot capture the variance caused by human disagreement on individual instances, but rather reflect the predictive confidence over the aggregate dataset.
* 16 pages, 7 figures
Language models are not naysayers: An analysis of language models on negation benchmarks
Jun 14, 2023



Negation has been shown to be a major bottleneck for masked language models, such as BERT. However, whether this finding still holds for larger-sized auto-regressive language models (``LLMs'') has not been studied comprehensively. With the ever-increasing volume of research and applications of LLMs, we take a step back to evaluate the ability of current-generation LLMs to handle negation, a fundamental linguistic phenomenon that is central to language understanding. We evaluate different LLMs -- including the open-source GPT-neo, GPT-3, and InstructGPT -- against a wide range of negation benchmarks. Through systematic experimentation with varying model sizes and prompts, we show that LLMs have several limitations including insensitivity to the presence of negation, an inability to capture the lexical semantics of negation, and a failure to reason under negation.