 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplainable Machine Learning for ICU Readmission Prediction
Sep 27, 2023



The intensive care unit (ICU) comprises a complex hospital environment, where decisions made by clinicians have a high level of risk for the patients' lives. A comprehensive care pathway must then be followed to reduce p complications. Uncertain, competing and unplanned aspects within this environment increase the difficulty in uniformly implementing the care pathway. Readmission contributes to this pathway's difficulty, occurring when patients are admitted again to the ICU in a short timeframe, resulting in high mortality rates and high resource utilisation. Several works have tried to predict readmission through patients' medical information. Although they have some level of success while predicting readmission, those works do not properly assess, characterise and understand readmission prediction. This work proposes a standardised and explainable machine learning pipeline to model patient readmission on a multicentric database (i.e., the eICU cohort with 166,355 patients, 200,859 admissions and 6,021 readmissions) while validating it on monocentric (i.e., the MIMIC IV cohort with 382,278 patients, 523,740 admissions and 5,984 readmissions) and multicentric settings. Our machine learning pipeline achieved predictive performance in terms of the area of the receiver operating characteristic curve (AUC) up to 0.7 with a Random Forest classification model, yielding an overall good calibration and consistency on validation sets. From explanations provided by the constructed models, we could also derive a set of insightful conclusions, primarily on variables related to vital signs and blood tests (e.g., albumin, blood urea nitrogen and hemoglobin levels), demographics (e.g., age, and admission height and weight), and ICU-associated variables (e.g., unit type). These insights provide an invaluable source of information during clinicians' decision-making while discharging ICU patients.
Improving Text-based Early Prediction by Distillation from Privileged Time-Series Text
Jan 26, 2023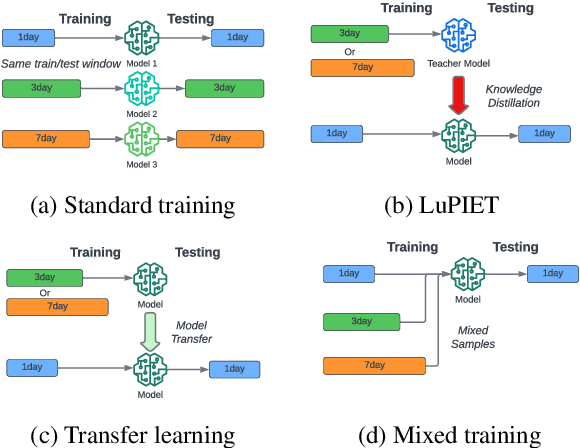
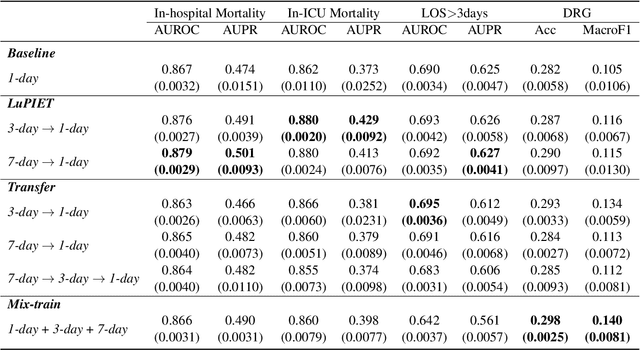
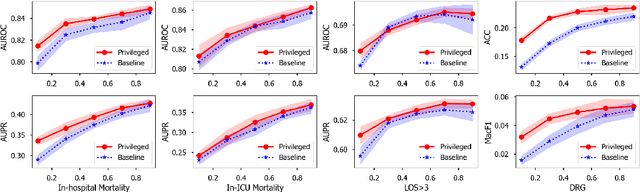
Modeling text-based time-series to make prediction about a future event or outcome is an important task with a wide range of applications. The standard approach is to train and test the model using the same input window, but this approach neglects the data collected in longer input windows between the prediction time and the final outcome, which are often available during training. In this study, we propose to treat this neglected text as privileged information available during training to enhance early prediction modeling through knowledge distillation, presented as Learning using Privileged tIme-sEries Text (LuPIET). We evaluate the method on clinical and social media text, with four clinical prediction tasks based on clinical notes and two mental health prediction tasks based on social media posts. Our results show LuPIET is effective in enhancing text-based early predictions, though one may need to consider choosing the appropriate text representation and windows for privileged text to achieve optimal performance. Compared to two other methods using transfer learning and mixed training, LuPIET offers more stable improvements over the baseline, standard training. As far as we are concerned, this is the first study to examine learning using privileged information for time-series in the NLP context.
Quantifying machine learning-induced overdiagnosis in sepsis
Jul 03, 2021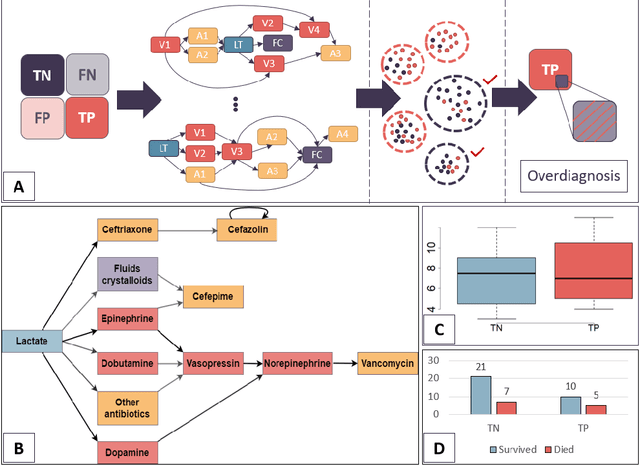
The proliferation of early diagnostic technologies, including self-monitoring systems and wearables, coupled with the application of these technologies on large segments of healthy populations may significantly aggravate the problem of overdiagnosis. This can lead to unwanted consequences such as overloading health care systems and overtreatment, with potential harms to healthy individuals. The advent of machine-learning tools to assist diagnosis -- while promising rapid and more personalised patient management and screening -- might contribute to this issue. The identification of overdiagnosis is usually post hoc and demonstrated after long periods (from years to decades) and costly randomised control trials. In this paper, we present an innovative approach that allows us to preemptively detect potential cases of overdiagnosis during predictive model development. This approach is based on the combination of labels obtained from a prediction model and clustered medical trajectories, using sepsis in adults as a test case. This is one of the first attempts to quantify machine-learning induced overdiagnosis and we believe will serves as a platform for further development, leading to guidelines for safe deployment of computational diagnostic tools.
A Survey on Deep Learning and Explainability for Automatic Image-based Medical Report Generation
Oct 20, 2020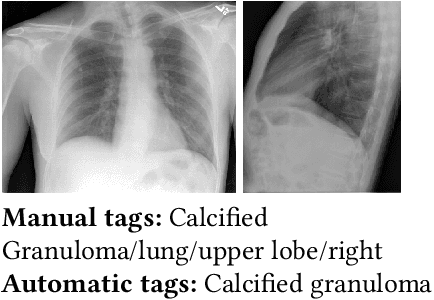
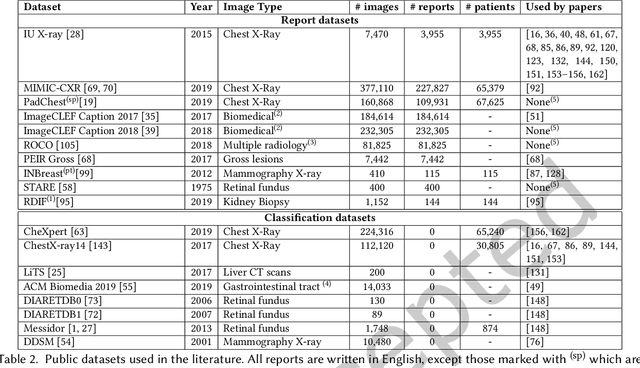
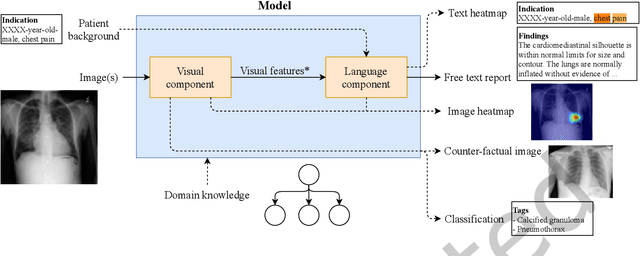
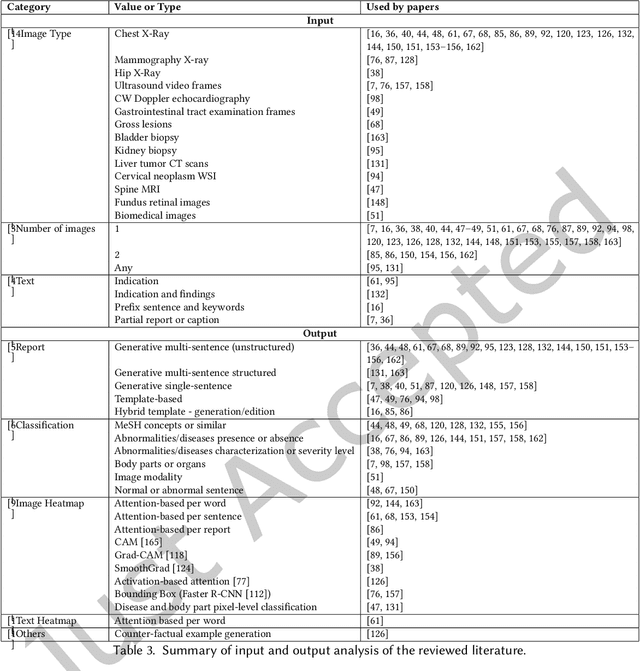
Every year physicians face an increasing demand of image-based diagnosis from patients, a problem that can be addressed with recent artificial intelligence methods. In this context, we survey works in the area of automatic report generation from medical images, with emphasis on methods using deep neural networks, with respect to: (1) Datasets, (2) Architecture Design, (3) Explainability and (4) Evaluation Metrics. Our survey identifies interesting developments, but also remaining challenges. Among them, the current evaluation of generated reports is especially weak, since it mostly relies on traditional Natural Language Processing (NLP) metrics, which do not accurately capture medical correctness.