 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge scale paired antibody language models
Mar 26, 2024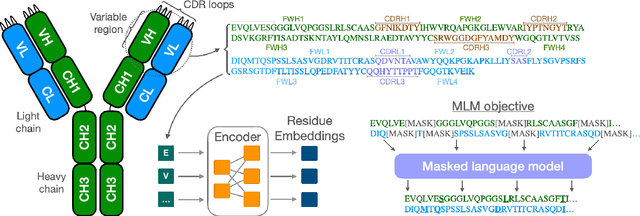
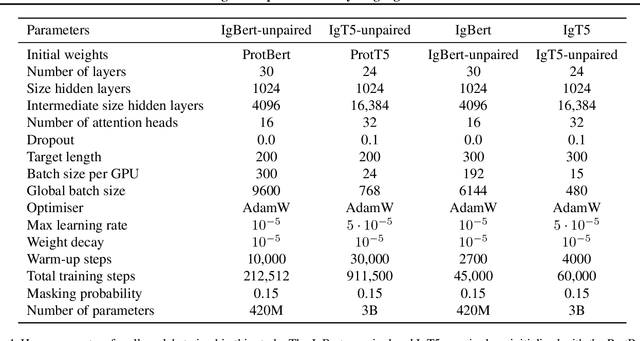
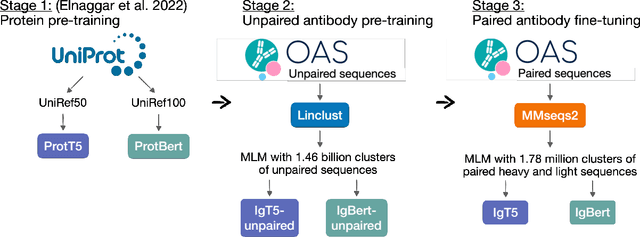
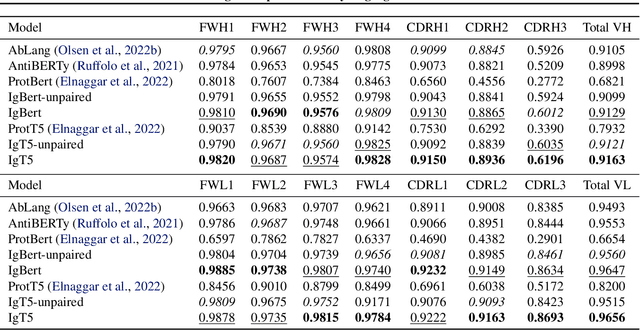
Antibodies are proteins produced by the immune system that can identify and neutralise a wide variety of antigens with high specificity and affinity, and constitute the most successful class of biotherapeutics. With the advent of next-generation sequencing, billions of antibody sequences have been collected in recent years, though their application in the design of better therapeutics has been constrained by the sheer volume and complexity of the data. To address this challenge, we present IgBert and IgT5, the best performing antibody-specific language models developed to date which can consistently handle both paired and unpaired variable region sequences as input. These models are trained comprehensively using the more than two billion unpaired sequences and two million paired sequences of light and heavy chains present in the Observed Antibody Space dataset. We show that our models outperform existing antibody and protein language models on a diverse range of design and regression tasks relevant to antibody engineering. This advancement marks a significant leap forward in leveraging machine learning, large scale data sets and high-performance computing for enhancing antibody design for therapeutic development.
Automating reward function configuration for drug design
Dec 15, 2023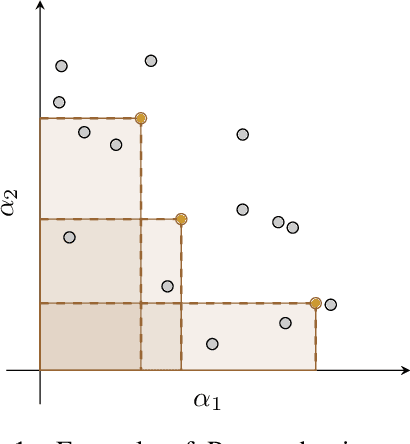
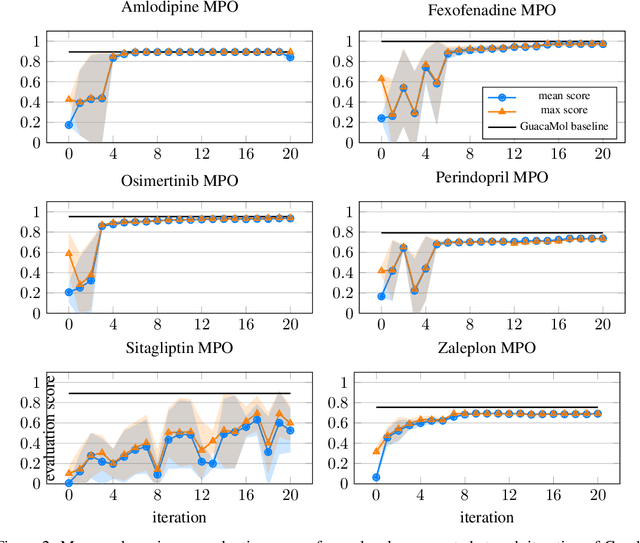
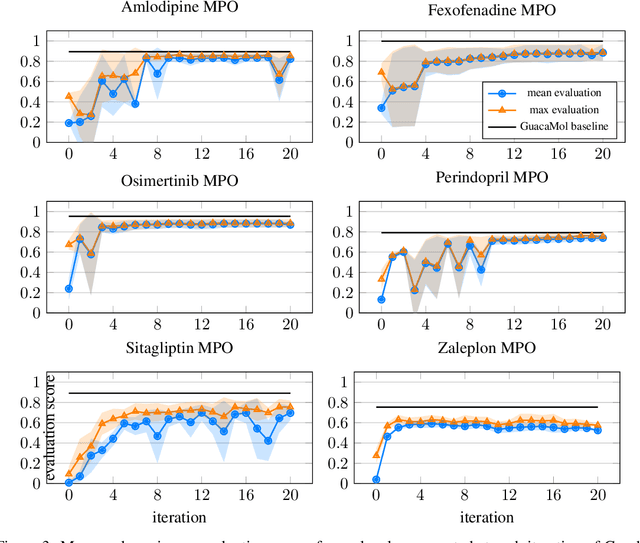
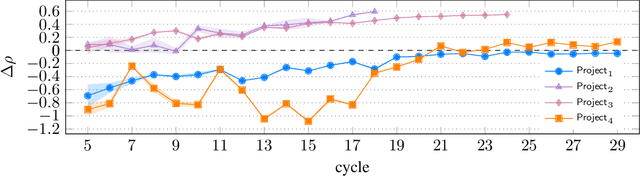
Designing reward functions that guide generative molecular design (GMD) algorithms to desirable areas of chemical space is of critical importance in AI-driven drug discovery. Traditionally, this has been a manual and error-prone task; the selection of appropriate computational methods to approximate biological assays is challenging and the aggregation of computed values into a single score even more so, leading to potential reliance on trial-and-error approaches. We propose a novel approach for automated reward configuration that relies solely on experimental data, mitigating the challenges of manual reward adjustment on drug discovery projects. Our method achieves this by constructing a ranking over experimental data based on Pareto dominance over the multi-objective space, then training a neural network to approximate the reward function such that rankings determined by the predicted reward correlate with those determined by the Pareto dominance relation. We validate our method using two case studies. In the first study we simulate Design-Make-Test-Analyse (DMTA) cycles by alternating reward function updates and generative runs guided by that function. We show that the learned function adapts over time to yield compounds that score highly with respect to evaluation functions taken from the literature. In the second study we apply our algorithm to historical data from four real drug discovery projects. We show that our algorithm yields reward functions that outperform the predictive accuracy of human-defined functions, achieving an improvement of up to 0.4 in Spearman's correlation against a ground truth evaluation function that encodes the target drug profile for that project. Our method provides an efficient data-driven way to configure reward functions for GMD, and serves as a strong baseline for future research into transformative approaches for the automation of drug discovery.
Quantifying machine learning-induced overdiagnosis in sepsis
Jul 03, 2021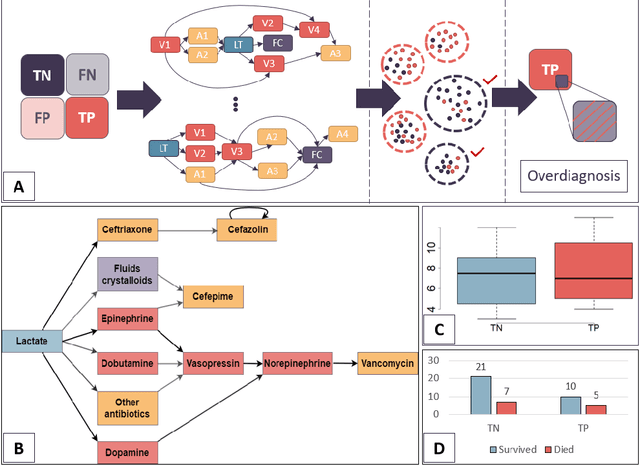
The proliferation of early diagnostic technologies, including self-monitoring systems and wearables, coupled with the application of these technologies on large segments of healthy populations may significantly aggravate the problem of overdiagnosis. This can lead to unwanted consequences such as overloading health care systems and overtreatment, with potential harms to healthy individuals. The advent of machine-learning tools to assist diagnosis -- while promising rapid and more personalised patient management and screening -- might contribute to this issue. The identification of overdiagnosis is usually post hoc and demonstrated after long periods (from years to decades) and costly randomised control trials. In this paper, we present an innovative approach that allows us to preemptively detect potential cases of overdiagnosis during predictive model development. This approach is based on the combination of labels obtained from a prediction model and clustered medical trajectories, using sepsis in adults as a test case. This is one of the first attempts to quantify machine-learning induced overdiagnosis and we believe will serves as a platform for further development, leading to guidelines for safe deployment of computational diagnostic tools.