 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInternational AI Safety Report
Jan 29, 2025



The first International AI Safety Report comprehensively synthesizes the current evidence on the capabilities, risks, and safety of advanced AI systems. The report was mandated by the nations attending the AI Safety Summit in Bletchley, UK. Thirty nations, the UN, the OECD, and the EU each nominated a representative to the report's Expert Advisory Panel. A total of 100 AI experts contributed, representing diverse perspectives and disciplines. Led by the report's Chair, these independent experts collectively had full discretion over the report's content.
EAGLE: Enhanced Visual Grounding Minimizes Hallucinations in Instructional Multimodal Models
Jan 06, 2025Large language models and vision transformers have demonstrated impressive zero-shot capabilities, enabling significant transferability in downstream tasks. The fusion of these models has resulted in multi-modal architectures with enhanced instructional capabilities. Despite incorporating vast image and language pre-training, these multi-modal architectures often generate responses that deviate from the ground truth in the image data. These failure cases are known as hallucinations. Current methods for mitigating hallucinations generally focus on regularizing the language component, improving the fusion module, or ensembling multiple visual encoders to improve visual representation. In this paper, we address the hallucination issue by directly enhancing the capabilities of the visual component. Our approach, named EAGLE, is fully agnostic to the LLM or fusion module and works as a post-pretraining approach that improves the grounding and language alignment of the visual encoder. We show that a straightforward reformulation of the original contrastive pre-training task results in an improved visual encoder that can be incorporated into the instructional multi-modal architecture without additional instructional training. As a result, EAGLE achieves a significant reduction in hallucinations across multiple challenging benchmarks and tasks.
Behind the Magic, MERLIM: Multi-modal Evaluation Benchmark for Large Image-Language Models
Dec 03, 2023



Large Vision and Language Models have enabled significant advances in fully supervised and zero-shot vision tasks. These large pre-trained architectures serve as the baseline to what is currently known as Instruction Tuning Large Vision and Language models (IT-LVLMs). IT-LVLMs are general-purpose multi-modal assistants whose responses are modulated by natural language instructions and arbitrary visual data. Despite this versatility, IT-LVLM effectiveness in fundamental computer vision problems remains unclear, primarily due to the absence of a standardized evaluation benchmark. This paper introduces a Multi-modal Evaluation Benchmark named MERLIM, a scalable test-bed to assess the performance of IT-LVLMs on fundamental computer vision tasks. MERLIM contains over 279K image-question pairs, and has a strong focus on detecting cross-modal "hallucination" events in IT-LVLMs, where the language output refers to visual concepts that lack any effective grounding in the image. Our results show that state-of-the-art IT-LVMLs are still limited at identifying fine-grained visual concepts, object hallucinations are common across tasks, and their results are strongly biased by small variations in the input query, even if the queries have the very same semantics. Our findings also suggest that these models have weak visual groundings but they can still make adequate guesses by global visual patterns or textual biases contained in the LLM component.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 20, 2023



One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.
A Memory Model for Question Answering from Streaming Data Supported by Rehearsal and Anticipation of Coreference Information
May 12, 2023



Existing question answering methods often assume that the input content (e.g., documents or videos) is always accessible to solve the task. Alternatively, memory networks were introduced to mimic the human process of incremental comprehension and compression of the information in a fixed-capacity memory. However, these models only learn how to maintain memory by backpropagating errors in the answers through the entire network. Instead, it has been suggested that humans have effective mechanisms to boost their memorization capacities, such as rehearsal and anticipation. Drawing inspiration from these, we propose a memory model that performs rehearsal and anticipation while processing inputs to memorize important information for solving question answering tasks from streaming data. The proposed mechanisms are applied self-supervised during training through masked modeling tasks focused on coreference information. We validate our model on a short-sequence (bAbI) dataset as well as large-sequence textual (NarrativeQA) and video (ActivityNet-QA) question answering datasets, where it achieves substantial improvements over previous memory network approaches. Furthermore, our ablation study confirms the proposed mechanisms' importance for memory models.
PIVOT: Prompting for Video Continual Learning
Dec 09, 2022



Modern machine learning pipelines are limited due to data availability, storage quotas, privacy regulations, and expensive annotation processes. These constraints make it difficult or impossible to maintain a large-scale model trained on growing annotation sets. Continual learning directly approaches this problem, with the ultimate goal of devising methods where a neural network effectively learns relevant patterns for new (unseen) classes without significantly altering its performance on previously learned ones. In this paper, we address the problem of continual learning for video data. We introduce PIVOT, a novel method that leverages the extensive knowledge in pre-trained models from the image domain, thereby reducing the number of trainable parameters and the associated forgetting. Unlike previous methods, ours is the first approach that effectively uses prompting mechanisms for continual learning without any in-domain pre-training. Our experiments show that PIVOT improves state-of-the-art methods by a significant 27% on the 20-task ActivityNet setup.
How Relevant is Selective Memory Population in Lifelong Language Learning?
Oct 03, 2022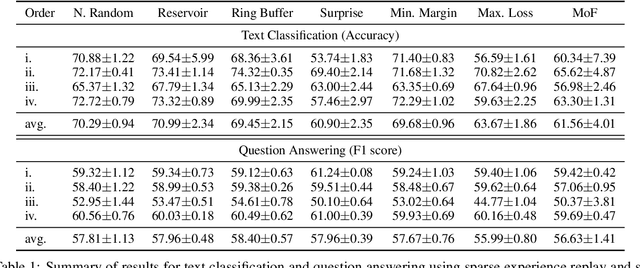
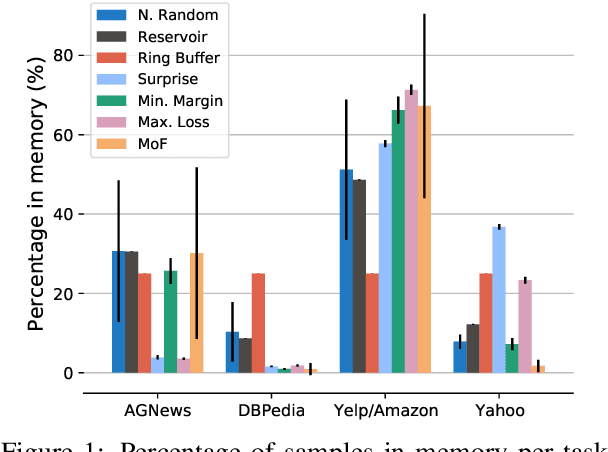

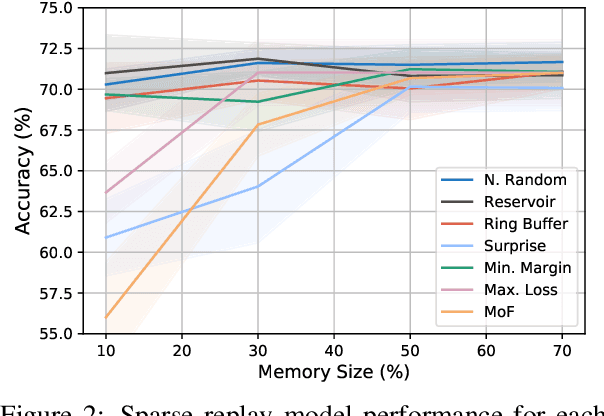
Lifelong language learning seeks to have models continuously learn multiple tasks in a sequential order without suffering from catastrophic forgetting. State-of-the-art approaches rely on sparse experience replay as the primary approach to prevent forgetting. Experience replay usually adopts sampling methods for the memory population; however, the effect of the chosen sampling strategy on model performance has not yet been studied. In this paper, we investigate how relevant the selective memory population is in the lifelong learning process of text classification and question-answering tasks. We found that methods that randomly store a uniform number of samples from the entire data stream lead to high performances, especially for low memory size, which is consistent with computer vision studies.
A Study on the Predictability of Sample Learning Consistency
Jul 07, 2022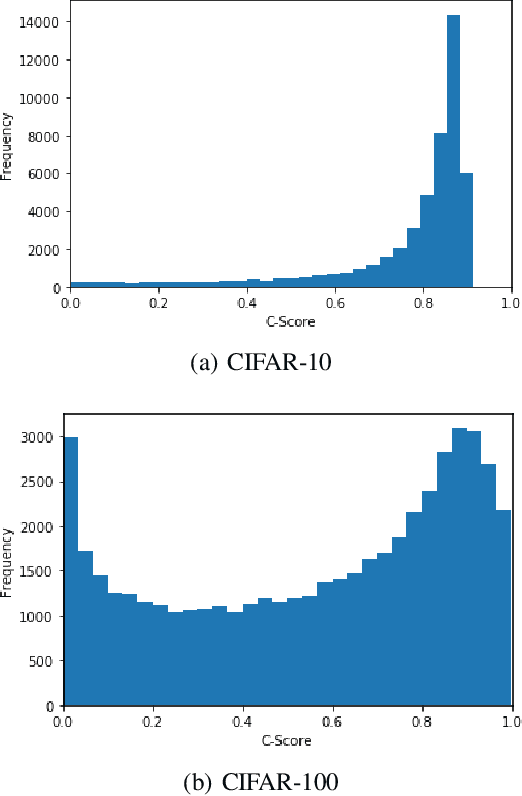
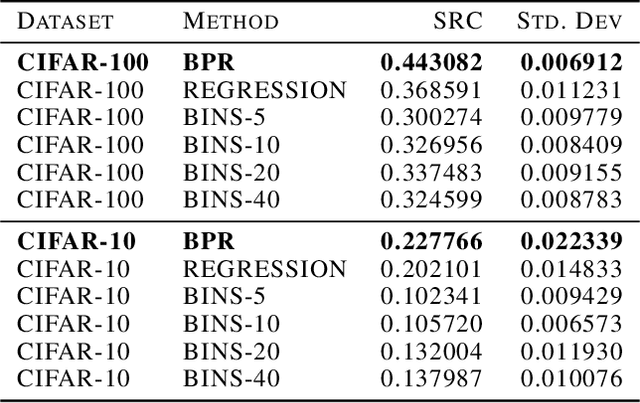
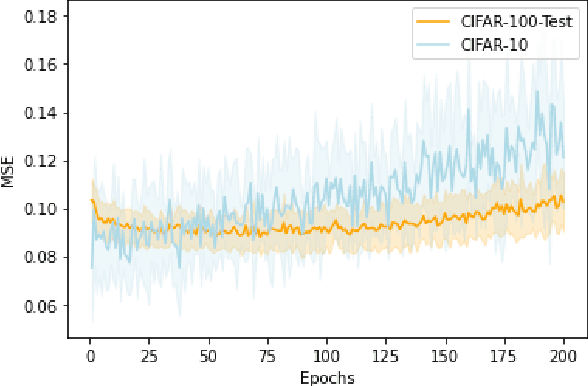
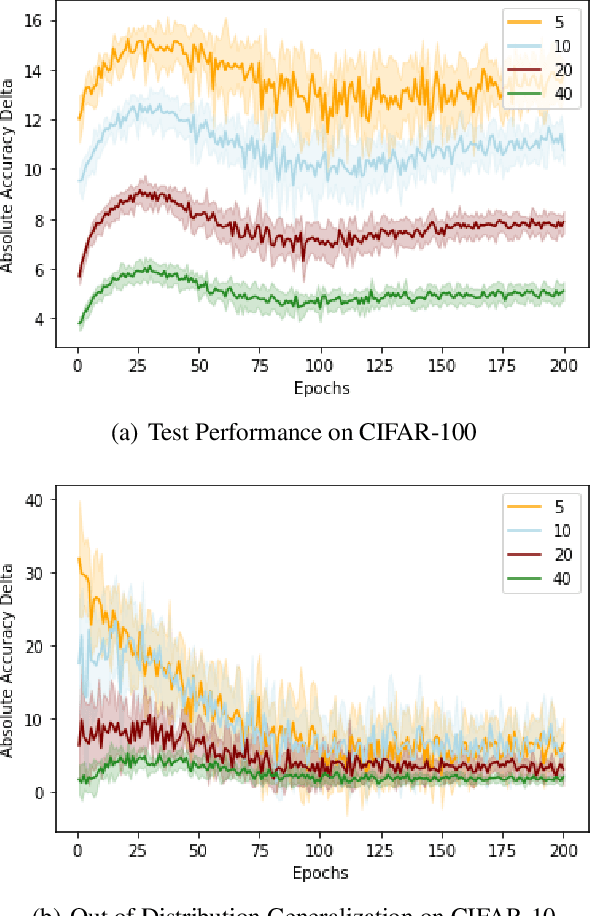
Curriculum Learning is a powerful training method that allows for faster and better training in some settings. This method, however, requires having a notion of which examples are difficult and which are easy, which is not always trivial to provide. A recent metric called C-Score acts as a proxy for example difficulty by relating it to learning consistency. Unfortunately, this method is quite compute intensive which limits its applicability for alternative datasets. In this work, we train models through different methods to predict C-Score for CIFAR-100 and CIFAR-10. We find, however, that these models generalize poorly both within the same distribution as well as out of distribution. This suggests that C-Score is not defined by the individual characteristics of each sample but rather by other factors. We hypothesize that a sample's relation to its neighbours, in particular, how many of them share the same labels, can help in explaining C-Scores. We plan to explore this in future work.
Entropy-based Stability-Plasticity for Lifelong Learning
Apr 18, 2022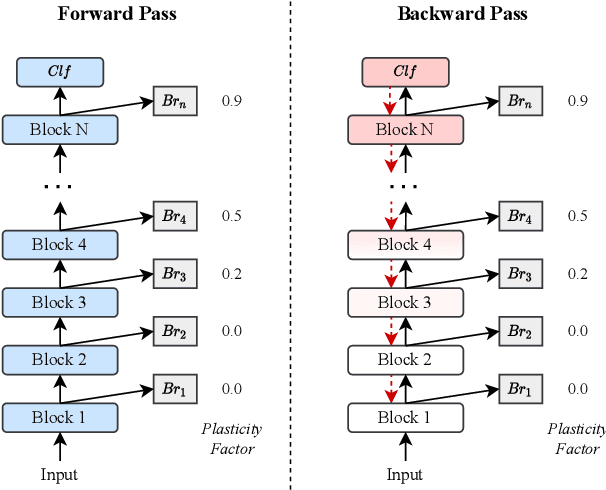
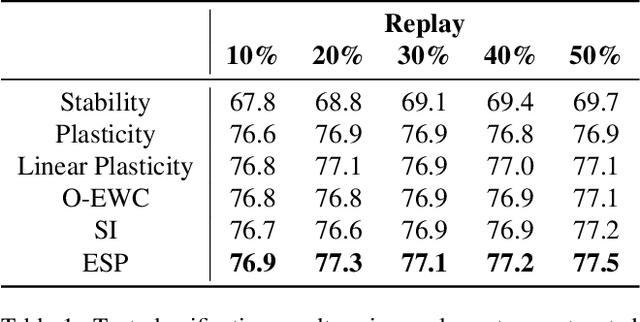
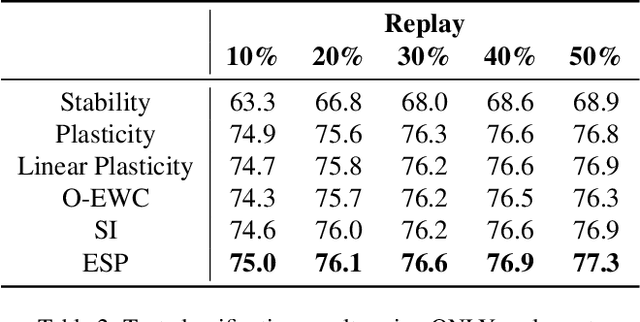
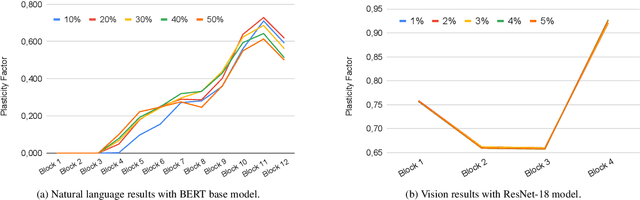
The ability to continuously learn remains elusive for deep learning models. Unlike humans, models cannot accumulate knowledge in their weights when learning new tasks, mainly due to an excess of plasticity and the low incentive to reuse weights when training a new task. To address the stability-plasticity dilemma in neural networks, we propose a novel method called Entropy-based Stability-Plasticity (ESP). Our approach can decide dynamically how much each model layer should be modified via a plasticity factor. We incorporate branch layers and an entropy-based criterion into the model to find such factor. Our experiments in the domains of natural language and vision show the effectiveness of our approach in leveraging prior knowledge by reducing interference. Also, in some cases, it is possible to freeze layers during training leading to speed up in training.
Evaluation Benchmarks for Spanish Sentence Representations
Apr 15, 2022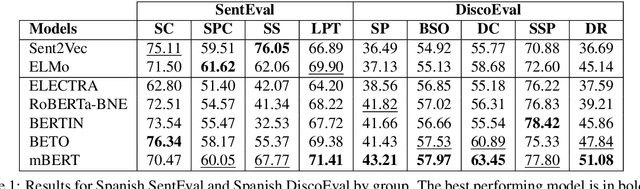
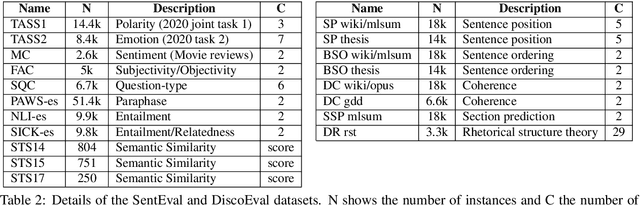
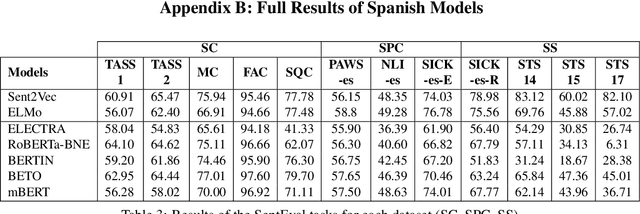
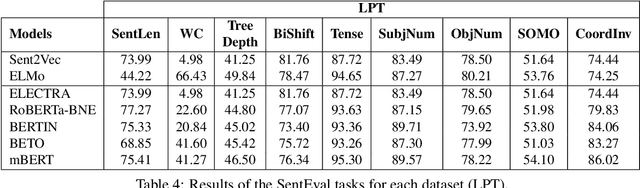
Due to the success of pre-trained language models, versions of languages other than English have been released in recent years. This fact implies the need for resources to evaluate these models. In the case of Spanish, there are few ways to systematically assess the models' quality. In this paper, we narrow the gap by building two evaluation benchmarks. Inspired by previous work (Conneau and Kiela, 2018; Chen et al., 2019), we introduce Spanish SentEval and Spanish DiscoEval, aiming to assess the capabilities of stand-alone and discourse-aware sentence representations, respectively. Our benchmarks include considerable pre-existing and newly constructed datasets that address different tasks from various domains. In addition, we evaluate and analyze the most recent pre-trained Spanish language models to exhibit their capabilities and limitations. As an example, we discover that for the case of discourse evaluation tasks, mBERT, a language model trained on multiple languages, usually provides a richer latent representation than models trained only with documents in Spanish. We hope our contribution will motivate a fairer, more comparable, and less cumbersome way to evaluate future Spanish language models.