 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeing to Generalize: How Visual Data Corrects Binding Shortcuts
Feb 16, 2026Vision Language Models (VLMs) are designed to extend Large Language Models (LLMs) with visual capabilities, yet in this work we observe a surprising phenomenon: VLMs can outperform their underlying LLMs on purely text-only tasks, particularly in long-context information retrieval. To investigate this effect, we build a controlled synthetic retrieval task and find that a transformer trained only on text achieves perfect in-distribution accuracy but fails to generalize out of distribution, while subsequent training on an image-tokenized version of the same task nearly doubles text-only OOD performance. Mechanistic interpretability reveals that visual training changes the model's internal binding strategy: text-only training encourages positional shortcuts, whereas image-based training disrupts them through spatial translation invariance, forcing the model to adopt a more robust symbolic binding mechanism that persists even after text-only examples are reintroduced. We further characterize how binding strategies vary across training regimes, visual encoders, and initializations, and show that analogous shifts occur during pretrained LLM-to-VLM transitions. Our findings suggest that cross-modal training can enhance reasoning and generalization even for tasks grounded in a single modality.
Targeted Image Data Augmentation Increases Basic Skills Captioning Robustness
Sep 27, 2023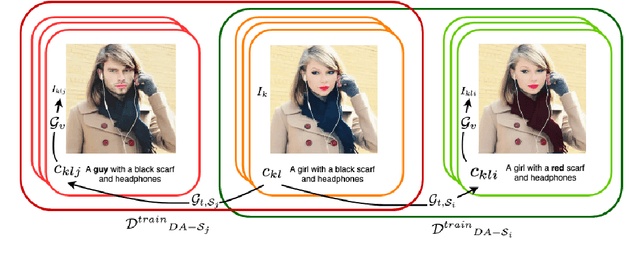
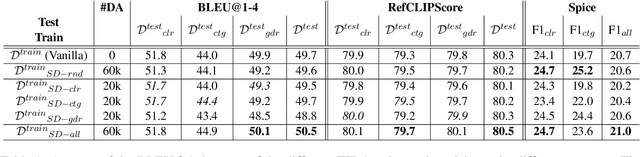
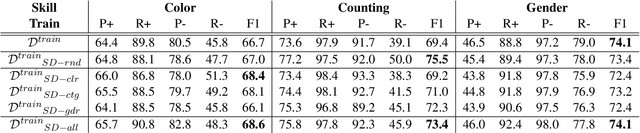
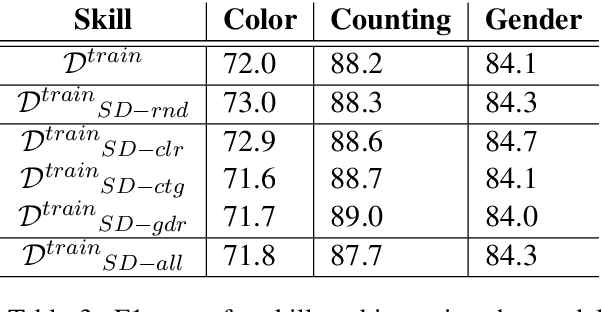
Artificial neural networks typically struggle in generalizing to out-of-context examples. One reason for this limitation is caused by having datasets that incorporate only partial information regarding the potential correlational structure of the world. In this work, we propose TIDA (Targeted Image-editing Data Augmentation), a targeted data augmentation method focused on improving models' human-like abilities (e.g., gender recognition) by filling the correlational structure gap using a text-to-image generative model. More specifically, TIDA identifies specific skills in captions describing images (e.g., the presence of a specific gender in the image), changes the caption (e.g., "woman" to "man"), and then uses a text-to-image model to edit the image in order to match the novel caption (e.g., uniquely changing a woman to a man while maintaining the context identical). Based on the Flickr30K benchmark, we show that, compared with the original data set, a TIDA-enhanced dataset related to gender, color, and counting abilities induces better performance in several image captioning metrics. Furthermore, on top of relying on the classical BLEU metric, we conduct a fine-grained analysis of the improvements of our models against the baseline in different ways. We compared text-to-image generative models and found different behaviors of the image captioning models in terms of encoding visual encoding and textual decoding.
Studying Generalization on Memory-Based Methods in Continual Learning
Jun 20, 2023



One of the objectives of Continual Learning is to learn new concepts continually over a stream of experiences and at the same time avoid catastrophic forgetting. To mitigate complete knowledge overwriting, memory-based methods store a percentage of previous data distributions to be used during training. Although these methods produce good results, few studies have tested their out-of-distribution generalization properties, as well as whether these methods overfit the replay memory. In this work, we show that although these methods can help in traditional in-distribution generalization, they can strongly impair out-of-distribution generalization by learning spurious features and correlations. Using a controlled environment, the Synbol benchmark generator (Lacoste et al., 2020), we demonstrate that this lack of out-of-distribution generalization mainly occurs in the linear classifier.
CuratorNet: Visually-aware Recommendation of Art Images
Sep 30, 2020
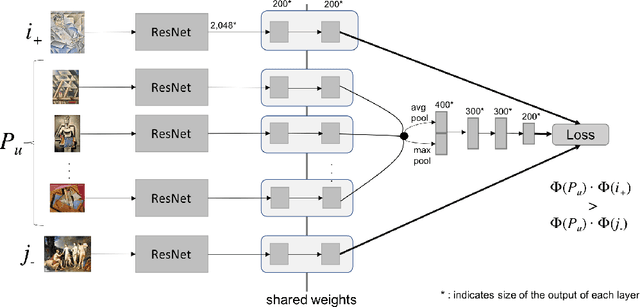

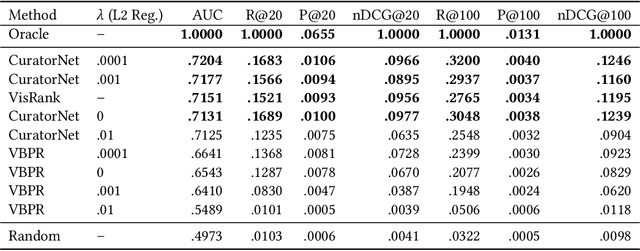
Although there are several visually-aware recommendation models in domains like fashion or even movies, the art domain lacks thesame level of research attention, despite the recent growth of the online artwork market. To reduce this gap, in this article we introduceCuratorNet, a neural network architecture for visually-aware recommendation of art images. CuratorNet is designed at the core withthe goal of maximizing generalization: the network has a fixed set of parameters that only need to be trained once, and thereafter themodel is able to generalize to new users or items never seen before, without further training. This is achieved by leveraging visualcontent: items are mapped to item vectors through visual embeddings, and users are mapped to user vectors by aggregating the visualcontent of items they have consumed. Besides the model architecture, we also introduce novel triplet sampling strategies to build atraining set for rank learning in the art domain, resulting in more effective learning than naive random sampling. With an evaluationover a real-world dataset of physical paintings, we show that CuratorNet achieves the best performance among several baselines,including the state-of-the-art model VBPR. CuratorNet is motivated and evaluated in the art domain, but its architecture and trainingscheme could be adapted to recommend images in other areas
Do Better ImageNet Models Transfer Better for Image Recommendation?
Sep 25, 2018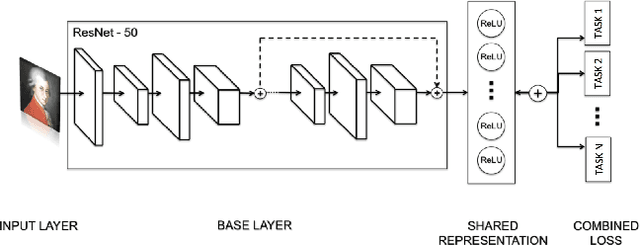
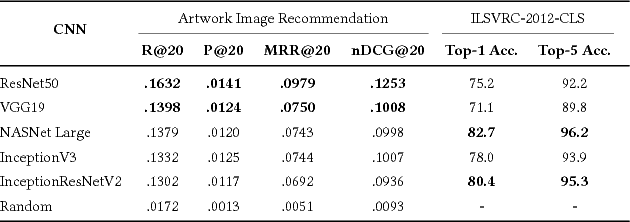
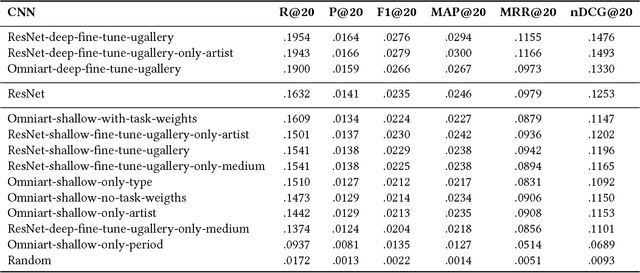
Visual embeddings from Convolutional Neural Networks (CNN) trained on the ImageNet dataset for the ILSVRC challenge have shown consistently good performance for transfer learning and are widely used in several tasks, including image recommendation. However, some important questions have not yet been answered in order to use these embeddings for a larger scope of recommendation domains: a) Do CNNs that perform better in ImageNet are also better for transfer learning in content-based image recommendation?, b) Does fine-tuning help to improve performance? and c) Which is the best way to perform the fine-tuning? In this paper we compare several CNN models pre-trained with ImageNet to evaluate their transfer learning performance to an artwork image recommendation task. Our results indicate that models with better performance in the ImageNet challenge do not always imply better transfer learning for recommendation tasks (e.g. NASNet vs. ResNet). Our results also show that fine-tuning can be helpful even with a small dataset, but not every fine-tuning works. Our results can inform other researchers and practitioners on how to train their CNNs for better transfer learning towards image recommendation systems.