 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Image Data Augmentation Increases Basic Skills Captioning Robustness
Paper and Code
Sep 27, 2023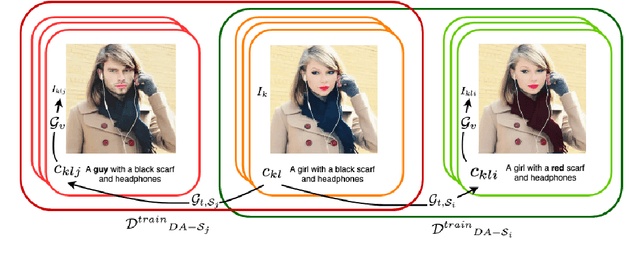
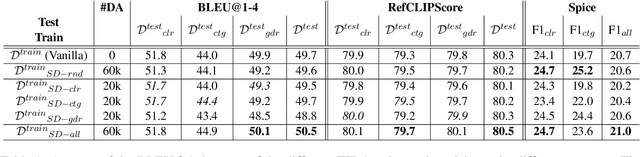
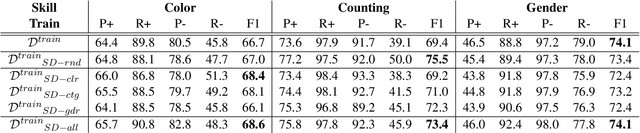
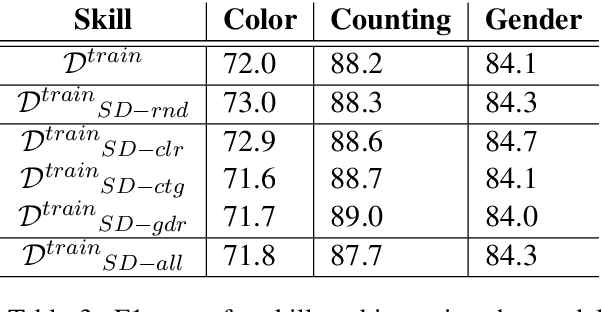
Artificial neural networks typically struggle in generalizing to out-of-context examples. One reason for this limitation is caused by having datasets that incorporate only partial information regarding the potential correlational structure of the world. In this work, we propose TIDA (Targeted Image-editing Data Augmentation), a targeted data augmentation method focused on improving models' human-like abilities (e.g., gender recognition) by filling the correlational structure gap using a text-to-image generative model. More specifically, TIDA identifies specific skills in captions describing images (e.g., the presence of a specific gender in the image), changes the caption (e.g., "woman" to "man"), and then uses a text-to-image model to edit the image in order to match the novel caption (e.g., uniquely changing a woman to a man while maintaining the context identical). Based on the Flickr30K benchmark, we show that, compared with the original data set, a TIDA-enhanced dataset related to gender, color, and counting abilities induces better performance in several image captioning metrics. Furthermore, on top of relying on the classical BLEU metric, we conduct a fine-grained analysis of the improvements of our models against the baseline in different ways. We compared text-to-image generative models and found different behaviors of the image captioning models in terms of encoding visual encoding and textual decoding.