 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTargeted Image Data Augmentation Increases Basic Skills Captioning Robustness
Sep 27, 2023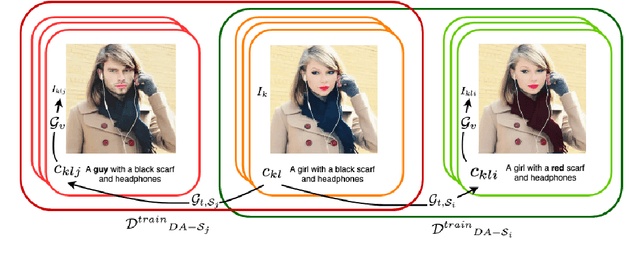
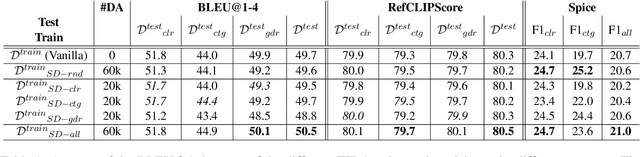
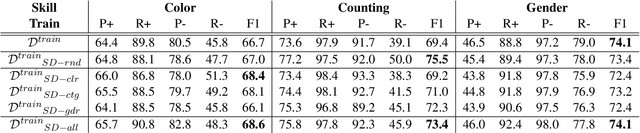
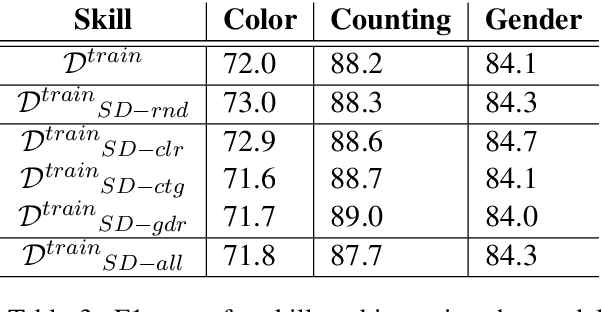
Artificial neural networks typically struggle in generalizing to out-of-context examples. One reason for this limitation is caused by having datasets that incorporate only partial information regarding the potential correlational structure of the world. In this work, we propose TIDA (Targeted Image-editing Data Augmentation), a targeted data augmentation method focused on improving models' human-like abilities (e.g., gender recognition) by filling the correlational structure gap using a text-to-image generative model. More specifically, TIDA identifies specific skills in captions describing images (e.g., the presence of a specific gender in the image), changes the caption (e.g., "woman" to "man"), and then uses a text-to-image model to edit the image in order to match the novel caption (e.g., uniquely changing a woman to a man while maintaining the context identical). Based on the Flickr30K benchmark, we show that, compared with the original data set, a TIDA-enhanced dataset related to gender, color, and counting abilities induces better performance in several image captioning metrics. Furthermore, on top of relying on the classical BLEU metric, we conduct a fine-grained analysis of the improvements of our models against the baseline in different ways. We compared text-to-image generative models and found different behaviors of the image captioning models in terms of encoding visual encoding and textual decoding.
Stress Test Evaluation of Biomedical Word Embeddings
Jul 24, 2021
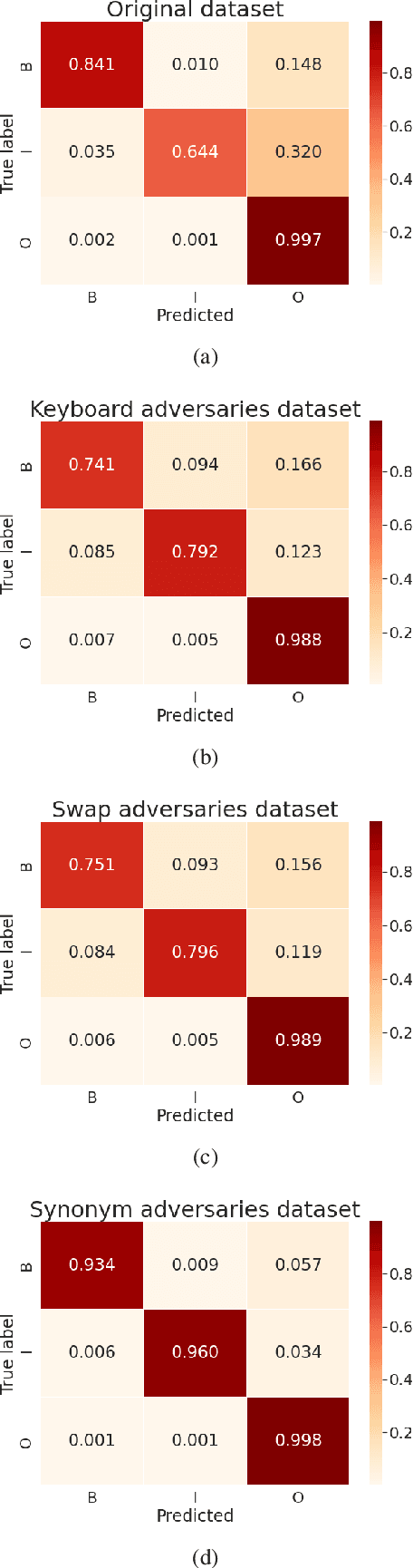

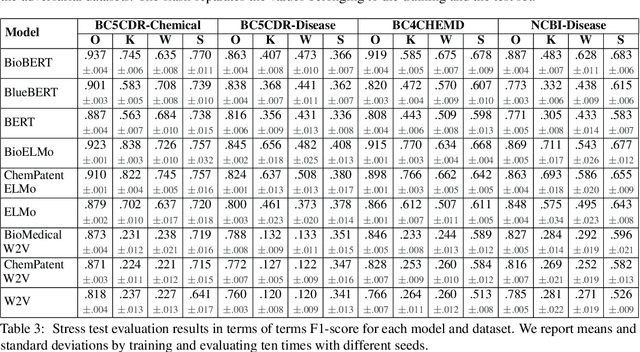
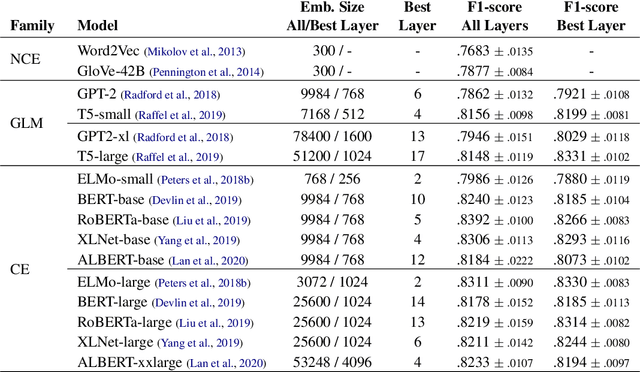
The success of pretrained word embeddings has motivated their use in the biomedical domain, with contextualized embeddings yielding remarkable results in several biomedical NLP tasks. However, there is a lack of research on quantifying their behavior under severe "stress" scenarios. In this work, we systematically evaluate three language models with adversarial examples -- automatically constructed tests that allow us to examine how robust the models are. We propose two types of stress scenarios focused on the biomedical named entity recognition (NER) task, one inspired by spelling errors and another based on the use of synonyms for medical terms. Our experiments with three benchmarks show that the performance of the original models decreases considerably, in addition to revealing their weaknesses and strengths. Finally, we show that adversarial training causes the models to improve their robustness and even to exceed the original performance in some cases.
Inspecting the concept knowledge graph encoded by modern language models
Jun 02, 2021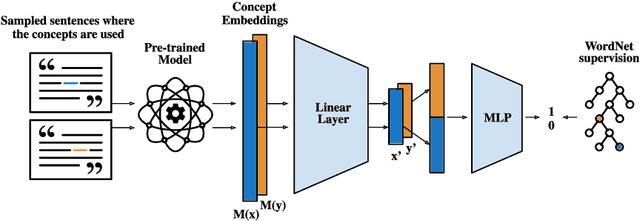
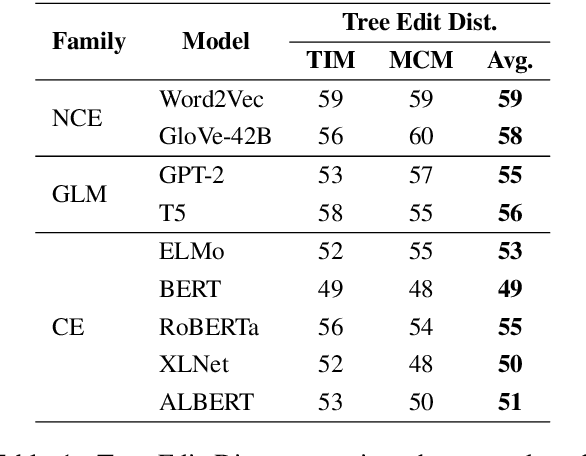
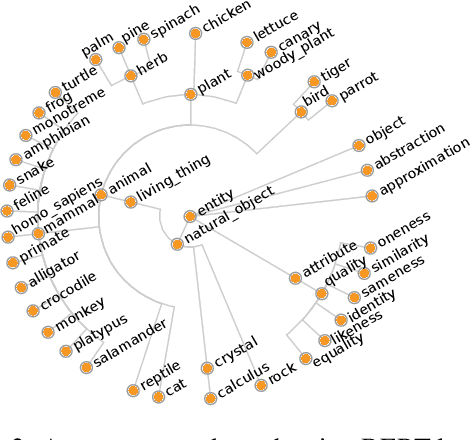
The field of natural language understanding has experienced exponential progress in the last few years, with impressive results in several tasks. This success has motivated researchers to study the underlying knowledge encoded by these models. Despite this, attempts to understand their semantic capabilities have not been successful, often leading to non-conclusive, or contradictory conclusions among different works. Via a probing classifier, we extract the underlying knowledge graph of nine of the most influential language models of the last years, including word embeddings, text generators, and context encoders. This probe is based on concept relatedness, grounded on WordNet. Our results reveal that all the models encode this knowledge, but suffer from several inaccuracies. Furthermore, we show that the different architectures and training strategies lead to different model biases. We conduct a systematic evaluation to discover specific factors that explain why some concepts are challenging. We hope our insights will motivate the development of models that capture concepts more precisely.
On Adversarial Examples for Biomedical NLP Tasks
Apr 23, 2020
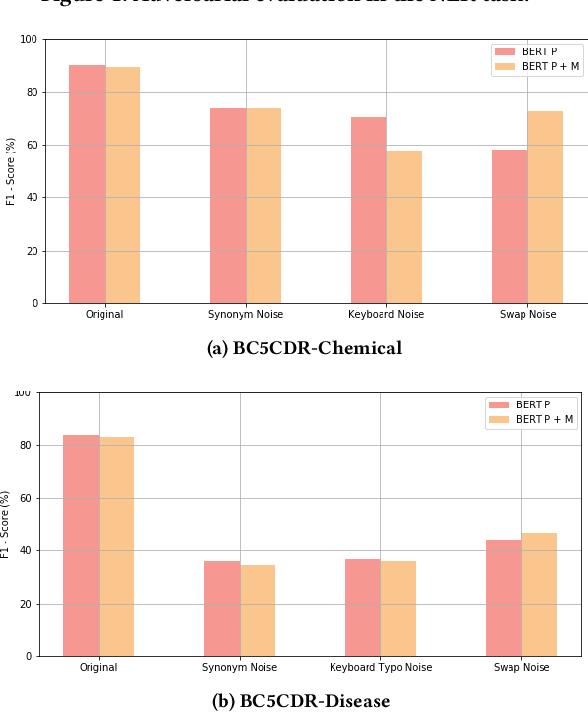
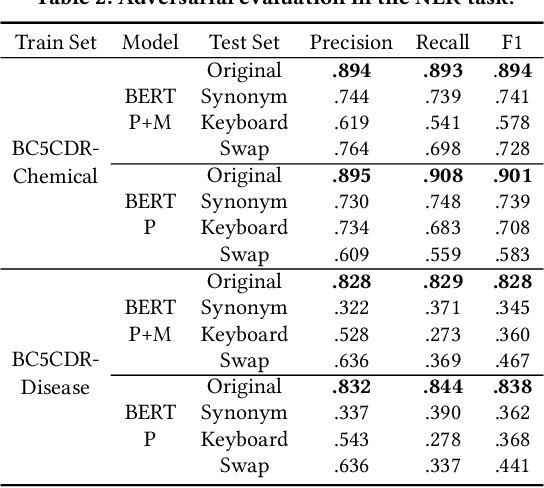
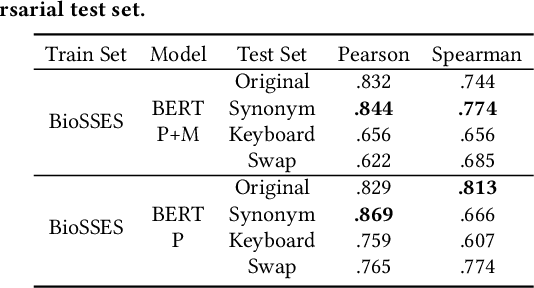
The success of pre-trained word embeddings has motivated its use in tasks in the biomedical domain. The BERT language model has shown remarkable results on standard performance metrics in tasks such as Named Entity Recognition (NER) and Semantic Textual Similarity (STS), which has brought significant progress in the field of NLP. However, it is unclear whether these systems work seemingly well in critical domains, such as legal or medical. For that reason, in this work, we propose an adversarial evaluation scheme on two well-known datasets for medical NER and STS. We propose two types of attacks inspired by natural spelling errors and typos made by humans. We also propose another type of attack that uses synonyms of medical terms. Under these adversarial settings, the accuracy of the models drops significantly, and we quantify the extent of this performance loss. We also show that we can significantly improve the robustness of the models by training them with adversarial examples. We hope our work will motivate the use of adversarial examples to evaluate and develop models with increased robustness for medical tasks.
Stress Test Evaluation of Transformer-based Models in Natural Language Understanding Tasks
Feb 14, 2020
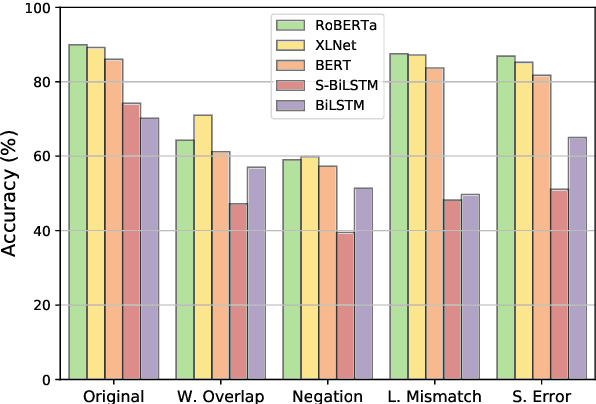
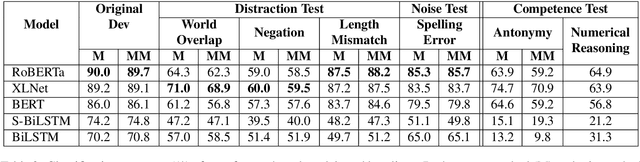
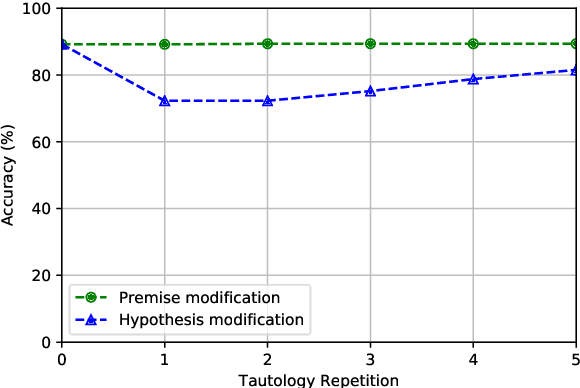
There has been significant progress in recent years in the field of Natural Language Processing thanks to the introduction of the Transformer architecture. Current state-of-the-art models, via a large number of parameters and pre-training on massive text corpus, have shown impressive results on several downstream tasks. Many researchers have studied previous (non-transformer) models to understand their actual behavior under different scenarios, showing that these models are taking advantage of clues or failures of datasets and that slight perturbations on the input data can severely reduce their performance. In contrast, recent models have not been systematically tested with adversarial-examples in order to show their robustness under severe stress conditions. For that reason, this work evaluates three transformer-based models (RoBERTa, XLNet, and BERT) in Natural Language Inference (NLI) and Question Answering (QA) tasks to know if they are more robust or if they have the same flaws as their predecessors. As a result, our experiments reveal that RoBERTa, XLNet and BERT are more robust than recurrent neural network models to stress tests for both NLI and QA tasks. Nevertheless, they are still very fragile and demonstrate various unexpected behaviors, thus revealing that there is still room for future improvement in this field.