 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALBETO and DistilBETO: Lightweight Spanish Language Models
Apr 19, 2022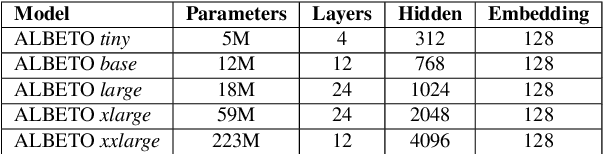

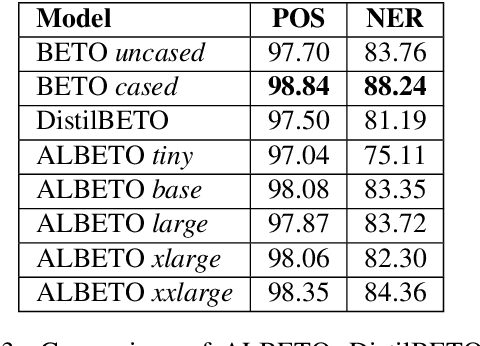
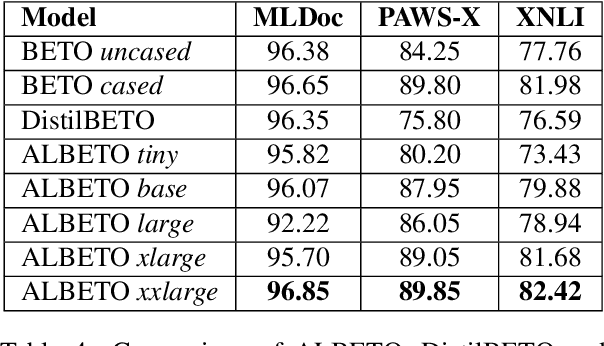
In recent years there have been considerable advances in pre-trained language models, where non-English language versions have also been made available. Due to their increasing use, many lightweight versions of these models (with reduced parameters) have also been released to speed up training and inference times. However, versions of these lighter models (e.g., ALBERT, DistilBERT) for languages other than English are still scarce. In this paper we present ALBETO and DistilBETO, which are versions of ALBERT and DistilBERT pre-trained exclusively on Spanish corpora. We train several versions of ALBETO ranging from 5M to 223M parameters and one of DistilBETO with 67M parameters. We evaluate our models in the GLUES benchmark that includes various natural language understanding tasks in Spanish. The results show that our lightweight models achieve competitive results to those of BETO (Spanish-BERT) despite having fewer parameters. More specifically, our larger ALBETO model outperforms all other models on the MLDoc, PAWS-X, XNLI, MLQA, SQAC and XQuAD datasets. However, BETO remains unbeaten for POS and NER. As a further contribution, all models are publicly available to the community for future research.
Evaluation Benchmarks for Spanish Sentence Representations
Apr 15, 2022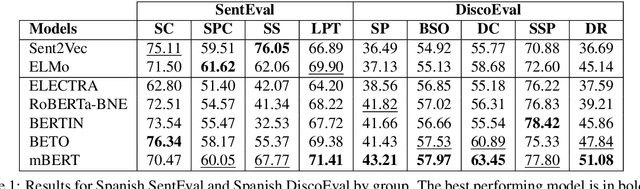
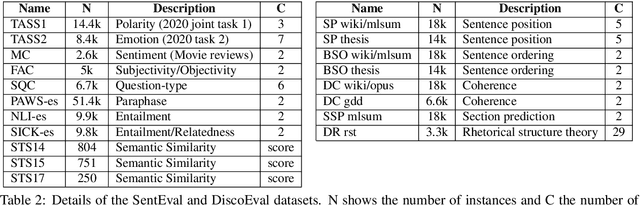
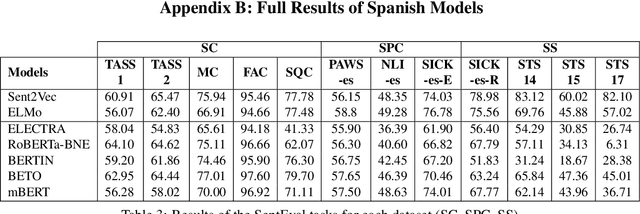
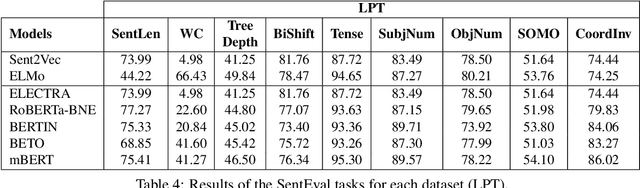
Due to the success of pre-trained language models, versions of languages other than English have been released in recent years. This fact implies the need for resources to evaluate these models. In the case of Spanish, there are few ways to systematically assess the models' quality. In this paper, we narrow the gap by building two evaluation benchmarks. Inspired by previous work (Conneau and Kiela, 2018; Chen et al., 2019), we introduce Spanish SentEval and Spanish DiscoEval, aiming to assess the capabilities of stand-alone and discourse-aware sentence representations, respectively. Our benchmarks include considerable pre-existing and newly constructed datasets that address different tasks from various domains. In addition, we evaluate and analyze the most recent pre-trained Spanish language models to exhibit their capabilities and limitations. As an example, we discover that for the case of discourse evaluation tasks, mBERT, a language model trained on multiple languages, usually provides a richer latent representation than models trained only with documents in Spanish. We hope our contribution will motivate a fairer, more comparable, and less cumbersome way to evaluate future Spanish language models.
Stress Test Evaluation of Biomedical Word Embeddings
Jul 24, 2021
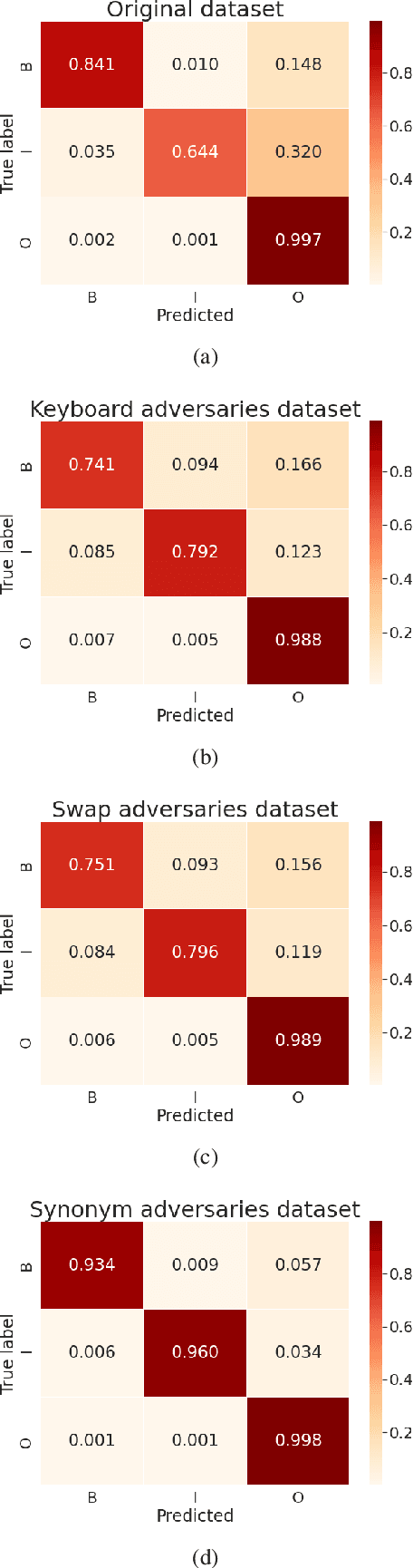

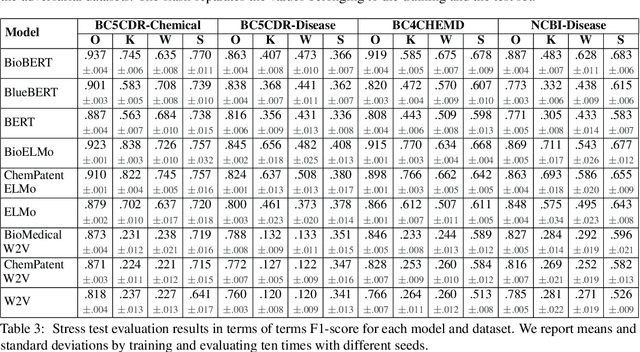
The success of pretrained word embeddings has motivated their use in the biomedical domain, with contextualized embeddings yielding remarkable results in several biomedical NLP tasks. However, there is a lack of research on quantifying their behavior under severe "stress" scenarios. In this work, we systematically evaluate three language models with adversarial examples -- automatically constructed tests that allow us to examine how robust the models are. We propose two types of stress scenarios focused on the biomedical named entity recognition (NER) task, one inspired by spelling errors and another based on the use of synonyms for medical terms. Our experiments with three benchmarks show that the performance of the original models decreases considerably, in addition to revealing their weaknesses and strengths. Finally, we show that adversarial training causes the models to improve their robustness and even to exceed the original performance in some cases.
Rating and aspect-based opinion graph embeddings for explainable recommendations
Jul 07, 2021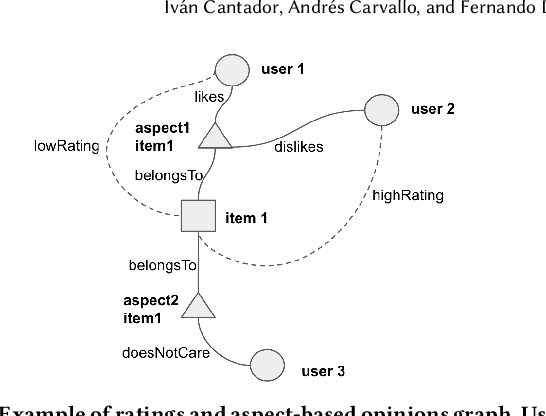
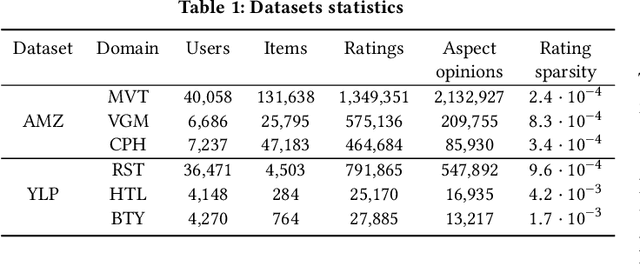

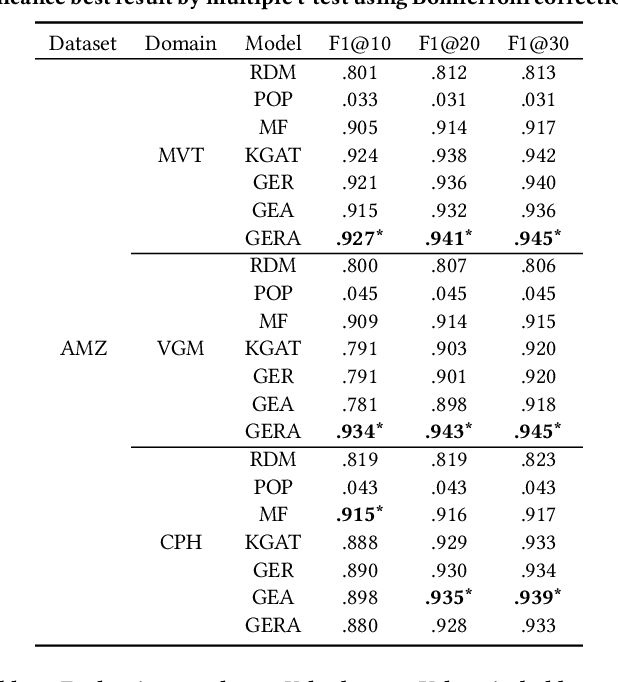
The success of neural network embeddings has entailed a renewed interest in using knowledge graphs for a wide variety of machine learning and information retrieval tasks. In particular, recent recommendation methods based on graph embeddings have shown state-of-the-art performance. In general, these methods encode latent rating patterns and content features. Differently from previous work, in this paper, we propose to exploit embeddings extracted from graphs that combine information from ratings and aspect-based opinions expressed in textual reviews. We then adapt and evaluate state-of-the-art graph embedding techniques over graphs generated from Amazon and Yelp reviews on six domains, outperforming baseline recommenders. Additionally, our method has the advantage of providing explanations that involve the coverage of aspect-based opinions given by users about recommended items.
Graphing else matters: exploiting aspect opinions and ratings in explainable graph-based recommendations
Jul 07, 2021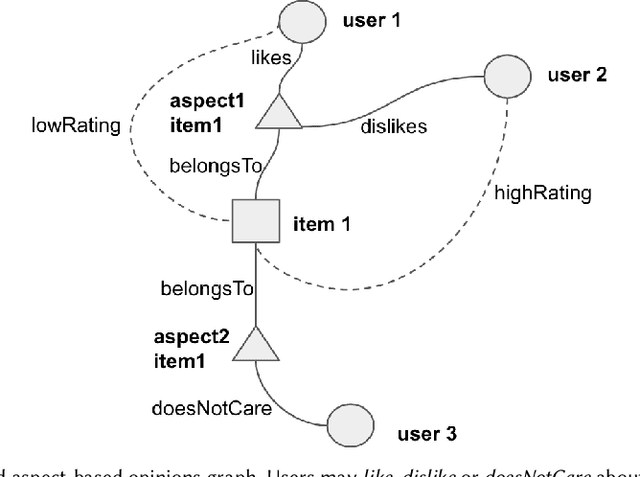

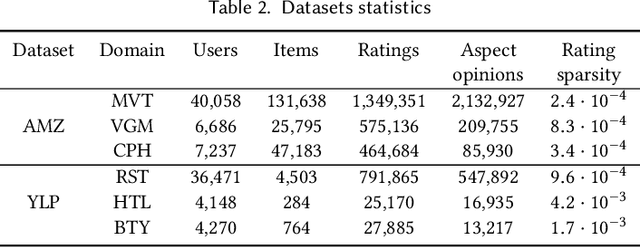
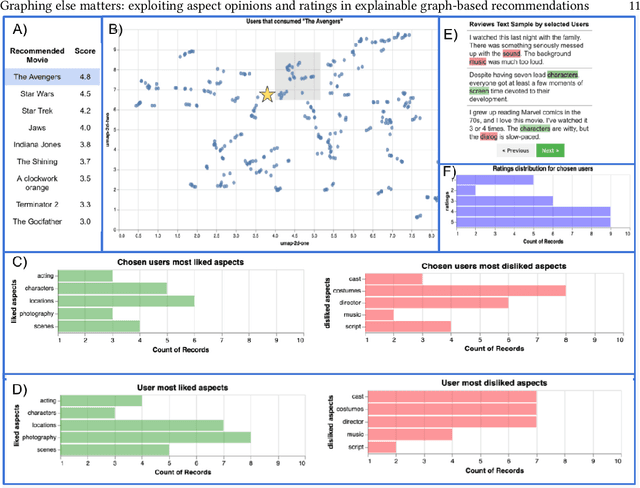
The success of neural network embeddings has entailed a renewed interest in using knowledge graphs for a wide variety of machine learning and information retrieval tasks. In particular, current recommendation methods based on graph embeddings have shown state-of-the-art performance. These methods commonly encode latent rating patterns and content features. Different from previous work, in this paper, we propose to exploit embeddings extracted from graphs that combine information from ratings and aspect-based opinions expressed in textual reviews. We then adapt and evaluate state-of-the-art graph embedding techniques over graphs generated from Amazon and Yelp reviews on six domains, outperforming baseline recommenders. Our approach has the advantage of providing explanations which leverage aspect-based opinions given by users about recommended items. Furthermore, we also provide examples of the applicability of recommendations utilizing aspect opinions as explanations in a visualization dashboard, which allows obtaining information about the most and least liked aspects of similar users obtained from the embeddings of an input graph.
Stress Test Evaluation of Transformer-based Models in Natural Language Understanding Tasks
Feb 14, 2020
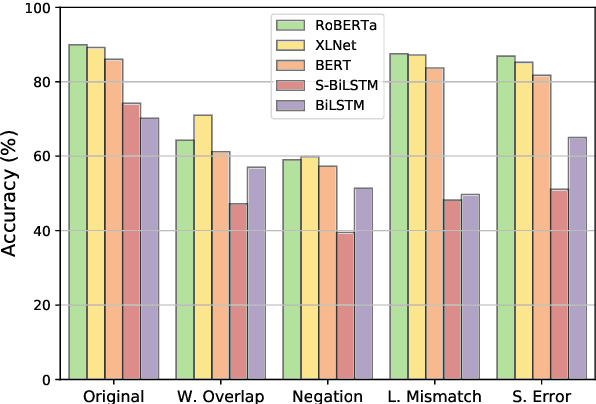
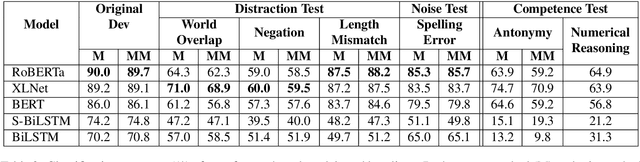
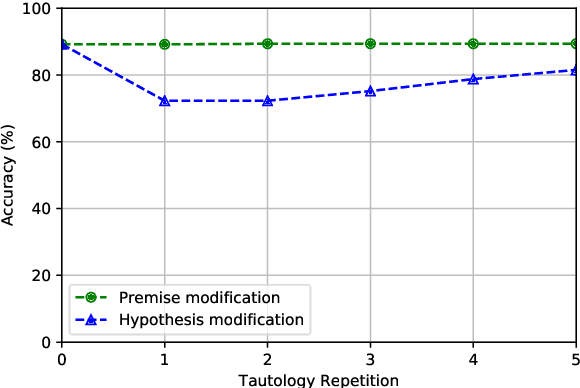
There has been significant progress in recent years in the field of Natural Language Processing thanks to the introduction of the Transformer architecture. Current state-of-the-art models, via a large number of parameters and pre-training on massive text corpus, have shown impressive results on several downstream tasks. Many researchers have studied previous (non-transformer) models to understand their actual behavior under different scenarios, showing that these models are taking advantage of clues or failures of datasets and that slight perturbations on the input data can severely reduce their performance. In contrast, recent models have not been systematically tested with adversarial-examples in order to show their robustness under severe stress conditions. For that reason, this work evaluates three transformer-based models (RoBERTa, XLNet, and BERT) in Natural Language Inference (NLI) and Question Answering (QA) tasks to know if they are more robust or if they have the same flaws as their predecessors. As a result, our experiments reveal that RoBERTa, XLNet and BERT are more robust than recurrent neural network models to stress tests for both NLI and QA tasks. Nevertheless, they are still very fragile and demonstrate various unexpected behaviors, thus revealing that there is still room for future improvement in this field.