 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCOBRA: Catastrophic Bit-flip Reliability Analysis of State-Space Models
Dec 22, 2025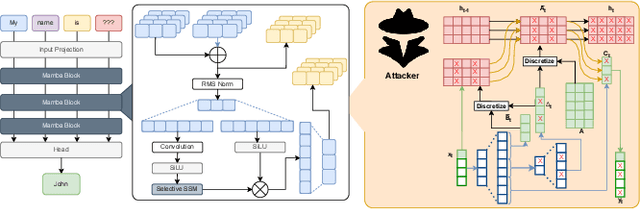
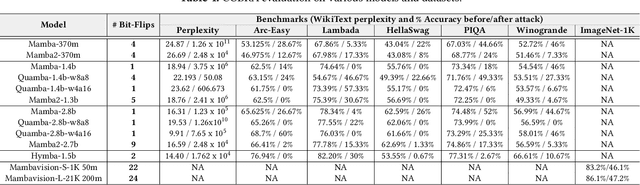
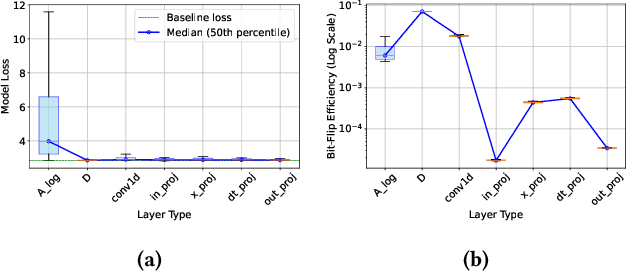
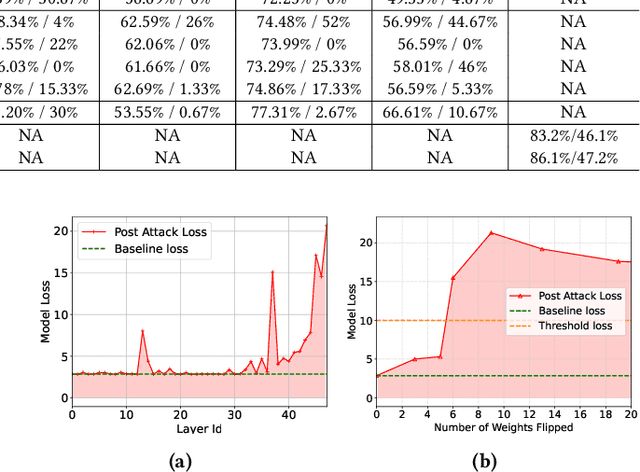
State-space models (SSMs), exemplified by the Mamba architecture, have recently emerged as state-of-the-art sequence-modeling frameworks, offering linear-time scalability together with strong performance in long-context settings. Owing to their unique combination of efficiency, scalability, and expressive capacity, SSMs have become compelling alternatives to transformer-based models, which suffer from the quadratic computational and memory costs of attention mechanisms. As SSMs are increasingly deployed in real-world applications, it is critical to assess their susceptibility to both software- and hardware-level threats to ensure secure and reliable operation. Among such threats, hardware-induced bit-flip attacks (BFAs) pose a particularly severe risk by corrupting model parameters through memory faults, thereby undermining model accuracy and functional integrity. To investigate this vulnerability, we introduce RAMBO, the first BFA framework specifically designed to target Mamba-based architectures. Through experiments on the Mamba-1.4b model with LAMBADA benchmark, a cloze-style word-prediction task, we demonstrate that flipping merely a single critical bit can catastrophically reduce accuracy from 74.64% to 0% and increase perplexity from 18.94 to 3.75 x 10^6. These results demonstrate the pronounced fragility of SSMs to adversarial perturbations.
SkipKV: Selective Skipping of KV Generation and Storage for Efficient Inference with Large Reasoning Models
Dec 08, 2025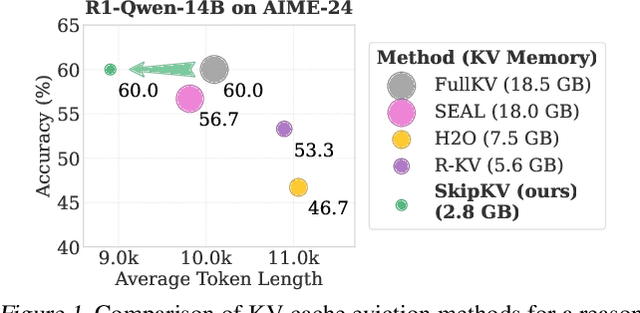
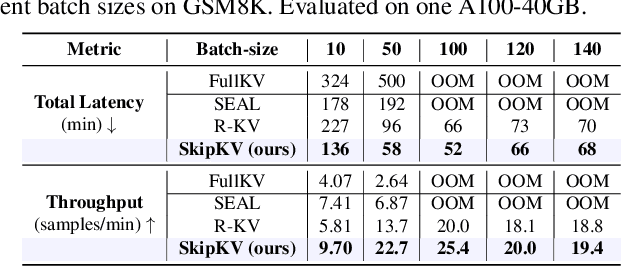
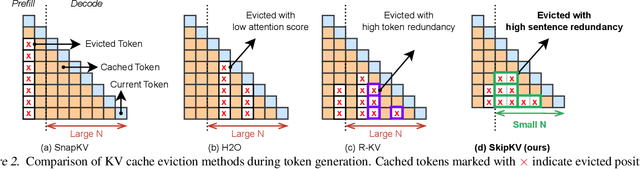
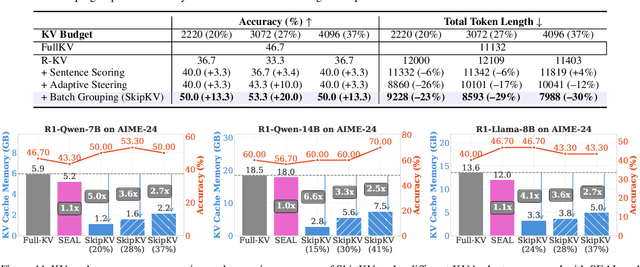
Large reasoning models (LRMs) often cost significant key-value (KV) cache overhead, due to their linear growth with the verbose chain-of-thought (CoT) reasoning process. This costs both memory and throughput bottleneck limiting their efficient deployment. Towards reducing KV cache size during inference, we first investigate the effectiveness of existing KV cache eviction methods for CoT reasoning. Interestingly, we find that due to unstable token-wise scoring and the reduced effective KV budget caused by padding tokens, state-of-the-art (SoTA) eviction methods fail to maintain accuracy in the multi-batch setting. Additionally, these methods often generate longer sequences than the original model, as semantic-unaware token-wise eviction leads to repeated revalidation during reasoning. To address these issues, we present \textbf{SkipKV}, a \textbf{\textit{training-free}} KV compression method for selective \textit{eviction} and \textit{generation} operating at a coarse-grained sentence-level sequence removal for efficient CoT reasoning. In specific, it introduces a \textit{sentence-scoring metric} to identify and remove highly similar sentences while maintaining semantic coherence. To suppress redundant generation, SkipKV dynamically adjusts a steering vector to update the hidden activation states during inference enforcing the LRM to generate concise response. Extensive evaluations on multiple reasoning benchmarks demonstrate the effectiveness of SkipKV in maintaining up to $\mathbf{26.7}\%$ improved accuracy compared to the alternatives, at a similar compression budget. Additionally, compared to SoTA, SkipKV yields up to $\mathbf{1.6}\times$ fewer generation length while improving throughput up to $\mathbf{1.7}\times$.
RedVTP: Training-Free Acceleration of Diffusion Vision-Language Models Inference via Masked Token-Guided Visual Token Pruning
Nov 16, 2025



Vision-Language Models (VLMs) have achieved remarkable progress in multimodal reasoning and generation, yet their high computational demands remain a major challenge. Diffusion Vision-Language Models (DVLMs) are particularly attractive because they enable parallel token decoding, but the large number of visual tokens still significantly hinders their inference efficiency. While visual token pruning has been extensively studied for autoregressive VLMs (AVLMs), it remains largely unexplored for DVLMs. In this work, we propose RedVTP, a response-driven visual token pruning strategy that leverages the inference dynamics of DVLMs. Our method estimates visual token importance using attention from the masked response tokens. Based on the observation that these importance scores remain consistent across steps, RedVTP prunes the less important visual tokens from the masked tokens after the first inference step, thereby maximizing inference efficiency. Experiments show that RedVTP improves token generation throughput of LLaDA-V and LaViDa by up to 186% and 28.05%, respectively, and reduces inference latency by up to 64.97% and 21.87%, without compromising-and in some cases improving-accuracy.
On-the-Fly Adaptive Distillation of Transformer to Dual-State Linear Attention
Jun 12, 2025Large language models (LLMs) excel at capturing global token dependencies via self-attention but face prohibitive compute and memory costs on lengthy inputs. While sub-quadratic methods (e.g., linear attention) can reduce these costs, they often degrade accuracy due to overemphasizing recent tokens. In this work, we first propose dual-state linear attention (DSLA), a novel design that maintains two specialized hidden states-one for preserving historical context and one for tracking recency-thereby mitigating the short-range bias typical of linear-attention architectures. To further balance efficiency and accuracy under dynamic workload conditions, we introduce DSLA-Serve, an online adaptive distillation framework that progressively replaces Transformer layers with DSLA layers at inference time, guided by a sensitivity-based layer ordering. DSLA-Serve uses a chained fine-tuning strategy to ensure that each newly converted DSLA layer remains consistent with previously replaced layers, preserving the overall quality. Extensive evaluations on commonsense reasoning, long-context QA, and text summarization demonstrate that DSLA-Serve yields 2.3x faster inference than Llama2-7B and 3.0x faster than the hybrid Zamba-7B, while retaining comparable performance across downstream tasks. Our ablation studies show that DSLA's dual states capture both global and local dependencies, addressing the historical-token underrepresentation seen in prior linear attentions. Codes are available at https://github.com/utnslab/DSLA-Serve.
Fast and Cost-effective Speculative Edge-Cloud Decoding with Early Exits
May 27, 2025Large Language Models (LLMs) enable various applications on edge devices such as smartphones, wearables, and embodied robots. However, their deployment often depends on expensive cloud-based APIs, creating high operational costs, which limit access for smaller organizations and raise sustainability concerns. Certain LLMs can be deployed on-device, offering a cost-effective solution with reduced latency and improved privacy. Yet, limited computing resources constrain the size and accuracy of models that can be deployed, necessitating a collaborative design between edge and cloud. We propose a fast and cost-effective speculative edge-cloud decoding framework with a large target model on the server and a small draft model on the device. By introducing early exits in the target model, tokens are generated mid-verification, allowing the client to preemptively draft subsequent tokens before final verification, thus utilizing idle time and enhancing parallelism between edge and cloud. Using an NVIDIA Jetson Nano (client) and an A100 GPU (server) with Vicuna-68M (draft) and Llama2-7B (target) models, our method achieves up to a 35% reduction in latency compared to cloud-based autoregressive decoding, with an additional 11% improvement from preemptive drafting. To demonstrate real-world applicability, we deploy our method on the Unitree Go2 quadruped robot using Vision-Language Model (VLM) based control, achieving a 21% speedup over traditional cloud-based autoregressive decoding. These results demonstrate the potential of our framework for real-time LLM and VLM applications on resource-constrained edge devices.
Mitigating Hallucinations in Vision-Language Models through Image-Guided Head Suppression
May 22, 2025Despite their remarkable progress in multimodal understanding tasks, large vision language models (LVLMs) often suffer from "hallucinations", generating texts misaligned with the visual context. Existing methods aimed at reducing hallucinations through inference time intervention incur a significant increase in latency. To mitigate this, we present SPIN, a task-agnostic attention-guided head suppression strategy that can be seamlessly integrated during inference, without incurring any significant compute or latency overhead. We investigate whether hallucination in LVLMs can be linked to specific model components. Our analysis suggests that hallucinations can be attributed to a dynamic subset of attention heads in each layer. Leveraging this insight, for each text query token, we selectively suppress attention heads that exhibit low attention to image tokens, keeping the top-K attention heads intact. Extensive evaluations on visual question answering and image description tasks demonstrate the efficacy of SPIN in reducing hallucination scores up to 2.7x while maintaining F1, and improving throughput by 1.8x compared to existing alternatives. Code is available at https://github.com/YUECHE77/SPIN.
Accelerating LLM Inference with Flexible N:M Sparsity via A Fully Digital Compute-in-Memory Accelerator
Apr 19, 2025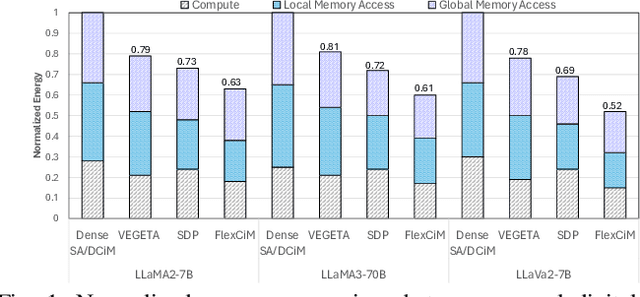
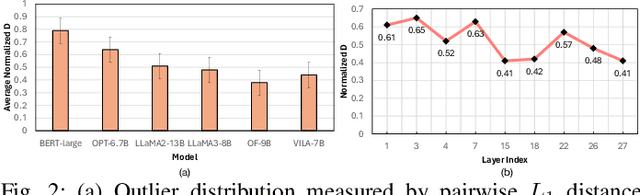
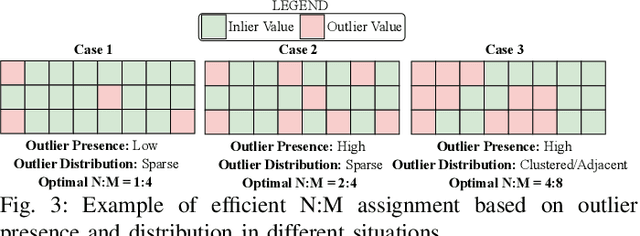
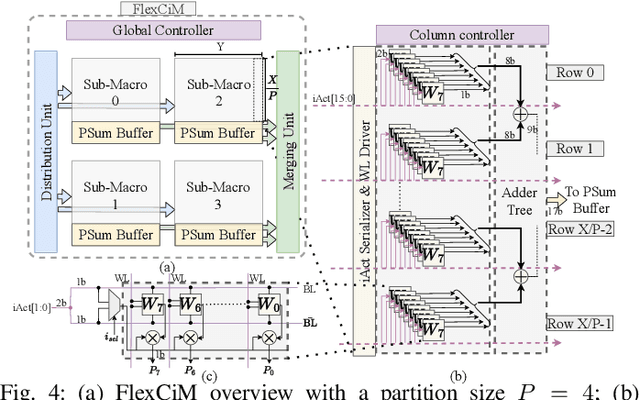
Large language model (LLM) pruning with fixed N:M structured sparsity significantly limits the expressivity of the sparse model, yielding sub-optimal performance. In contrast, supporting multiple N:M patterns to provide sparse representational freedom introduces costly overhead in hardware. To address these challenges for LLMs, we first present a flexible layer-wise outlier-density-aware N:M sparsity (FLOW) selection method. FLOW enables the identification of optimal layer-wise N and M values (from a given range) by simultaneously accounting for the presence and distribution of outliers, allowing a higher degree of representational freedom. To deploy sparse models with such N:M flexibility, we then introduce a flexible, low-overhead digital compute-in-memory architecture (FlexCiM). FlexCiM supports diverse sparsity patterns by partitioning a digital CiM (DCiM) macro into smaller sub-macros, which are adaptively aggregated and disaggregated through distribution and merging mechanisms for different N and M values. Extensive experiments on both transformer-based and recurrence-based state space foundation models (SSMs) demonstrate that FLOW outperforms existing alternatives with an accuracy improvement of up to 36%, while FlexCiM achieves up to 1.75x lower inference latency and 1.5x lower energy consumption compared to existing sparse accelerators. Code is available at: https://github.com/FLOW-open-project/FLOW
Understanding and Optimizing Multi-Stage AI Inference Pipelines
Apr 16, 2025The rapid evolution of Large Language Models (LLMs) has driven the need for increasingly sophisticated inference pipelines and hardware platforms. Modern LLM serving extends beyond traditional prefill-decode workflows, incorporating multi-stage processes such as Retrieval Augmented Generation (RAG), key-value (KV) cache retrieval, dynamic model routing, and multi step reasoning. These stages exhibit diverse computational demands, requiring distributed systems that integrate GPUs, ASICs, CPUs, and memory-centric architectures. However, existing simulators lack the fidelity to model these heterogeneous, multi-engine workflows, limiting their ability to inform architectural decisions. To address this gap, we introduce HERMES, a Heterogeneous Multi-stage LLM inference Execution Simulator. HERMES models diverse request stages; including RAG, KV retrieval, reasoning, prefill, and decode across complex hardware hierarchies. HERMES supports heterogeneous clients executing multiple models concurrently unlike prior frameworks while incorporating advanced batching strategies and multi-level memory hierarchies. By integrating real hardware traces with analytical modeling, HERMES captures critical trade-offs such as memory bandwidth contention, inter-cluster communication latency, and batching efficiency in hybrid CPU-accelerator deployments. Through case studies, we explore the impact of reasoning stages on end-to-end latency, optimal batching strategies for hybrid pipelines, and the architectural implications of remote KV cache retrieval. HERMES empowers system designers to navigate the evolving landscape of LLM inference, providing actionable insights into optimizing hardware-software co-design for next-generation AI workloads.
OuroMamba: A Data-Free Quantization Framework for Vision Mamba Models
Mar 13, 2025We present OuroMamba, the first data-free post-training quantization (DFQ) method for vision Mamba-based models (VMMs). We identify two key challenges in enabling DFQ for VMMs, (1) VMM's recurrent state transitions restricts capturing of long-range interactions and leads to semantically weak synthetic data, (2) VMM activations exhibit dynamic outlier variations across time-steps, rendering existing static PTQ techniques ineffective. To address these challenges, OuroMamba presents a two-stage framework: (1) OuroMamba-Gen to generate semantically rich and meaningful synthetic data. It applies contrastive learning on patch level VMM features generated through neighborhood interactions in the latent state space, (2) OuroMamba-Quant to employ mixed-precision quantization with lightweight dynamic outlier detection during inference. In specific, we present a thresholding based outlier channel selection strategy for activations that gets updated every time-step. Extensive experiments across vision and generative tasks show that our data-free OuroMamba surpasses existing data-driven PTQ techniques, achieving state-of-the-art performance across diverse quantization settings. Additionally, we implement efficient GPU kernels to achieve practical latency speedup of up to 2.36x. Code will be released soon.
Enhancing Large Language Models for Hardware Verification: A Novel SystemVerilog Assertion Dataset
Mar 11, 2025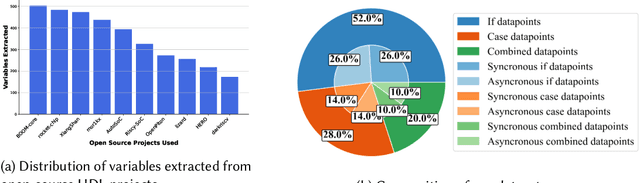
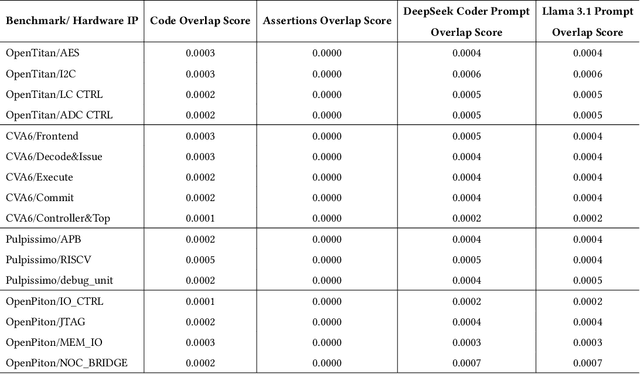
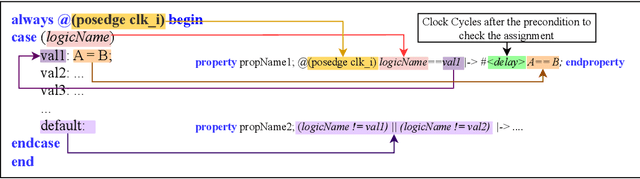
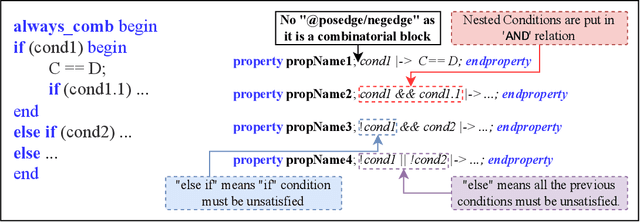
Hardware verification is crucial in modern SoC design, consuming around 70% of development time. SystemVerilog assertions ensure correct functionality. However, existing industrial practices rely on manual efforts for assertion generation, which becomes increasingly untenable as hardware systems become complex. Recent research shows that Large Language Models (LLMs) can automate this process. However, proprietary SOTA models like GPT-4o often generate inaccurate assertions and require expensive licenses, while smaller open-source LLMs need fine-tuning to manage HDL code complexities. To address these issues, we introduce **VERT**, an open-source dataset designed to enhance SystemVerilog assertion generation using LLMs. VERT enables researchers in academia and industry to fine-tune open-source models, outperforming larger proprietary ones in both accuracy and efficiency while ensuring data privacy through local fine-tuning and eliminating costly licenses. The dataset is curated by systematically augmenting variables from open-source HDL repositories to generate synthetic code snippets paired with corresponding assertions. Experimental results demonstrate that fine-tuned models like Deepseek Coder 6.7B and Llama 3.1 8B outperform GPT-4o, achieving up to 96.88% improvement over base models and 24.14% over GPT-4o on platforms including OpenTitan, CVA6, OpenPiton and Pulpissimo. VERT is available at https://github.com/AnandMenon12/VERT.