 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReRAM-aware Model Finetuning addressing I-V Non-linearity and Retention Errors
Jun 16, 2026Traditional CPU, GPU, and NPU architectures are increasingly limited by the von Neumann bottleneck. While In-Memory Computing (IMC) using ReRAM crossbar arrays offers a high-density, energy-efficient alternative, its practical deployment is constrained through their non-idealities. Existing hardware-aware training frameworks often require training from scratch, which is computationally prohibitive for modern large-scale models. In this work, we propose a finetuning-based hardware-aware training algorithm that enables robust DNN deployment on ReRAM with minimal training overhead. Our approach mitigates I-V non-linearity by applying a range-shrunk sinh transformation and incorporates retention errors directly into a regularization loss during the finetuning process. We evaluate our framework across models and tasks such as image classification and question-answering (QA). Experimental results demonstrate that our method achieves similar accuracy on large-scale models like ResNet18 and DeiT-Tiny as the base model. In-case of ImageNet for MobileNetV3 families the technique has only less than 2% accuracy degradation. Further, applying the technique on the SQuAD v2 dataset results in only 1 point degradation of F-1 score.
COBRA: Catastrophic Bit-flip Reliability Analysis of State-Space Models
Dec 22, 2025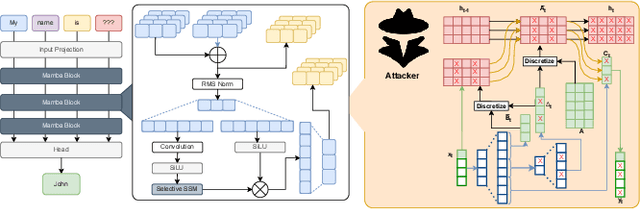
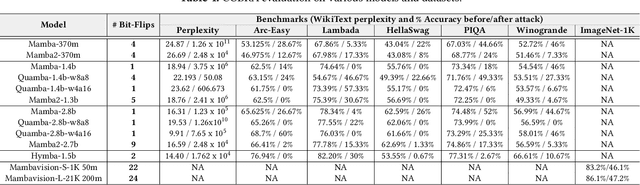
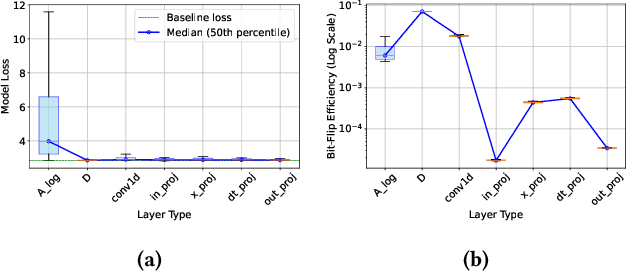
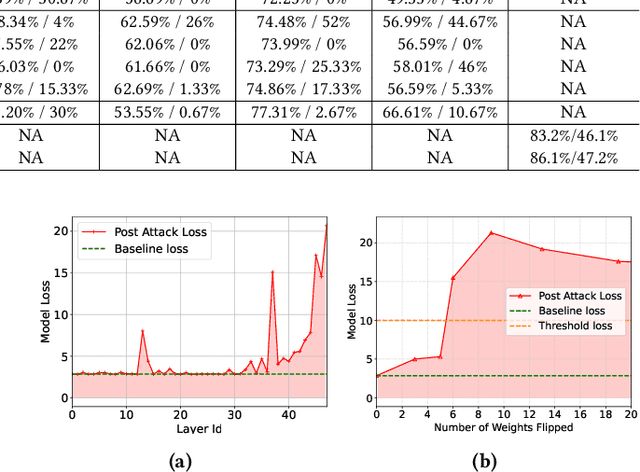
State-space models (SSMs), exemplified by the Mamba architecture, have recently emerged as state-of-the-art sequence-modeling frameworks, offering linear-time scalability together with strong performance in long-context settings. Owing to their unique combination of efficiency, scalability, and expressive capacity, SSMs have become compelling alternatives to transformer-based models, which suffer from the quadratic computational and memory costs of attention mechanisms. As SSMs are increasingly deployed in real-world applications, it is critical to assess their susceptibility to both software- and hardware-level threats to ensure secure and reliable operation. Among such threats, hardware-induced bit-flip attacks (BFAs) pose a particularly severe risk by corrupting model parameters through memory faults, thereby undermining model accuracy and functional integrity. To investigate this vulnerability, we introduce RAMBO, the first BFA framework specifically designed to target Mamba-based architectures. Through experiments on the Mamba-1.4b model with LAMBADA benchmark, a cloze-style word-prediction task, we demonstrate that flipping merely a single critical bit can catastrophically reduce accuracy from 74.64% to 0% and increase perplexity from 18.94 to 3.75 x 10^6. These results demonstrate the pronounced fragility of SSMs to adversarial perturbations.
Accelerating LLM Inference with Flexible N:M Sparsity via A Fully Digital Compute-in-Memory Accelerator
Apr 19, 2025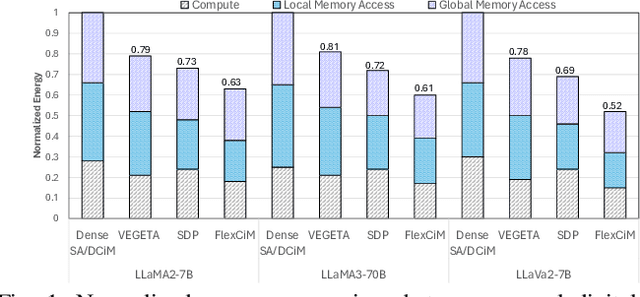
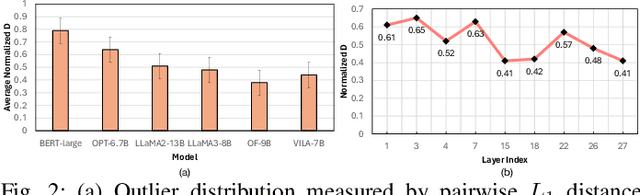
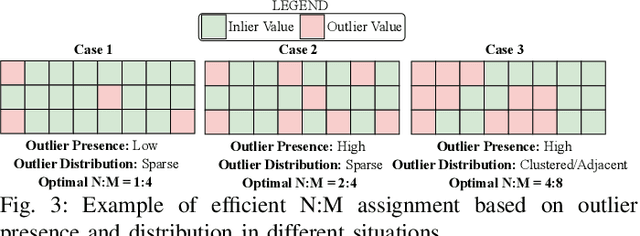
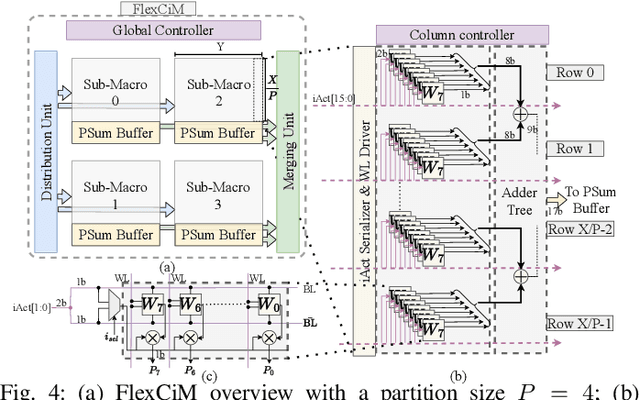
Large language model (LLM) pruning with fixed N:M structured sparsity significantly limits the expressivity of the sparse model, yielding sub-optimal performance. In contrast, supporting multiple N:M patterns to provide sparse representational freedom introduces costly overhead in hardware. To address these challenges for LLMs, we first present a flexible layer-wise outlier-density-aware N:M sparsity (FLOW) selection method. FLOW enables the identification of optimal layer-wise N and M values (from a given range) by simultaneously accounting for the presence and distribution of outliers, allowing a higher degree of representational freedom. To deploy sparse models with such N:M flexibility, we then introduce a flexible, low-overhead digital compute-in-memory architecture (FlexCiM). FlexCiM supports diverse sparsity patterns by partitioning a digital CiM (DCiM) macro into smaller sub-macros, which are adaptively aggregated and disaggregated through distribution and merging mechanisms for different N and M values. Extensive experiments on both transformer-based and recurrence-based state space foundation models (SSMs) demonstrate that FLOW outperforms existing alternatives with an accuracy improvement of up to 36%, while FlexCiM achieves up to 1.75x lower inference latency and 1.5x lower energy consumption compared to existing sparse accelerators. Code is available at: https://github.com/FLOW-open-project/FLOW
Enhancing Large Language Models for Hardware Verification: A Novel SystemVerilog Assertion Dataset
Mar 11, 2025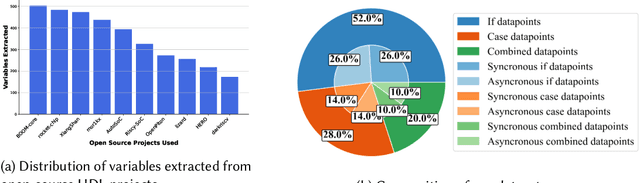
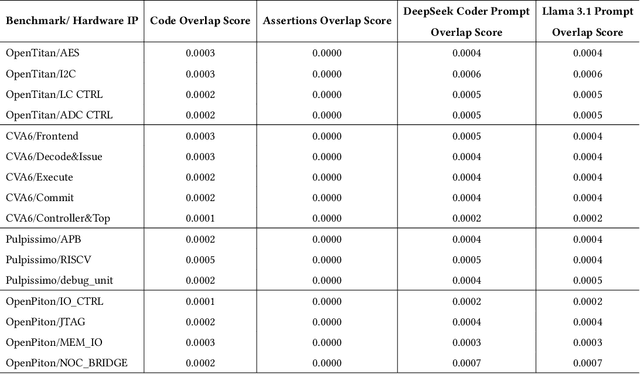
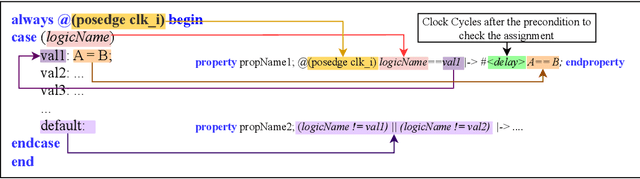
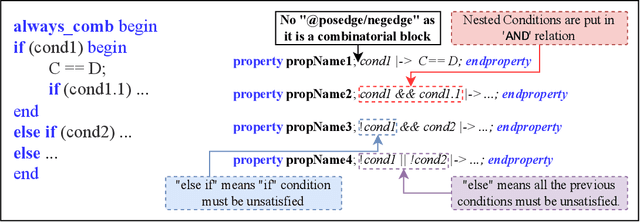
Hardware verification is crucial in modern SoC design, consuming around 70% of development time. SystemVerilog assertions ensure correct functionality. However, existing industrial practices rely on manual efforts for assertion generation, which becomes increasingly untenable as hardware systems become complex. Recent research shows that Large Language Models (LLMs) can automate this process. However, proprietary SOTA models like GPT-4o often generate inaccurate assertions and require expensive licenses, while smaller open-source LLMs need fine-tuning to manage HDL code complexities. To address these issues, we introduce **VERT**, an open-source dataset designed to enhance SystemVerilog assertion generation using LLMs. VERT enables researchers in academia and industry to fine-tune open-source models, outperforming larger proprietary ones in both accuracy and efficiency while ensuring data privacy through local fine-tuning and eliminating costly licenses. The dataset is curated by systematically augmenting variables from open-source HDL repositories to generate synthetic code snippets paired with corresponding assertions. Experimental results demonstrate that fine-tuned models like Deepseek Coder 6.7B and Llama 3.1 8B outperform GPT-4o, achieving up to 96.88% improvement over base models and 24.14% over GPT-4o on platforms including OpenTitan, CVA6, OpenPiton and Pulpissimo. VERT is available at https://github.com/AnandMenon12/VERT.
XAMBA: Enabling Efficient State Space Models on Resource-Constrained Neural Processing Units
Feb 10, 2025State-Space Models (SSMs) have emerged as efficient alternatives to transformers for sequential data tasks, offering linear or near-linear scalability with sequence length, making them ideal for long-sequence applications in NLP, vision, and edge AI, including real-time transcription, translation, and contextual search. These applications require lightweight, high-performance models for deployment on resource-constrained devices like laptops and PCs. Designing specialized accelerators for every emerging neural network is costly and impractical; instead, optimizing models for existing NPUs in AI PCs provides a scalable solution. To this end, we propose XAMBA, the first framework to enable and optimize SSMs on commercial off-the-shelf (COTS) state-of-the-art (SOTA) NPUs. XAMBA follows a three-step methodology: (1) enabling SSMs on NPUs, (2) optimizing performance to meet KPI requirements, and (3) trading accuracy for additional performance gains. After enabling SSMs on NPUs, XAMBA mitigates key bottlenecks using CumBA and ReduBA, replacing sequential CumSum and ReduceSum operations with matrix-based computations, significantly improving execution speed and memory efficiency. Additionally, ActiBA enhances performance by approximating expensive activation functions (e.g., Swish, Softplus) using piecewise linear mappings, reducing latency with minimal accuracy loss. Evaluations on an Intel Core Ultra Series 2 AI PC show that XAMBA achieves up to 2.6X speed-up over the baseline. Our implementation is available at https://github.com/arghadippurdue/XAMBA.
GraNNite: Enabling High-Performance Execution of Graph Neural Networks on Resource-Constrained Neural Processing Units
Feb 10, 2025

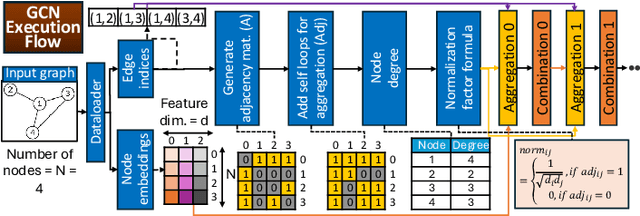

Graph Neural Networks (GNNs) are vital for learning from graph-structured data, enabling applications in network analysis, recommendation systems, and speech analytics. Deploying them on edge devices like client PCs and laptops enhances real-time processing, privacy, and cloud independence. GNNs aid Retrieval-Augmented Generation (RAG) for Large Language Models (LLMs) and enable event-based vision tasks. However, irregular memory access, sparsity, and dynamic structures cause high latency and energy overhead on resource-constrained devices. While modern edge processors integrate CPUs, GPUs, and NPUs, NPUs designed for data-parallel tasks struggle with irregular GNN computations. We introduce GraNNite, the first hardware-aware framework optimizing GNN execution on commercial-off-the-shelf (COTS) SOTA DNN accelerators via a structured three-step methodology: (1) enabling NPU execution, (2) optimizing performance, and (3) trading accuracy for efficiency gains. Step 1 employs GraphSplit for workload distribution and StaGr for static aggregation, while GrAd and NodePad handle dynamic graphs. Step 2 boosts performance using EffOp for control-heavy tasks and GraSp for sparsity exploitation. Graph Convolution optimizations PreG, SymG, and CacheG reduce redundancy and memory transfers. Step 3 balances quality versus efficiency, where QuantGr applies INT8 quantization, and GrAx1, GrAx2, and GrAx3 accelerate attention, broadcast-add, and SAGE-max aggregation. On Intel Core Ultra AI PCs, GraNNite achieves 2.6X to 7.6X speedups over default NPU mappings and up to 8.6X energy gains over CPUs and GPUs, delivering 10.8X and 6.7X higher performance than CPUs and GPUs, respectively, across GNN models.
AttentionBreaker: Adaptive Evolutionary Optimization for Unmasking Vulnerabilities in LLMs through Bit-Flip Attacks
Nov 21, 2024



Large Language Models (LLMs) have revolutionized natural language processing (NLP), excelling in tasks like text generation and summarization. However, their increasing adoption in mission-critical applications raises concerns about hardware-based threats, particularly bit-flip attacks (BFAs). BFAs, enabled by fault injection methods such as Rowhammer, target model parameters in memory, compromising both integrity and performance. Identifying critical parameters for BFAs in the vast parameter space of LLMs poses significant challenges. While prior research suggests transformer-based architectures are inherently more robust to BFAs compared to traditional deep neural networks, we challenge this assumption. For the first time, we demonstrate that as few as three bit-flips can cause catastrophic performance degradation in an LLM with billions of parameters. Current BFA techniques are inadequate for exploiting this vulnerability due to the difficulty of efficiently identifying critical parameters within the immense parameter space. To address this, we propose AttentionBreaker, a novel framework tailored for LLMs that enables efficient traversal of the parameter space to identify critical parameters. Additionally, we introduce GenBFA, an evolutionary optimization strategy designed to refine the search further, isolating the most critical bits for an efficient and effective attack. Empirical results reveal the profound vulnerability of LLMs to AttentionBreaker. For example, merely three bit-flips (4.129 x 10^-9% of total parameters) in the LLaMA3-8B-Instruct 8-bit quantized (W8) model result in a complete performance collapse: accuracy on MMLU tasks drops from 67.3% to 0%, and Wikitext perplexity skyrockets from 12.6 to 4.72 x 10^5. These findings underscore the effectiveness of AttentionBreaker in uncovering and exploiting critical vulnerabilities within LLM architectures.
FlexNN: A Dataflow-aware Flexible Deep Learning Accelerator for Energy-Efficient Edge Devices
Mar 14, 2024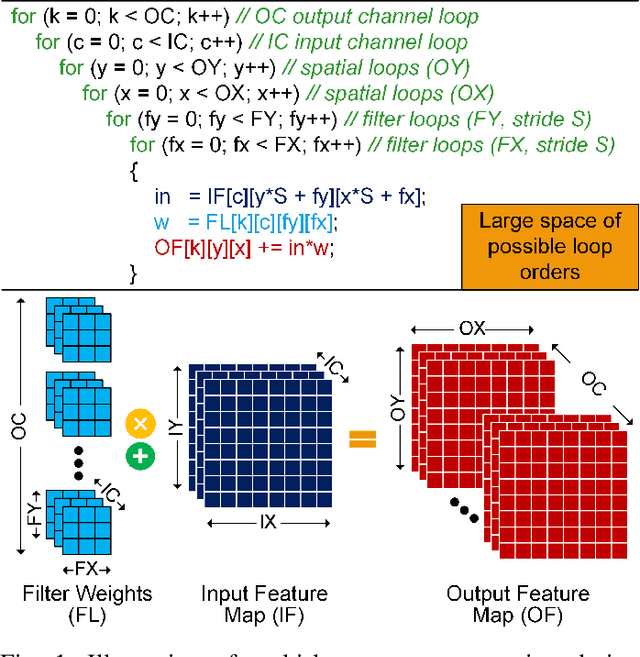
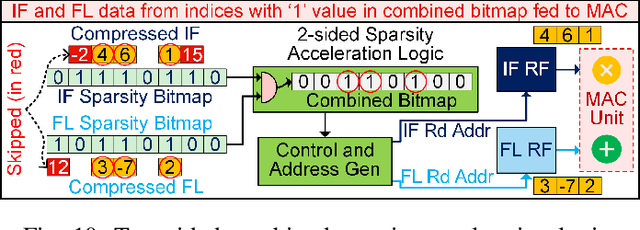
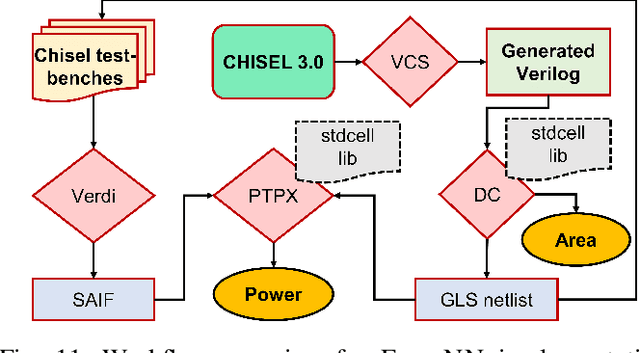
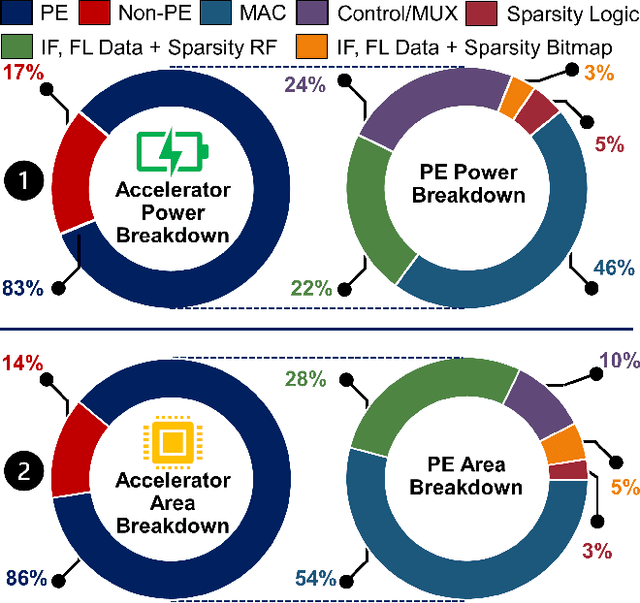
This paper introduces FlexNN, a Flexible Neural Network accelerator, which adopts agile design principles to enable versatile dataflows, enhancing energy efficiency. Unlike conventional convolutional neural network accelerator architectures that adhere to fixed dataflows (such as input, weight, output, or row stationary) for transferring activations and weights between storage and compute units, our design revolutionizes by enabling adaptable dataflows of any type through software configurable descriptors. Considering that data movement costs considerably outweigh compute costs from an energy perspective, the flexibility in dataflow allows us to optimize the movement per layer for minimal data transfer and energy consumption, a capability unattainable in fixed dataflow architectures. To further enhance throughput and reduce energy consumption in the FlexNN architecture, we propose a novel sparsity-based acceleration logic that utilizes fine-grained sparsity in both the activation and weight tensors to bypass redundant computations, thus optimizing the convolution engine within the hardware accelerator. Extensive experimental results underscore a significant enhancement in the performance and energy efficiency of FlexNN relative to existing DNN accelerators.
High-level Modeling of Manufacturing Faults in Deep Neural Network Accelerators
Jun 05, 2020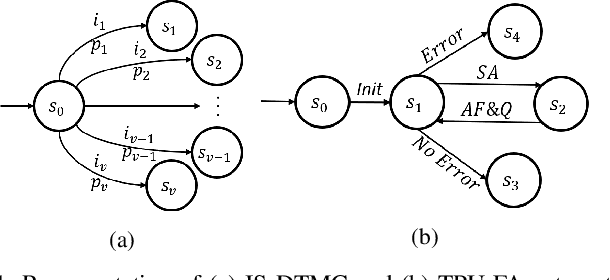
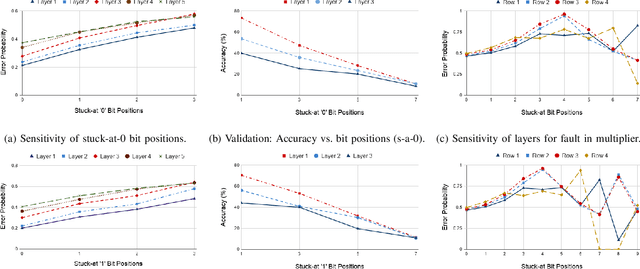
The advent of data-driven real-time applications requires the implementation of Deep Neural Networks (DNNs) on Machine Learning accelerators. Google's Tensor Processing Unit (TPU) is one such neural network accelerator that uses systolic array-based matrix multiplication hardware for computation in its crux. Manufacturing faults at any state element of the matrix multiplication unit can cause unexpected errors in these inference networks. In this paper, we propose a formal model of permanent faults and their propagation in a TPU using the Discrete-Time Markov Chain (DTMC) formalism. The proposed model is analyzed using the probabilistic model checking technique to reason about the likelihood of faulty outputs. The obtained quantitative results show that the classification accuracy is sensitive to the type of permanent faults as well as their location, bit position and the number of layers in the neural network. The conclusions from our theoretical model have been validated using experiments on a digit recognition-based DNN.