 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Large Language Models for Hardware Verification: A Novel SystemVerilog Assertion Dataset
Mar 11, 2025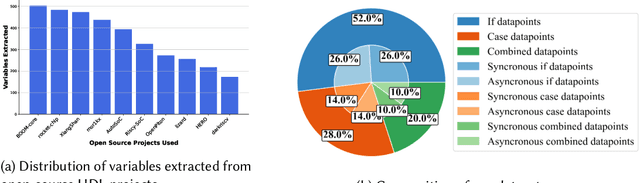
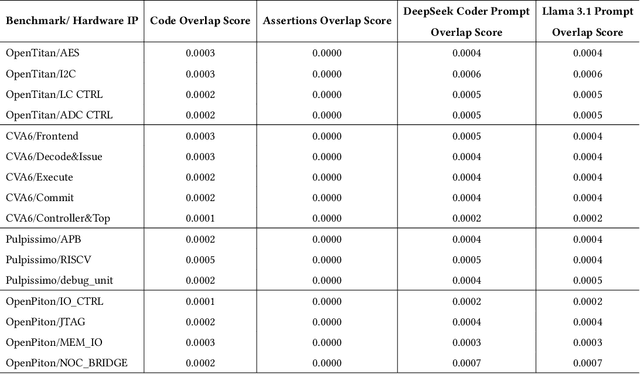
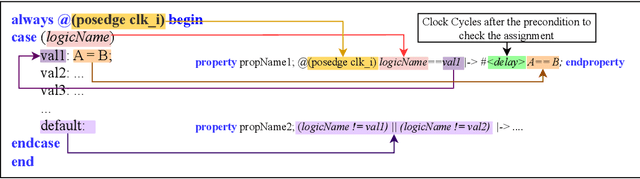
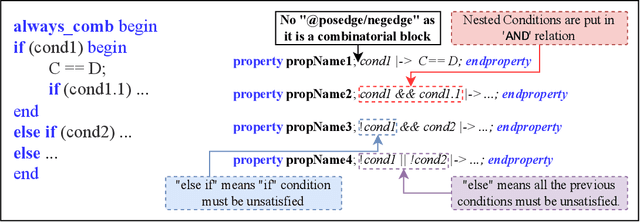
Hardware verification is crucial in modern SoC design, consuming around 70% of development time. SystemVerilog assertions ensure correct functionality. However, existing industrial practices rely on manual efforts for assertion generation, which becomes increasingly untenable as hardware systems become complex. Recent research shows that Large Language Models (LLMs) can automate this process. However, proprietary SOTA models like GPT-4o often generate inaccurate assertions and require expensive licenses, while smaller open-source LLMs need fine-tuning to manage HDL code complexities. To address these issues, we introduce **VERT**, an open-source dataset designed to enhance SystemVerilog assertion generation using LLMs. VERT enables researchers in academia and industry to fine-tune open-source models, outperforming larger proprietary ones in both accuracy and efficiency while ensuring data privacy through local fine-tuning and eliminating costly licenses. The dataset is curated by systematically augmenting variables from open-source HDL repositories to generate synthetic code snippets paired with corresponding assertions. Experimental results demonstrate that fine-tuned models like Deepseek Coder 6.7B and Llama 3.1 8B outperform GPT-4o, achieving up to 96.88% improvement over base models and 24.14% over GPT-4o on platforms including OpenTitan, CVA6, OpenPiton and Pulpissimo. VERT is available at https://github.com/AnandMenon12/VERT.
AttentionBreaker: Adaptive Evolutionary Optimization for Unmasking Vulnerabilities in LLMs through Bit-Flip Attacks
Nov 21, 2024



Large Language Models (LLMs) have revolutionized natural language processing (NLP), excelling in tasks like text generation and summarization. However, their increasing adoption in mission-critical applications raises concerns about hardware-based threats, particularly bit-flip attacks (BFAs). BFAs, enabled by fault injection methods such as Rowhammer, target model parameters in memory, compromising both integrity and performance. Identifying critical parameters for BFAs in the vast parameter space of LLMs poses significant challenges. While prior research suggests transformer-based architectures are inherently more robust to BFAs compared to traditional deep neural networks, we challenge this assumption. For the first time, we demonstrate that as few as three bit-flips can cause catastrophic performance degradation in an LLM with billions of parameters. Current BFA techniques are inadequate for exploiting this vulnerability due to the difficulty of efficiently identifying critical parameters within the immense parameter space. To address this, we propose AttentionBreaker, a novel framework tailored for LLMs that enables efficient traversal of the parameter space to identify critical parameters. Additionally, we introduce GenBFA, an evolutionary optimization strategy designed to refine the search further, isolating the most critical bits for an efficient and effective attack. Empirical results reveal the profound vulnerability of LLMs to AttentionBreaker. For example, merely three bit-flips (4.129 x 10^-9% of total parameters) in the LLaMA3-8B-Instruct 8-bit quantized (W8) model result in a complete performance collapse: accuracy on MMLU tasks drops from 67.3% to 0%, and Wikitext perplexity skyrockets from 12.6 to 4.72 x 10^5. These findings underscore the effectiveness of AttentionBreaker in uncovering and exploiting critical vulnerabilities within LLM architectures.